 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmental Attention Decoding With Long Form Acoustic Encodings
Dec 16, 2025

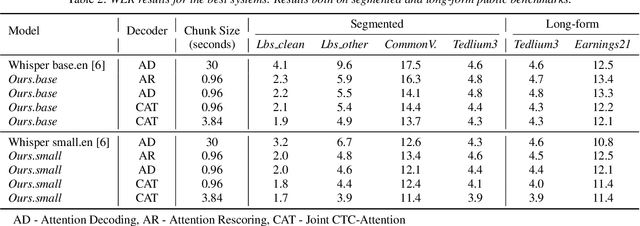
We address the fundamental incompatibility of attention-based encoder-decoder (AED) models with long-form acoustic encodings. AED models trained on segmented utterances learn to encode absolute frame positions by exploiting limited acoustic context beyond segment boundaries, but fail to generalize when decoding long-form segments where these cues vanish. The model loses ability to order acoustic encodings due to permutation invariance of keys and values in cross-attention. We propose four modifications: (1) injecting explicit absolute positional encodings into cross-attention for each decoded segment, (2) long-form training with extended acoustic context to eliminate implicit absolute position encoding, (3) segment concatenation to cover diverse segmentations needed during training, and (4) semantic segmentation to align AED-decoded segments with training segments. We show these modifications close the accuracy gap between continuous and segmented acoustic encodings, enabling auto-regressive use of the attention decoder.
Delayed Fusion: Integrating Large Language Models into First-Pass Decoding in End-to-end Speech Recognition
Jan 16, 2025

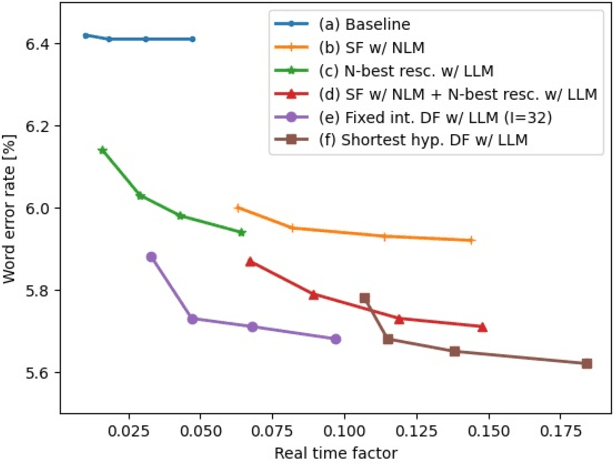

This paper presents an efficient decoding approach for end-to-end automatic speech recognition (E2E-ASR) with large language models (LLMs). Although shallow fusion is the most common approach to incorporate language models into E2E-ASR decoding, we face two practical problems with LLMs. (1) LLM inference is computationally costly. (2) There may be a vocabulary mismatch between the ASR model and the LLM. To resolve this mismatch, we need to retrain the ASR model and/or the LLM, which is at best time-consuming and in many cases not feasible. We propose "delayed fusion," which applies LLM scores to ASR hypotheses with a delay during decoding and enables easier use of pre-trained LLMs in ASR tasks. This method can reduce not only the number of hypotheses scored by the LLM but also the number of LLM inference calls. It also allows re-tokenizion of ASR hypotheses during decoding if ASR and LLM employ different tokenizations. We demonstrate that delayed fusion provides improved decoding speed and accuracy compared to shallow fusion and N-best rescoring using the LibriHeavy ASR corpus and three public LLMs, OpenLLaMA 3B & 7B and Mistral 7B.
Optimizing Contextual Speech Recognition Using Vector Quantization for Efficient Retrieval
Nov 04, 2024Neural contextual biasing allows speech recognition models to leverage contextually relevant information, leading to improved transcription accuracy. However, the biasing mechanism is typically based on a cross-attention module between the audio and a catalogue of biasing entries, which means computational complexity can pose severe practical limitations on the size of the biasing catalogue and consequently on accuracy improvements. This work proposes an approximation to cross-attention scoring based on vector quantization and enables compute- and memory-efficient use of large biasing catalogues. We propose to use this technique jointly with a retrieval based contextual biasing approach. First, we use an efficient quantized retrieval module to shortlist biasing entries by grounding them on audio. Then we use retrieved entries for biasing. Since the proposed approach is agnostic to the biasing method, we investigate using full cross-attention, LLM prompting, and a combination of the two. We show that retrieval based shortlisting allows the system to efficiently leverage biasing catalogues of several thousands of entries, resulting in up to 71% relative error rate reduction in personal entity recognition. At the same time, the proposed approximation algorithm reduces compute time by 20% and memory usage by 85-95%, for lists of up to one million entries, when compared to standard dot-product cross-attention.
End-to-End Speech Recognition: A Survey
Mar 03, 2023



In the last decade of automatic speech recognition (ASR) research, the introduction of deep learning brought considerable reductions in word error rate of more than 50% relative, compared to modeling without deep learning. In the wake of this transition, a number of all-neural ASR architectures were introduced. These so-called end-to-end (E2E) models provide highly integrated, completely neural ASR models, which rely strongly on general machine learning knowledge, learn more consistently from data, while depending less on ASR domain-specific experience. The success and enthusiastic adoption of deep learning accompanied by more generic model architectures lead to E2E models now becoming the prominent ASR approach. The goal of this survey is to provide a taxonomy of E2E ASR models and corresponding improvements, and to discuss their properties and their relation to the classical hidden Markov model (HMM) based ASR architecture. All relevant aspects of E2E ASR are covered in this work: modeling, training, decoding, and external language model integration, accompanied by discussions of performance and deployment opportunities, as well as an outlook into potential future developments.
Variable Attention Masking for Configurable Transformer Transducer Speech Recognition
Nov 02, 2022



This work studies the use of attention masking in transformer transducer based speech recognition for building a single configurable model for different deployment scenarios. We present a comprehensive set of experiments comparing fixed masking, where the same attention mask is applied at every frame, with chunked masking, where the attention mask for each frame is determined by chunk boundaries, in terms of recognition accuracy and latency. We then explore the use of variable masking, where the attention masks are sampled from a target distribution at training time, to build models that can work in different configurations. Finally, we investigate how a single configurable model can be used to perform both first pass streaming recognition and second pass acoustic rescoring. Experiments show that chunked masking achieves a better accuracy vs latency trade-off compared to fixed masking, both with and without FastEmit. We also show that variable masking improves the accuracy by up to 8% relative in the acoustic re-scoring scenario.
Extended Graph Temporal Classification for Multi-Speaker End-to-End ASR
Mar 01, 2022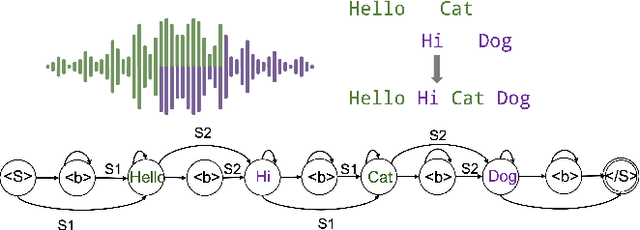
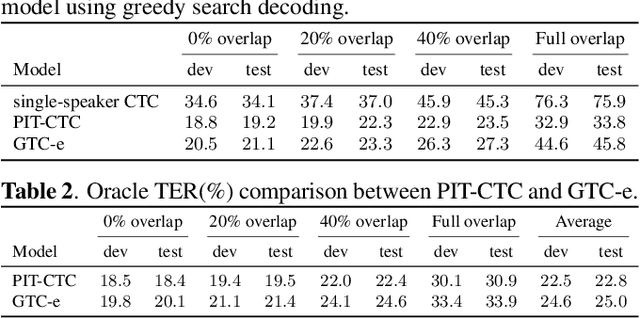
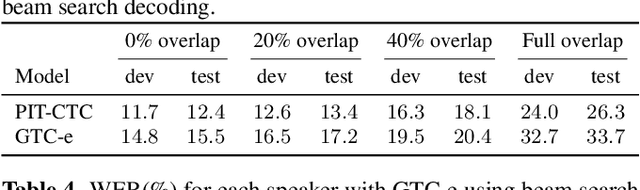
Graph-based temporal classification (GTC), a generalized form of the connectionist temporal classification loss, was recently proposed to improve automatic speech recognition (ASR) systems using graph-based supervision. For example, GTC was first used to encode an N-best list of pseudo-label sequences into a graph for semi-supervised learning. In this paper, we propose an extension of GTC to model the posteriors of both labels and label transitions by a neural network, which can be applied to a wider range of tasks. As an example application, we use the extended GTC (GTC-e) for the multi-speaker speech recognition task. The transcriptions and speaker information of multi-speaker speech are represented by a graph, where the speaker information is associated with the transitions and ASR outputs with the nodes. Using GTC-e, multi-speaker ASR modelling becomes very similar to single-speaker ASR modeling, in that tokens by multiple speakers are recognized as a single merged sequence in chronological order. For evaluation, we perform experiments on a simulated multi-speaker speech dataset derived from LibriSpeech, obtaining promising results with performance close to classical benchmarks for the task.
Sequence Transduction with Graph-based Supervision
Nov 01, 2021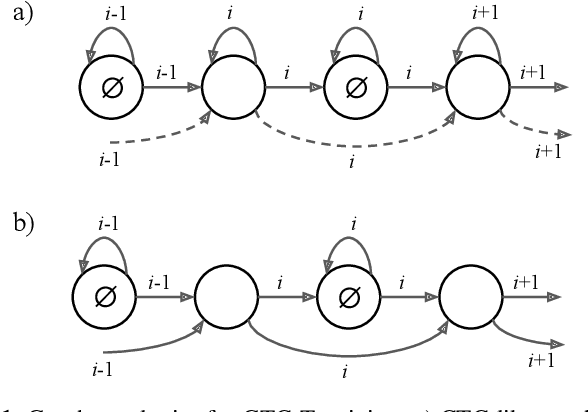
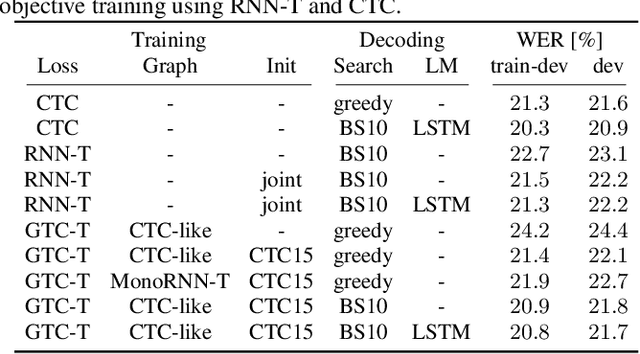
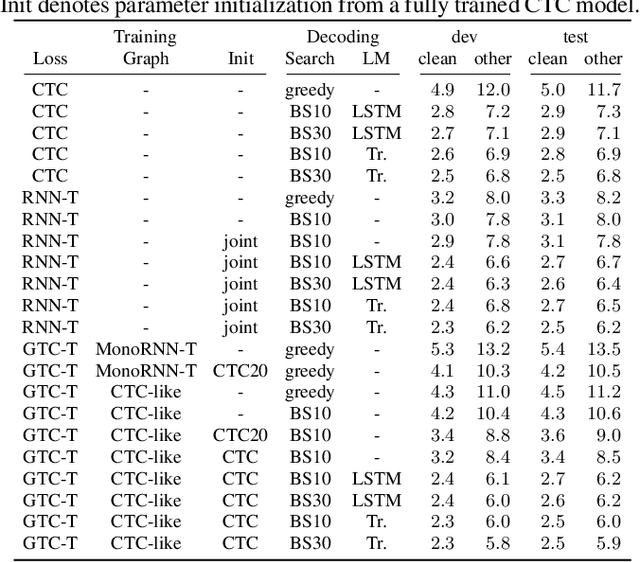
The recurrent neural network transducer (RNN-T) objective plays a major role in building today's best automatic speech recognition (ASR) systems for production. Similarly to the connectionist temporal classification (CTC) objective, the RNN-T loss uses specific rules that define how a set of alignments is generated to form a lattice for the full-sum training. However, it is yet largely unknown if these rules are optimal and do lead to the best possible ASR results. In this work, we present a new transducer objective function that generalizes the RNN-T loss to accept a graph representation of the labels, thus providing a flexible and efficient framework to manipulate training lattices, for example for restricting alignments or studying different transition rules. We demonstrate that transducer-based ASR with CTC-like lattice achieves better results compared to standard RNN-T, while also ensuring a strictly monotonic alignment, which will allow better optimization of the decoding procedure. For example, the proposed CTC-like transducer system achieves a word error rate of 5.9% for the test-other condition of LibriSpeech, corresponding to an improvement of 4.8% relative to an equivalent RNN-T based system.
Audio-Visual Scene-Aware Dialog and Reasoning using Audio-Visual Transformers with Joint Student-Teacher Learning
Oct 13, 2021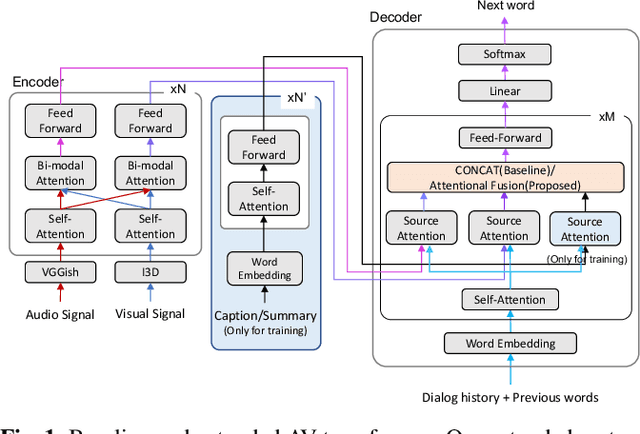
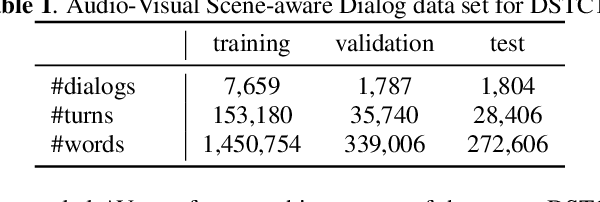
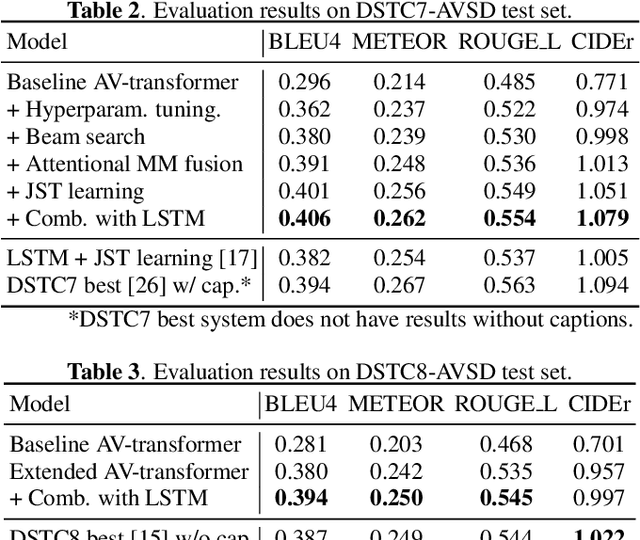
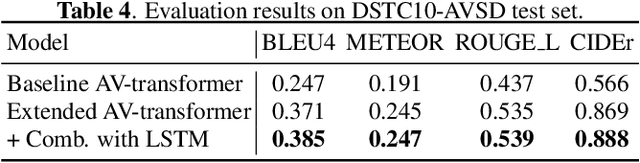
In previous work, we have proposed the Audio-Visual Scene-Aware Dialog (AVSD) task, collected an AVSD dataset, developed AVSD technologies, and hosted an AVSD challenge track at both the 7th and 8th Dialog System Technology Challenges (DSTC7, DSTC8). In these challenges, the best-performing systems relied heavily on human-generated descriptions of the video content, which were available in the datasets but would be unavailable in real-world applications. To promote further advancements for real-world applications, we proposed a third AVSD challenge, at DSTC10, with two modifications: 1) the human-created description is unavailable at inference time, and 2) systems must demonstrate temporal reasoning by finding evidence from the video to support each answer. This paper introduces the new task that includes temporal reasoning and our new extension of the AVSD dataset for DSTC10, for which we collected human-generated temporal reasoning data. We also introduce a baseline system built using an AV-transformer, which we released along with the new dataset. Finally, this paper introduces a new system that extends our baseline system with attentional multimodal fusion, joint student-teacher learning (JSTL), and model combination techniques, achieving state-of-the-art performances on the AVSD datasets for DSTC7, DSTC8, and DSTC10. We also propose two temporal reasoning methods for AVSD: one attention-based, and one based on a time-domain region proposal network.
Advancing Momentum Pseudo-Labeling with Conformer and Initialization Strategy
Oct 11, 2021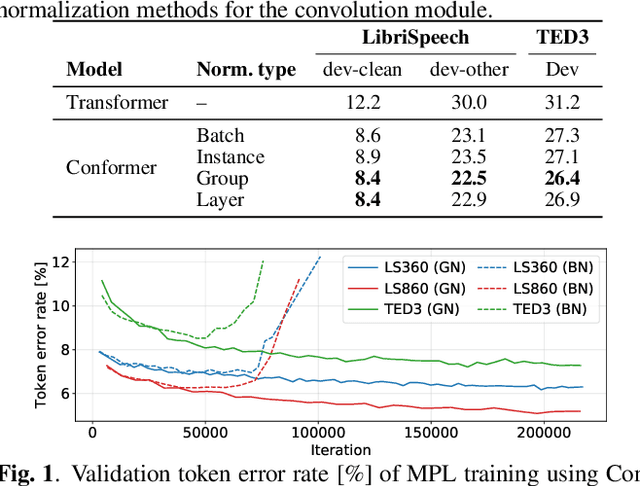
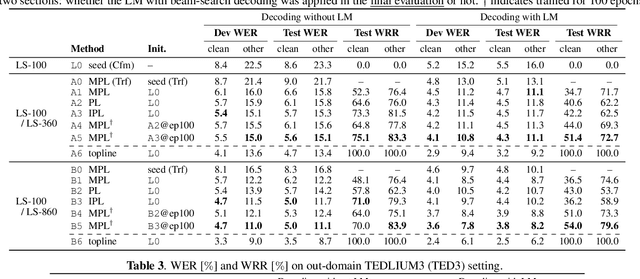
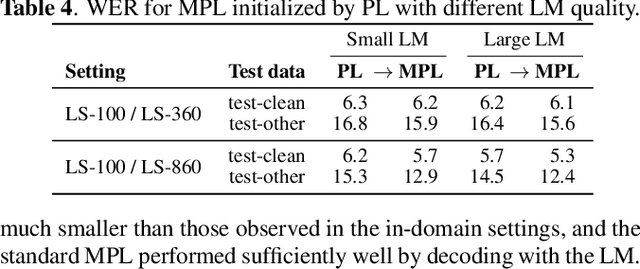
Pseudo-labeling (PL), a semi-supervised learning (SSL) method where a seed model performs self-training using pseudo-labels generated from untranscribed speech, has been shown to enhance the performance of end-to-end automatic speech recognition (ASR). Our prior work proposed momentum pseudo-labeling (MPL), which performs PL-based SSL via an interaction between online and offline models, inspired by the mean teacher framework. MPL achieves remarkable results on various semi-supervised settings, showing robustness to variations in the amount of data and domain mismatch severity. However, there is further room for improving the seed model used to initialize the MPL training, as it is in general critical for a PL-based method to start training from high-quality pseudo-labels. To this end, we propose to enhance MPL by (1) introducing the Conformer architecture to boost the overall recognition accuracy and (2) exploiting iterative pseudo-labeling with a language model to improve the seed model before applying MPL. The experimental results demonstrate that the proposed approaches effectively improve MPL performance, outperforming other PL-based methods. We also present in-depth investigations to make our improvements effective, e.g., with regard to batch normalization typically used in Conformer and LM quality.
Optimizing Latency for Online Video CaptioningUsing Audio-Visual Transformers
Aug 04, 2021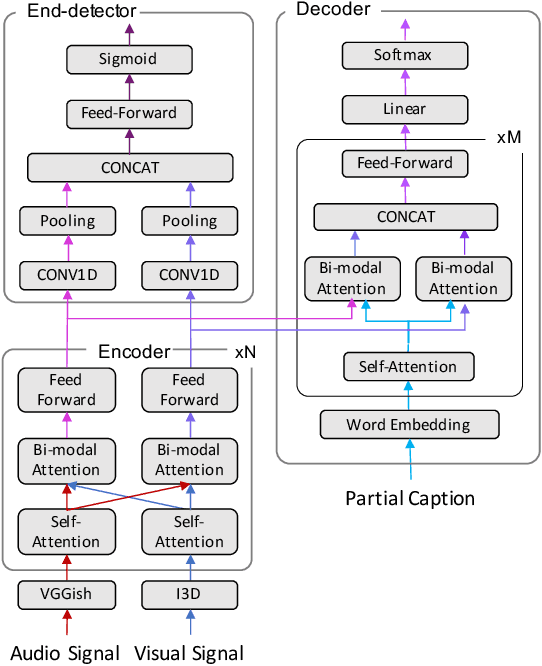
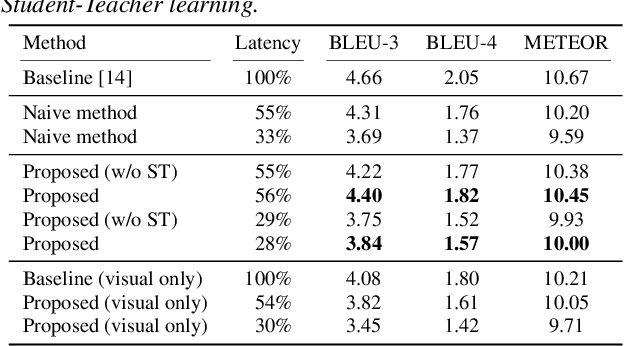
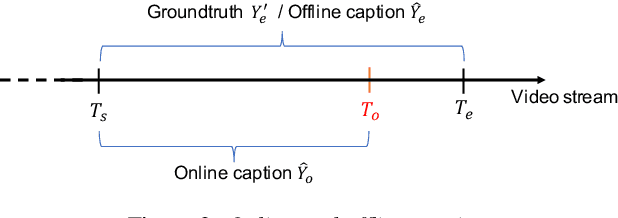
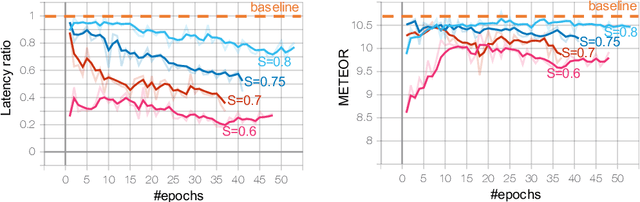
Video captioning is an essential technology to understand scenes and describe events in natural language. To apply it to real-time monitoring, a system needs not only to describe events accurately but also to produce the captions as soon as possible. Low-latency captioning is needed to realize such functionality, but this research area for online video captioning has not been pursued yet. This paper proposes a novel approach to optimize each caption's output timing based on a trade-off between latency and caption quality. An audio-visual Trans-former is trained to generate ground-truth captions using only a small portion of all video frames, and to mimic outputs of a pre-trained Transformer to which all the frames are given. A CNN-based timing detector is also trained to detect a proper output timing, where the captions generated by the two Trans-formers become sufficiently close to each other. With the jointly trained Transformer and timing detector, a caption can be generated in the early stages of an event-triggered video clip, as soon as an event happens or when it can be forecasted. Experiments with the ActivityNet Captions dataset show that our approach achieves 94% of the caption quality of the upper bound given by the pre-trained Transformer using the entire video clips, using only 28% of frames from the beginning.