 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtended Graph Temporal Classification for Multi-Speaker End-to-End ASR
Paper and Code
Mar 01, 2022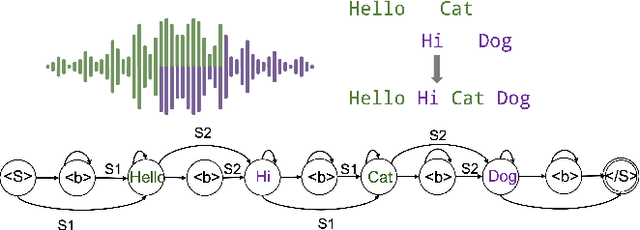
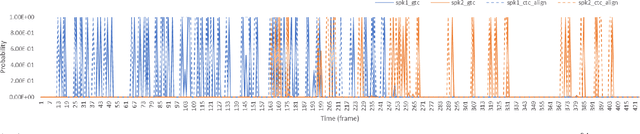
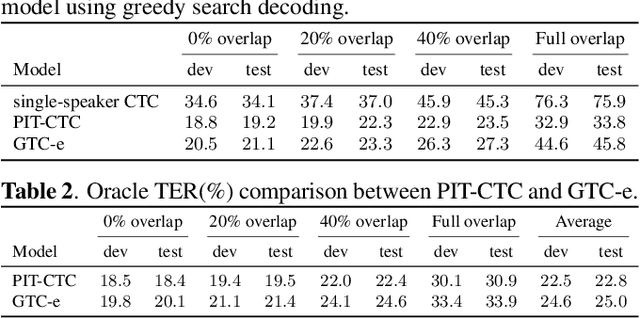
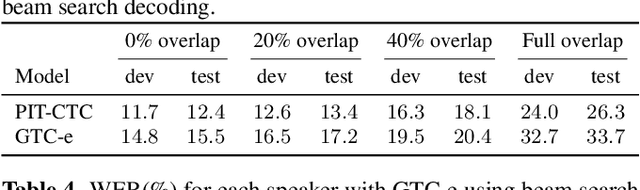
Graph-based temporal classification (GTC), a generalized form of the connectionist temporal classification loss, was recently proposed to improve automatic speech recognition (ASR) systems using graph-based supervision. For example, GTC was first used to encode an N-best list of pseudo-label sequences into a graph for semi-supervised learning. In this paper, we propose an extension of GTC to model the posteriors of both labels and label transitions by a neural network, which can be applied to a wider range of tasks. As an example application, we use the extended GTC (GTC-e) for the multi-speaker speech recognition task. The transcriptions and speaker information of multi-speaker speech are represented by a graph, where the speaker information is associated with the transitions and ASR outputs with the nodes. Using GTC-e, multi-speaker ASR modelling becomes very similar to single-speaker ASR modeling, in that tokens by multiple speakers are recognized as a single merged sequence in chronological order. For evaluation, we perform experiments on a simulated multi-speaker speech dataset derived from LibriSpeech, obtaining promising results with performance close to classical benchmarks for the task.