 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeO-EENC-SD: Efficient Online End-to-End Neural Clustering for Speaker Diarization
Dec 17, 2025We introduce O-EENC-SD: an end-to-end online speaker diarization system based on EEND-EDA, featuring a novel RNN-based stitching mechanism for online prediction. In particular, we develop a novel centroid refinement decoder whose usefulness is assessed through a rigorous ablation study. Our system provides key advantages over existing methods: a hyperparameter-free solution compared to unsupervised clustering approaches, and a more efficient alternative to current online end-to-end methods, which are computationally costly. We demonstrate that O-EENC-SD is competitive with the state of the art in the two-speaker conversational telephone speech domain, as tested on the CallHome dataset. Our results show that O-EENC-SD provides a great trade-off between DER and complexity, even when working on independent chunks with no overlap, making the system extremely efficient.
FlexIO: Flexible Single- and Multi-Channel Speech Separation and Enhancement
Oct 24, 2025Speech separation and enhancement (SSE) has advanced remarkably and achieved promising results in controlled settings, such as a fixed number of speakers and a fixed array configuration. Towards a universal SSE system, single-channel systems have been extended to deal with a variable number of speakers (i.e., outputs). Meanwhile, multi-channel systems accommodating various array configurations (i.e., inputs) have been developed. However, these attempts have been pursued separately. In this paper, we propose a flexible input and output SSE system, named FlexIO. It performs conditional separation using prompt vectors, one per speaker as a condition, allowing separation of an arbitrary number of speakers. Multi-channel mixtures are processed together with the prompt vectors via an array-agnostic channel communication mechanism. Our experiments demonstrate that FlexIO successfully covers diverse conditions with one to five microphones and one to three speakers. We also confirm the robustness of FlexIO on CHiME-4 real data.
Exploring Disentangled Neural Speech Codecs from Self-Supervised Representations
Aug 11, 2025Neural audio codecs (NACs), which use neural networks to generate compact audio representations, have garnered interest for their applicability to many downstream tasks -- especially quantized codecs due to their compatibility with large language models. However, unlike text, speech conveys not only linguistic content but also rich paralinguistic features. Encoding these elements in an entangled fashion may be suboptimal, as it limits flexibility. For instance, voice conversion (VC) aims to convert speaker characteristics while preserving the original linguistic content, which requires a disentangled representation. Inspired by VC methods utilizing $k$-means quantization with self-supervised features to disentangle phonetic information, we develop a discrete NAC capable of structured disentanglement. Experimental evaluations show that our approach achieves reconstruction performance on par with conventional NACs that do not explicitly perform disentanglement, while also matching the effectiveness of conventional VC techniques.
FasTUSS: Faster Task-Aware Unified Source Separation
Jul 15, 2025Time-Frequency (TF) dual-path models are currently among the best performing audio source separation network architectures, achieving state-of-the-art performance in speech enhancement, music source separation, and cinematic audio source separation. While they are characterized by a relatively low parameter count, they still require a considerable number of operations, implying a higher execution time. This problem is exacerbated by the trend towards bigger models trained on large amounts of data to solve more general tasks, such as the recently introduced task-aware unified source separation (TUSS) model. TUSS, which aims to solve audio source separation tasks using a single, conditional model, is built upon TF-Locoformer, a TF dual-path model combining convolution and attention layers. The task definition comes in the form of a sequence of prompts that specify the number and type of sources to be extracted. In this paper, we analyze the design choices of TUSS with the goal of optimizing its performance-complexity trade-off. We derive two more efficient models, FasTUSS-8.3G and FasTUSS-11.7G that reduce the original model's operations by 81\% and 73\% with minor performance drops of 1.2~dB and 0.4~dB averaged over all benchmarks, respectively. Additionally, we investigate the impact of prompt conditioning to derive a causal TUSS model.
Physics-Informed Direction-Aware Neural Acoustic Fields
Jul 09, 2025This paper presents a physics-informed neural network (PINN) for modeling first-order Ambisonic (FOA) room impulse responses (RIRs). PINNs have demonstrated promising performance in sound field interpolation by combining the powerful modeling capability of neural networks and the physical principles of sound propagation. In room acoustics, PINNs have typically been trained to represent the sound pressure measured by omnidirectional microphones where the wave equation or its frequency-domain counterpart, i.e., the Helmholtz equation, is leveraged. Meanwhile, FOA RIRs additionally provide spatial characteristics and are useful for immersive audio generation with a wide range of applications. In this paper, we extend the PINN framework to model FOA RIRs. We derive two physics-informed priors for FOA RIRs based on the correspondence between the particle velocity and the (X, Y, Z)-channels of FOA. These priors associate the predicted W-channel and other channels through their partial derivatives and impose the physically feasible relationship on the four channels. Our experiments confirm the effectiveness of the proposed method compared with a neural network without the physics-informed prior.
Factorized RVQ-GAN For Disentangled Speech Tokenization
Jun 18, 2025We propose Hierarchical Audio Codec (HAC), a unified neural speech codec that factorizes its bottleneck into three linguistic levels-acoustic, phonetic, and lexical-within a single model. HAC leverages two knowledge distillation objectives: one from a pre-trained speech encoder (HuBERT) for phoneme-level structure, and another from a text-based encoder (LaBSE) for lexical cues. Experiments on English and multilingual data show that HAC's factorized bottleneck yields disentangled token sets: one aligns with phonemes, while another captures word-level semantics. Quantitative evaluations confirm that HAC tokens preserve naturalness and provide interpretable linguistic information, outperforming single-level baselines in both disentanglement and reconstruction quality. These findings underscore HAC's potential as a unified discrete speech representation, bridging acoustic detail and lexical meaning for downstream speech generation and understanding tasks.
Direction-Aware Neural Acoustic Fields for Few-Shot Interpolation of Ambisonic Impulse Responses
May 19, 2025The characteristics of a sound field are intrinsically linked to the geometric and spatial properties of the environment surrounding a sound source and a listener. The physics of sound propagation is captured in a time-domain signal known as a room impulse response (RIR). Prior work using neural fields (NFs) has allowed learning spatially-continuous representations of RIRs from finite RIR measurements. However, previous NF-based methods have focused on monaural omnidirectional or at most binaural listeners, which does not precisely capture the directional characteristics of a real sound field at a single point. We propose a direction-aware neural field (DANF) that more explicitly incorporates the directional information by Ambisonic-format RIRs. While DANF inherently captures spatial relations between sources and listeners, we further propose a direction-aware loss. In addition, we investigate the ability of DANF to adapt to new rooms in various ways including low-rank adaptation.
Data Augmentation Using Neural Acoustic Fields With Retrieval-Augmented Pre-training
Apr 19, 2025


This report details MERL's system for room impulse response (RIR) estimation submitted to the Generative Data Augmentation Workshop at ICASSP 2025 for Augmenting RIR Data (Task 1) and Improving Speaker Distance Estimation (Task 2). We first pre-train a neural acoustic field conditioned by room geometry on an external large-scale dataset in which pairs of RIRs and the geometries are provided. The neural acoustic field is then adapted to each target room by using the enrollment data, where we leverage either the provided room geometries or geometries retrieved from the external dataset, depending on availability. Lastly, we predict the RIRs for each pair of source and receiver locations specified by Task 1, and use these RIRs to train the speaker distance estimation model in Task 2.
Handling Domain Shifts for Anomalous Sound Detection: A Review of DCASE-Related Work
Mar 13, 2025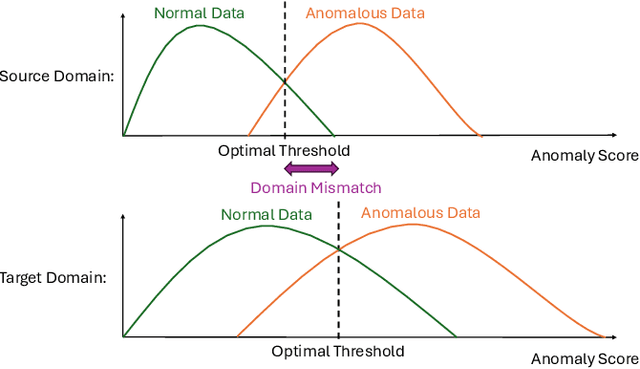
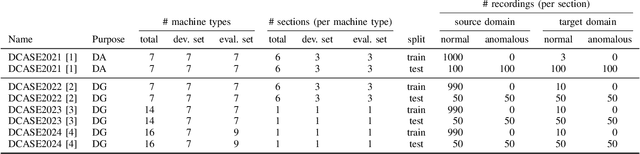
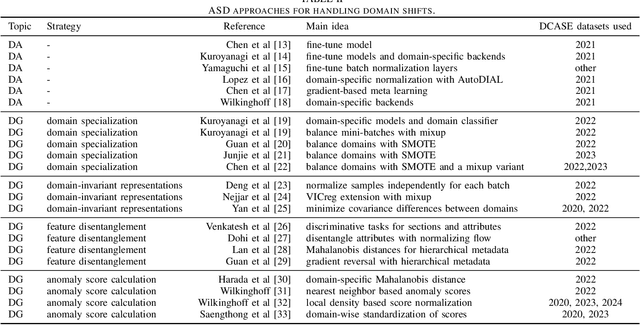
When detecting anomalous sounds in complex environments, one of the main difficulties is that trained models must be sensitive to subtle differences in monitored target signals, while many practical applications also require them to be insensitive to changes in acoustic domains. Examples of such domain shifts include changing the type of microphone or the location of acoustic sensors, which can have a much stronger impact on the acoustic signal than subtle anomalies themselves. Moreover, users typically aim to train a model only on source domain data, which they may have a relatively large collection of, and they hope that such a trained model will be able to generalize well to an unseen target domain by providing only a minimal number of samples to characterize the acoustic signals in that domain. In this work, we review and discuss recent publications focusing on this domain generalization problem for anomalous sound detection in the context of the DCASE challenges on acoustic machine condition monitoring.
Task-Aware Unified Source Separation
Oct 31, 2024Several attempts have been made to handle multiple source separation tasks such as speech enhancement, speech separation, sound event separation, music source separation (MSS), or cinematic audio source separation (CASS) with a single model. These models are trained on large-scale data including speech, instruments, or sound events and can often successfully separate a wide range of sources. However, it is still challenging for such models to cover all separation tasks because some of them are contradictory (e.g., musical instruments are separated in MSS while they have to be grouped in CASS). To overcome this issue and support all the major separation tasks, we propose a task-aware unified source separation (TUSS) model. The model uses a variable number of learnable prompts to specify which source to separate, and changes its behavior depending on the given prompts, enabling it to handle all the major separation tasks including contradictory ones. Experimental results demonstrate that the proposed TUSS model successfully handles the five major separation tasks mentioned earlier. We also provide some audio examples, including both synthetic mixtures and real recordings, to demonstrate how flexibly the TUSS model changes its behavior at inference depending on the prompts.