 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Anomalous Sound Detection through Pseudo-anomalous Set Selection and Pseudo-label Utilization under Unlabeled Conditions
May 25, 2025This paper addresses performance degradation in anomalous sound detection (ASD) when neither sufficiently similar machine data nor operational state labels are available. We present an integrated pipeline that combines three complementary components derived from prior work and extends them to the unlabeled ASD setting. First, we adapt an anomaly score based selector to curate external audio data resembling the normal sounds of the target machine. Second, we utilize triplet learning to assign pseudo-labels to unlabeled data, enabling finer classification of operational sounds and detection of subtle anomalies. Third, we employ iterative training to refine both the pseudo-anomalous set selection and pseudo-label assignment, progressively improving detection accuracy. Experiments on the DCASE2022-2024 Task 2 datasets demonstrate that, in unlabeled settings, our approach achieves an average AUC increase of over 6.6 points compared to conventional methods. In labeled settings, incorporating external data from the pseudo-anomalous set further boosts performance. These results highlight the practicality and robustness of our methods in scenarios with scarce machine data and labels, facilitating ASD deployment across diverse industrial settings with minimal annotation effort.
Analysis and Extension of Noisy-target Training for Unsupervised Target Signal Enhancement
Mar 19, 2025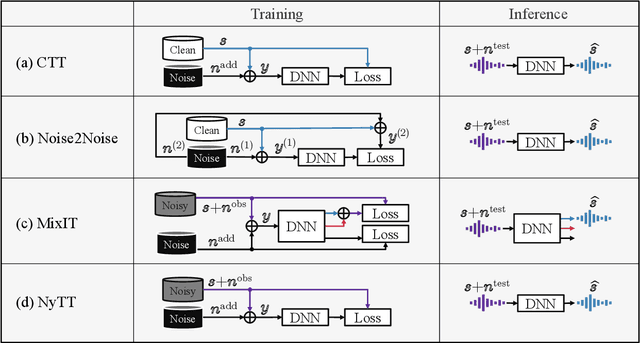
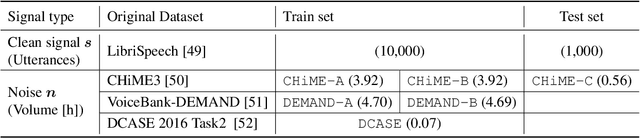

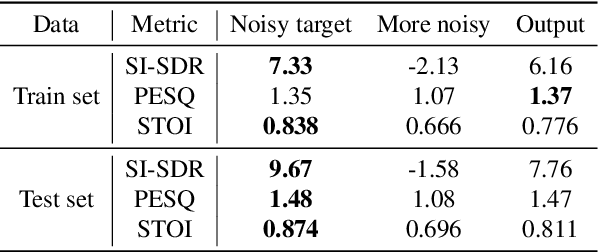
Deep neural network-based target signal enhancement (TSE) is usually trained in a supervised manner using clean target signals. However, collecting clean target signals is costly and such signals are not always available. Thus, it is desirable to develop an unsupervised method that does not rely on clean target signals. Among various studies on unsupervised TSE methods, Noisy-target Training (NyTT) has been established as a fundamental method. NyTT simply replaces clean target signals with noisy ones in the typical supervised training, and it has been experimentally shown to achieve TSE. Despite its effectiveness and simplicity, its mechanism and detailed behavior are still unclear. In this paper, to advance NyTT and, thus, unsupervised methods as a whole, we analyze NyTT from various perspectives. We experimentally demonstrate the mechanism of NyTT, the desirable conditions, and the effectiveness of utilizing noisy signals in situations where a small number of clean target signals are available. Furthermore, we propose an improved version of NyTT based on its properties and explore its capabilities in the dereverberation and declipping tasks, beyond the denoising task.
Handling Domain Shifts for Anomalous Sound Detection: A Review of DCASE-Related Work
Mar 13, 2025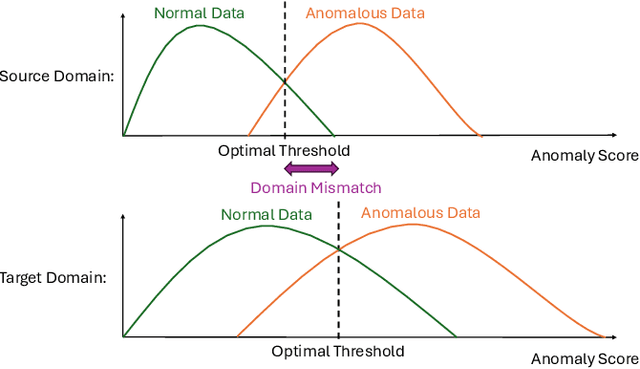
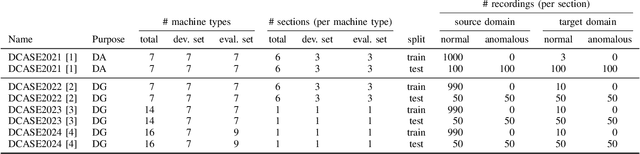
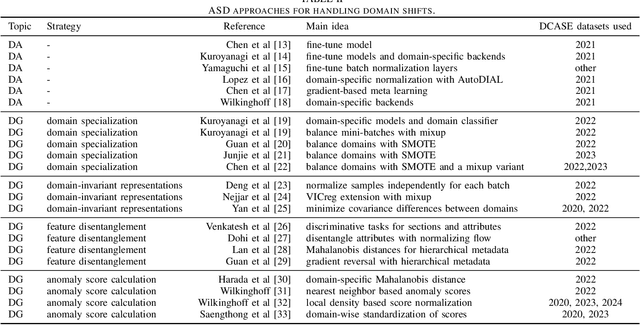
When detecting anomalous sounds in complex environments, one of the main difficulties is that trained models must be sensitive to subtle differences in monitored target signals, while many practical applications also require them to be insensitive to changes in acoustic domains. Examples of such domain shifts include changing the type of microphone or the location of acoustic sensors, which can have a much stronger impact on the acoustic signal than subtle anomalies themselves. Moreover, users typically aim to train a model only on source domain data, which they may have a relatively large collection of, and they hope that such a trained model will be able to generalize well to an unseen target domain by providing only a minimal number of samples to characterize the acoustic signals in that domain. In this work, we review and discuss recent publications focusing on this domain generalization problem for anomalous sound detection in the context of the DCASE challenges on acoustic machine condition monitoring.
Two-stage Framework for Robust Speech Emotion Recognition Using Target Speaker Extraction in Human Speech Noise Conditions
Sep 29, 2024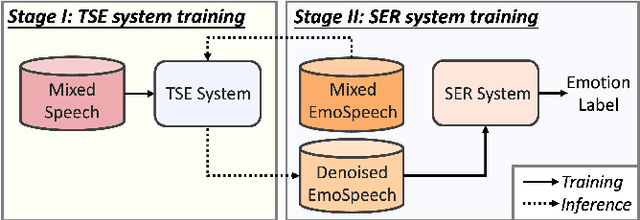
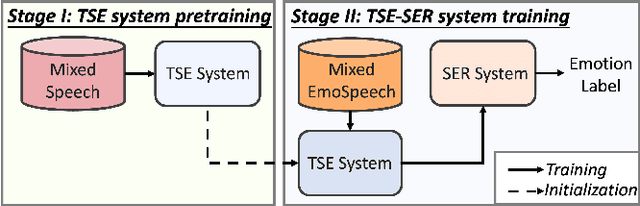
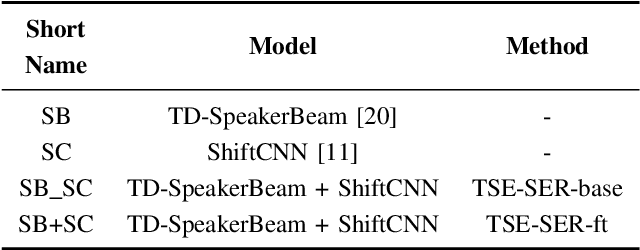
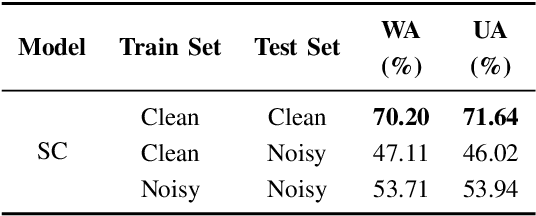
Developing a robust speech emotion recognition (SER) system in noisy conditions faces challenges posed by different noise properties. Most previous studies have not considered the impact of human speech noise, thus limiting the application scope of SER. In this paper, we propose a novel two-stage framework for the problem by cascading target speaker extraction (TSE) method and SER. We first train a TSE model to extract the speech of target speaker from a mixture. Then, in the second stage, we utilize the extracted speech for SER training. Additionally, we explore a joint training of TSE and SER models in the second stage. Our developed system achieves a 14.33% improvement in unweighted accuracy (UA) compared to a baseline without using TSE method, demonstrating the effectiveness of our framework in mitigating the impact of human speech noise. Moreover, we conduct experiments considering speaker gender, showing that our framework performs particularly well in different-gender mixture.
Improvements of Discriminative Feature Space Training for Anomalous Sound Detection in Unlabeled Conditions
Sep 14, 2024In anomalous sound detection, the discriminative method has demonstrated superior performance. This approach constructs a discriminative feature space through the classification of the meta-information labels for normal sounds. This feature space reflects the differences in machine sounds and effectively captures anomalous sounds. However, its performance significantly degrades when the meta-information labels are missing. In this paper, we improve the performance of a discriminative method under unlabeled conditions by two approaches. First, we enhance the feature extractor to perform better under unlabeled conditions. Our enhanced feature extractor utilizes multi-resolution spectrograms with a new training strategy. Second, we propose various pseudo-labeling methods to effectively train the feature extractor. The experimental evaluations show that the proposed feature extractor and pseudo-labeling methods significantly improve performance under unlabeled conditions.
Discriminative Neighborhood Smoothing for Generative Anomalous Sound Detection
Mar 18, 2024



We propose discriminative neighborhood smoothing of generative anomaly scores for anomalous sound detection. While the discriminative approach is known to achieve better performance than generative approaches often, we have found that it sometimes causes significant performance degradation due to the discrepancy between the training and test data, making it less robust than the generative approach. Our proposed method aims to compensate for the disadvantages of generative and discriminative approaches by combining them. Generative anomaly scores are smoothed using multiple samples with similar discriminative features to improve the performance of the generative approach in an ensemble manner while keeping its robustness. Experimental results show that our proposed method greatly improves the original generative method, including absolute improvement of 22% in AUC and robustly works, while a discriminative method suffers from the discrepancy.
Analysis of Noisy-target Training for DNN-based speech enhancement
Nov 02, 2022



Deep neural network (DNN)-based speech enhancement usually uses a clean speech as a training target. However, it is hard to collect large amounts of clean speech because the recording is very costly. In other words, the performance of current speech enhancement has been limited by the amount of training data. To relax this limitation, Noisy-target Training (NyTT) that utilizes noisy speech as a training target has been proposed. Although it has been experimentally shown that NyTT can train a DNN without clean speech, a detailed analysis has not been conducted and its behavior has not been understood well. In this paper, we conduct various analyses to deepen our understanding of NyTT. In addition, based on the property of NyTT, we propose a refined method that is comparable to the method using clean speech. Furthermore, we show that we can improve the performance by using a huge amount of noisy speech with clean speech.
Noisy-target Training: A Training Strategy for DNN-based Speech Enhancement without Clean Speech
Jan 21, 2021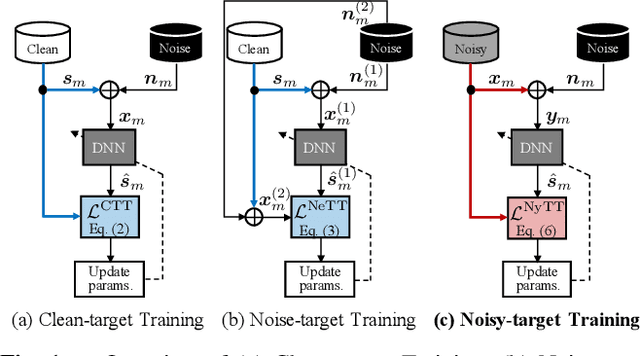
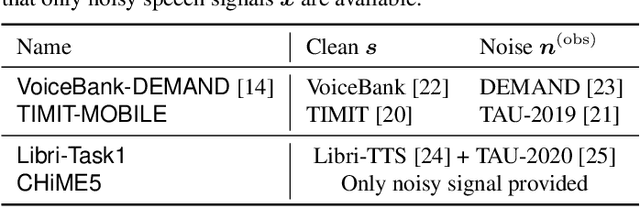
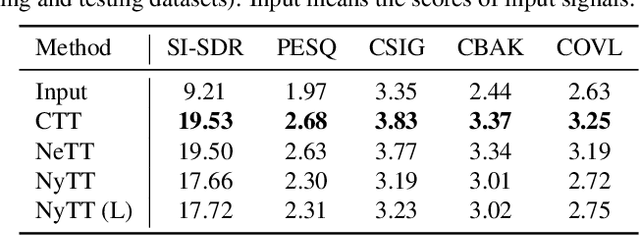

Deep neural network (DNN)-based speech enhancement ordinarily requires clean speech signals as the training target. However, collecting clean signals is very costly because they must be recorded in a studio. This requirement currently restricts the amount of training data for speech enhancement less than 1/1000 of that of speech recognition which does not need clean signals. Increasing the amount of training data is important for improving the performance, and hence the requirement of clean signals should be relaxed. In this paper, we propose a training strategy that does not require clean signals. The proposed method only utilizes noisy signals for training, which enables us to use a variety of speech signals in the wild. Our experimental results showed that the proposed method can achieve the performance similar to that of a DNN trained with clean signals.