 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLipsAM: Lipschitz-Continuous Amplitude Modifier for Audio Signal Processing and its Application to Plug-and-Play Dereverberation
Mar 23, 2026The robustness of deep neural networks (DNNs) can be certified through their Lipschitz continuity, which has made the construction of Lipschitz-continuous DNNs an active research field. However, DNNs for audio processing have not been a major focus due to their poor compatibility with existing results. In this paper, we consider the amplitude modifier (AM), a popular architecture for handling audio signals, and propose its Lipschitz-continuous variants, which we refer to as LipsAM. We prove a sufficient condition for an AM to be Lipschitz continuous and propose two architectures as examples of LipsAM. The proposed architectures were applied to a Plug-and-Play algorithm for speech dereverberation, and their improved stability is demonstrated through numerical experiments.
SELEBI: Percussion-aware Time Stretching via Selective Magnitude Spectrogram Compression by Nonstationary Gabor Transform
Feb 18, 2026Phase vocoder-based time-stretching is a widely used technique for the time-scale modification of audio signals. However, conventional implementations suffer from ``percussion smearing,'' a well-known artifact that significantly degrades the quality of percussive components. We attribute this artifact to a fundamental time-scale mismatch between the temporally smeared magnitude spectrogram and the localized, newly generated phase. To address this, we propose SELEBI, a signal-adaptive phase vocoder algorithm that significantly reduces percussion smearing while preserving stability and the perfect reconstruction property. Unlike conventional methods that rely on heuristic processing or component separation, our approach leverages the nonstationary Gabor transform. By dynamically adapting analysis window lengths to assign short windows to intervals containing significant energy associated with percussive components, we directly compute a temporally localized magnitude spectrogram from the time-domain signal. This approach ensures greater consistency between the temporal structures of the magnitude and phase. Furthermore, the perfect reconstruction property of the nonstationary Gabor transform guarantees stable, high-fidelity signal synthesis, in contrast to previous heuristic approaches. Experimental results demonstrate that the proposed method effectively mitigates percussion smearing and yields natural sound quality.
Learn and Verify: A Framework for Rigorous Verification of Physics-Informed Neural Networks
Jan 27, 2026The numerical solution of differential equations using neural networks has become a central topic in scientific computing, with Physics-Informed Neural Networks (PINNs) emerging as a powerful paradigm for both forward and inverse problems. However, unlike classical numerical methods that offer established convergence guarantees, neural network-based approximations typically lack rigorous error bounds. Furthermore, the non-deterministic nature of their optimization makes it difficult to mathematically certify their accuracy. To address these challenges, we propose a "Learn and Verify" framework that provides computable, mathematically rigorous error bounds for the solutions of differential equations. By combining a novel Doubly Smoothed Maximum (DSM) loss for training with interval arithmetic for verification, we compute rigorous a posteriori error bounds as machine-verifiable proofs. Numerical experiments on nonlinear Ordinary Differential Equations (ODEs), including problems with time-varying coefficients and finite-time blow-up, demonstrate that the proposed framework successfully constructs rigorous enclosures of the true solutions, establishing a foundation for trustworthy scientific machine learning.
Proposal of protocols for speech materials acquisition and presentation assisted by tools based on structured test signals
Sep 30, 2024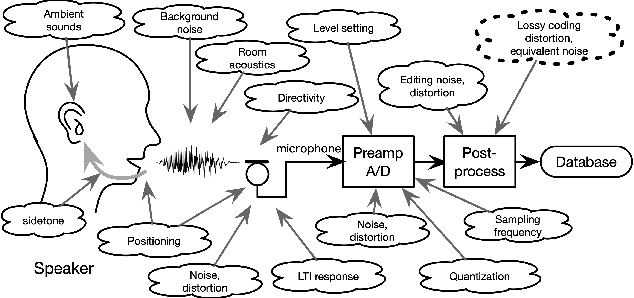
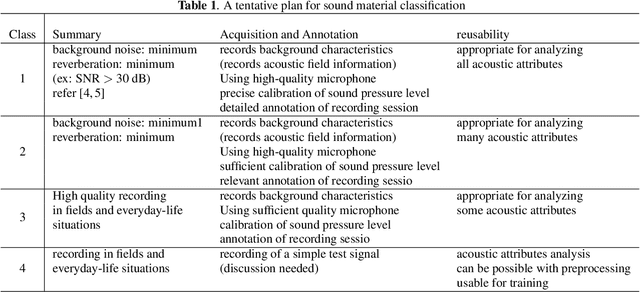
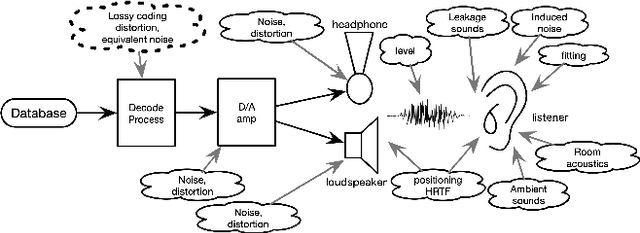
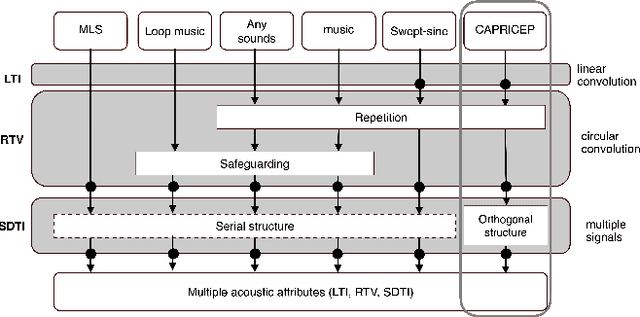
We propose protocols for acquiring speech materials, making them reusable for future investigations, and presenting them for subjective experiments. We also provide means to evaluate existing speech materials' compatibility with target applications. We built these protocols and tools based on structured test signals and analysis methods, including a new family of the Time-Stretched Pulse (TSP). Over a billion times more powerful computational (including software development) resources than a half-century ago enabled these protocols and tools to be accessible to under-resourced environments.
Subband Splitting: Simple, Efficient and Effective Technique for Solving Block Permutation Problem in Determined Blind Source Separation
Sep 14, 2024Solving the permutation problem is essential for determined blind source separation (BSS). Existing methods, such as independent vector analysis (IVA) and independent low-rank matrix analysis (ILRMA), tackle the permutation problem by modeling the co-occurrence of the frequency components of source signals. One of the remaining challenges in these methods is the block permutation problem, which may lead to poor separation results. In this paper, we propose a simple and effective technique for solving the block permutation problem. The proposed technique splits the entire frequencies into overlapping subbands and sequentially applies a BSS method (e.g., IVA, ILRMA, or any other method) to each subband. Since the problem size is reduced by the splitting, the BSS method can effectively work in each subband. Then, the permutations between the subbands are aligned by using the separation result in one subband as the initial values for the other subbands. Experimental results showed that the proposed technique remarkably improved the separation performance without increasing the total computational cost.
Sampling-Frequency-Independent Universal Sound Separation
Sep 22, 2023



This paper proposes a universal sound separation (USS) method capable of handling untrained sampling frequencies (SFs). The USS aims at separating arbitrary sources of different types and can be the key technique to realize a source separator that can be universally used as a preprocessor for any downstream tasks. To realize a universal source separator, there are two essential properties: universalities with respect to source types and recording conditions. The former property has been studied in the USS literature, which has greatly increased the number of source types that can be handled by a single neural network. However, the latter property (e.g., SF) has received less attention despite its necessity. Since the SF varies widely depending on the downstream tasks, the universal source separator must handle a wide variety of SFs. In this paper, to encompass the two properties, we propose an SF-independent (SFI) extension of a computationally efficient USS network, SuDoRM-RF. The proposed network uses our previously proposed SFI convolutional layers, which can handle various SFs by generating convolutional kernels in accordance with an input SF. Experiments show that signal resampling can degrade the USS performance and the proposed method works more consistently than signal-resampling-based methods for various SFs.
Simultaneous Measurement of Multiple Acoustic Attributes Using Structured Periodic Test Signals Including Music and Other Sound Materials
Sep 06, 2023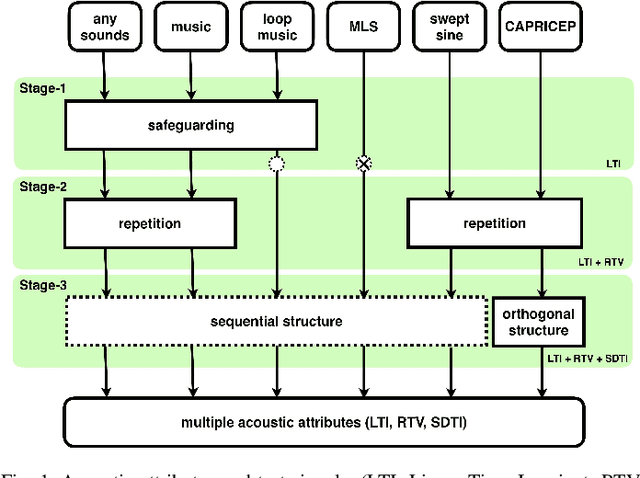
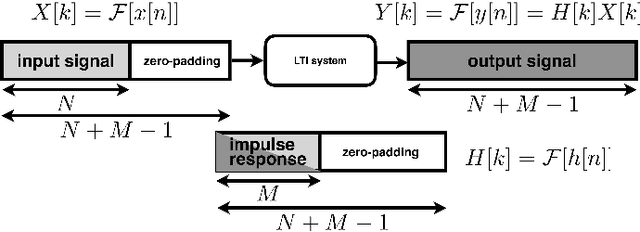
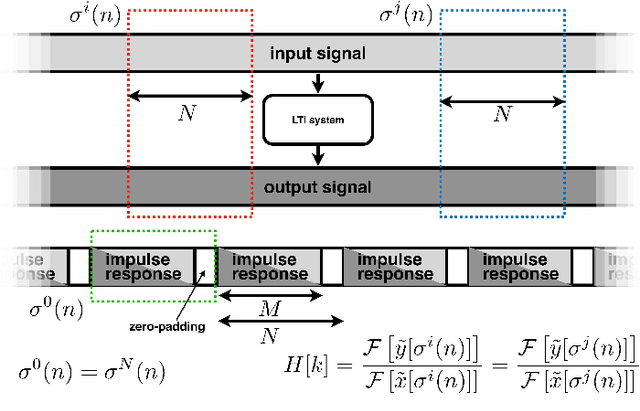
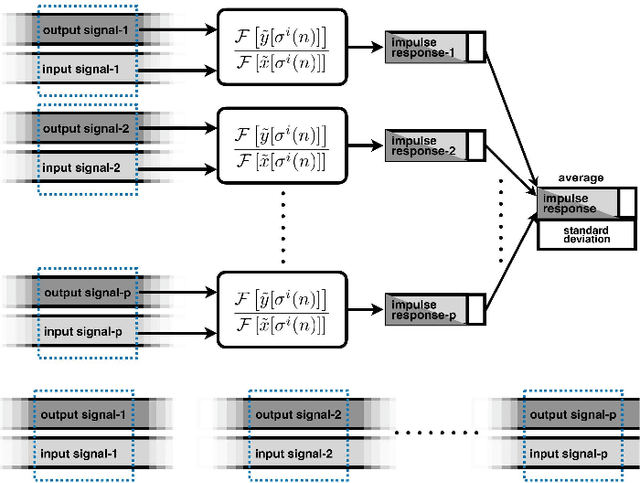
We introduce a general framework for measuring acoustic properties such as liner time-invariant (LTI) response, signal-dependent time-invariant (SDTI) component, and random and time-varying (RTV) component simultaneously using structured periodic test signals. The framework also enables music pieces and other sound materials as test signals by "safeguarding" them by adding slight deterministic "noise." Measurement using swept-sin, MLS (Maxim Length Sequence), and their variants are special cases of the proposed framework. We implemented interactive and real-time measuring tools based on this framework and made them open-source. Furthermore, we applied this framework to assess pitch extractors objectively.
Versatile Time-Frequency Representations Realized by Convex Penalty on Magnitude Spectrogram
Aug 03, 2023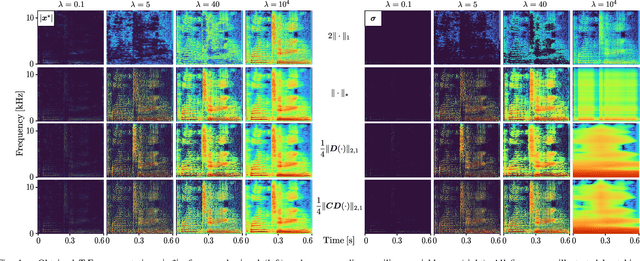
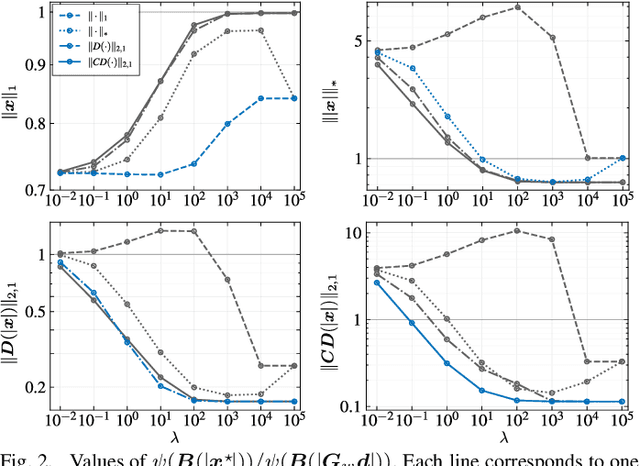
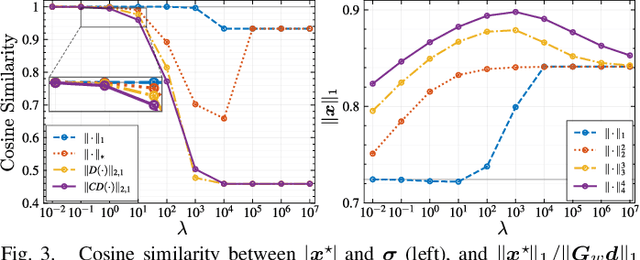
Sparse time-frequency (T-F) representations have been an important research topic for more than several decades. Among them, optimization-based methods (in particular, extensions of basis pursuit) allow us to design the representations through objective functions. Since acoustic signal processing utilizes models of spectrogram, the flexibility of optimization-based T-F representations is helpful for adjusting the representation for each application. However, acoustic applications often require models of \textit{magnitude} of T-F representations obtained by discrete Gabor transform (DGT). Adjusting a T-F representation to such a magnitude model (e.g., smoothness of magnitude of DGT coefficients) results in a non-convex optimization problem that is difficult to solve. In this paper, instead of tackling difficult non-convex problems, we propose a convex optimization-based framework that realizes a T-F representation whose magnitude has characteristics specified by the user. We analyzed the properties of the proposed method and provide numerical examples of sparse T-F representations having, e.g., low-rank or smooth magnitude, which have not been realized before.
Algorithms of Sampling-Frequency-Independent Layers for Non-integer Strides
Jun 19, 2023



In this paper, we propose algorithms for handling non-integer strides in sampling-frequency-independent (SFI) convolutional and transposed convolutional layers. The SFI layers have been developed for handling various sampling frequencies (SFs) by a single neural network. They are replaceable with their non-SFI counterparts and can be introduced into various network architectures. However, they could not handle some specific configurations when combined with non-SFI layers. For example, an SFI extension of Conv-TasNet, a standard audio source separation model, cannot handle some pairs of trained and target SFs because the strides of the SFI layers become non-integers. This problem cannot be solved by simple rounding or signal resampling, resulting in the significant performance degradation. To overcome this problem, we propose algorithms for handling non-integer strides by using windowed sinc interpolation. The proposed algorithms realize the continuous-time representations of features using the interpolation and enable us to sample instants with the desired stride. Experimental results on music source separation showed that the proposed algorithms outperformed the rounding- and signal-resampling-based methods at SFs lower than the trained SF.
LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus
May 30, 2023
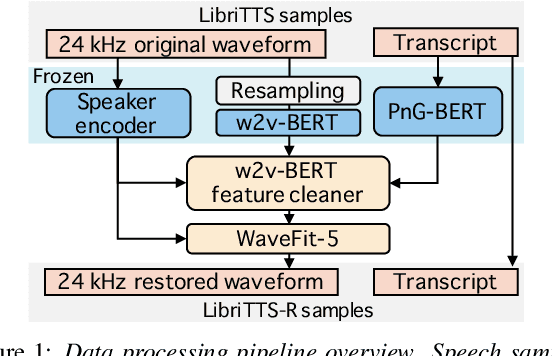
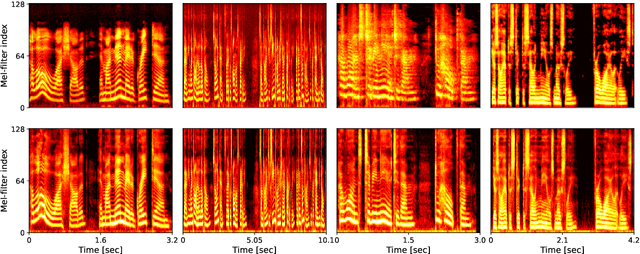

This paper introduces a new speech dataset called ``LibriTTS-R'' designed for text-to-speech (TTS) use. It is derived by applying speech restoration to the LibriTTS corpus, which consists of 585 hours of speech data at 24 kHz sampling rate from 2,456 speakers and the corresponding texts. The constituent samples of LibriTTS-R are identical to those of LibriTTS, with only the sound quality improved. Experimental results show that the LibriTTS-R ground-truth samples showed significantly improved sound quality compared to those in LibriTTS. In addition, neural end-to-end TTS trained with LibriTTS-R achieved speech naturalness on par with that of the ground-truth samples. The corpus is freely available for download from \url{http://www.openslr.org/141/}.