 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoundSil-DS: Deep Denoising and Segmentation of Sound-field Images with Silhouettes
Nov 12, 2024Development of optical technology has enabled imaging of two-dimensional (2D) sound fields. This acousto-optic sensing enables understanding of the interaction between sound and objects such as reflection and diffraction. Moreover, it is expected to be used an advanced measurement technology for sonars in self-driving vehicles and assistive robots. However, the low sound-pressure sensitivity of the acousto-optic sensing results in high intensity of noise on images. Therefore, denoising is an essential task to visualize and analyze the sound fields. In addition to denoising, segmentation of sound and object silhouette is also required to analyze interactions between them. In this paper, we propose sound-field-images-with-object-silhouette denoising and segmentation (SoundSil-DS) that jointly perform denoising and segmentation for sound fields and object silhouettes on a visualized image. We developed a new model based on the current state-of-the-art denoising network. We also created a dataset to train and evaluate the proposed method through acoustic simulation. The proposed method was evaluated using both simulated and measured data. We confirmed that our method can applied to experimentally measured data. These results suggest that the proposed method may improve the post-processing for sound fields, such as physical model-based three-dimensional reconstruction since it can remove unwanted noise and separate sound fields and other object silhouettes. Our code is available at https://github.com/nttcslab/soundsil-ds.
Online Phase Reconstruction via DNN-based Phase Differences Estimation
Nov 12, 2022
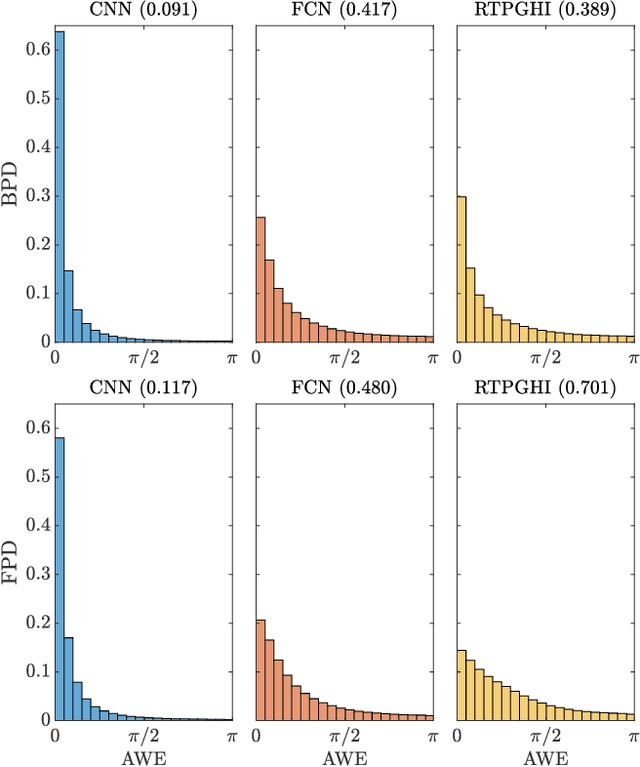
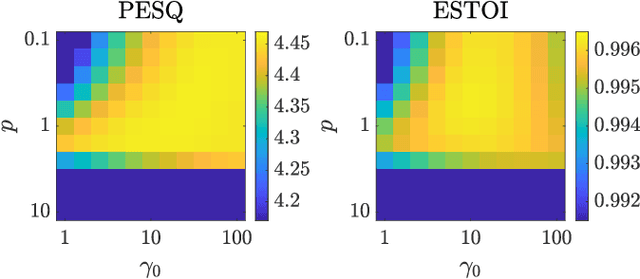
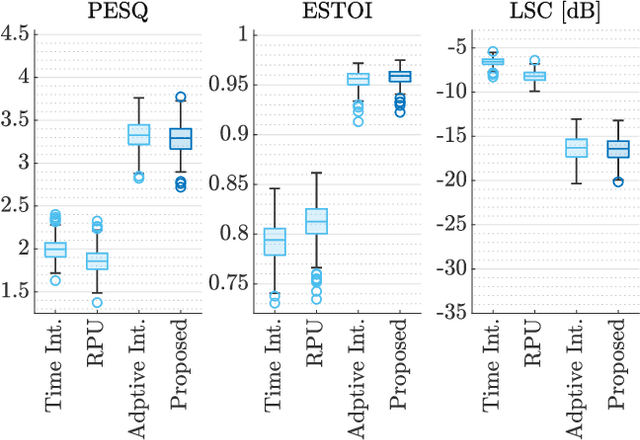
This paper presents a two-stage online phase reconstruction framework using causal deep neural networks (DNNs). Phase reconstruction is a task of recovering phase of the short-time Fourier transform (STFT) coefficients only from the corresponding magnitude. However, phase is sensitive to waveform shifts and not easy to estimate from the magnitude even with a DNN. To overcome this problem, we propose to use DNNs for estimating differences of phase between adjacent time-frequency bins. We show that convolutional neural networks are suitable for phase difference estimation, according to the theoretical relation between partial derivatives of STFT phase and magnitude. The estimated phase differences are used for reconstructing phase by solving a weighted least squares problem in a frame-by-frame manner. In contrast to existing DNN-based phase reconstruction methods, the proposed framework is causal and does not require any iterative procedure. The experiments showed that the proposed method outperforms existing online methods and a DNN-based method for phase reconstruction.
Wearable SELD dataset: Dataset for sound event localization and detection using wearable devices around head
Feb 17, 2022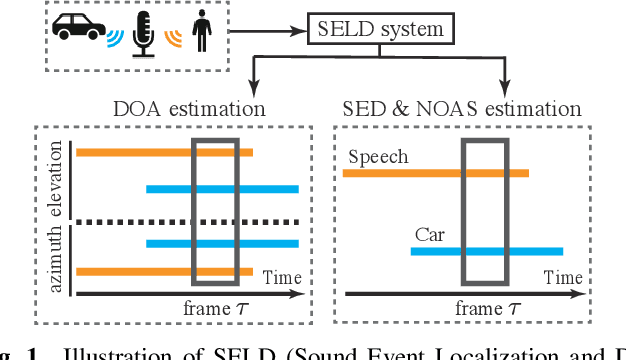
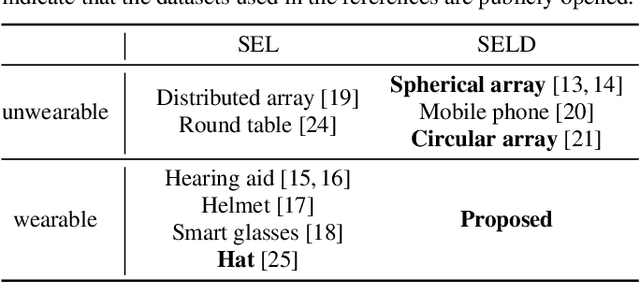
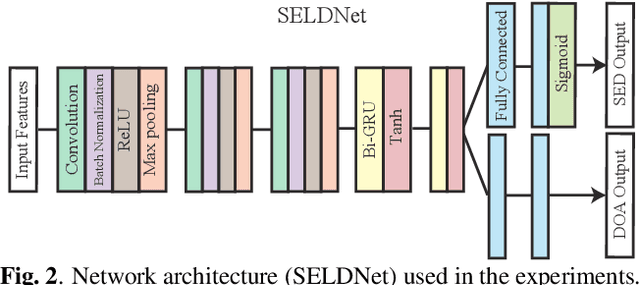
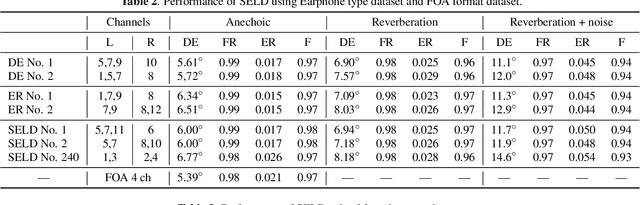
Sound event localization and detection (SELD) is a combined task of identifying the sound event and its direction. Deep neural networks (DNNs) are utilized to associate them with the sound signals observed by a microphone array. Although ambisonic microphones are popular in the literature of SELD, they might limit the range of applications due to their predetermined geometry. Some applications (including those for pedestrians that perform SELD while walking) require a wearable microphone array whose geometry can be designed to suit the task. In this paper, for the development of such a wearable SELD, we propose a dataset named Wearable SELD dataset. It consists of data recorded by 24 microphones placed on a head and torso simulators (HATS) with some accessories mimicking wearable devices (glasses, earphones, and headphones). We also provide experimental results of SELD using the proposed dataset and SELDNet to investigate the effect of microphone configuration.
APPLADE: Adjustable Plug-and-play Audio Declipper Combining DNN with Sparse Optimization
Feb 16, 2022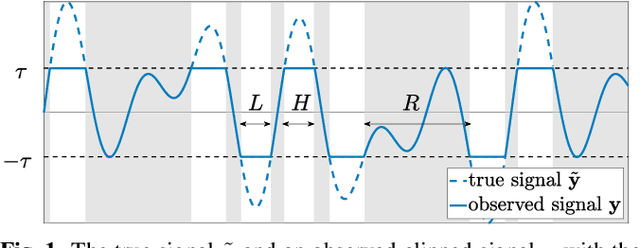
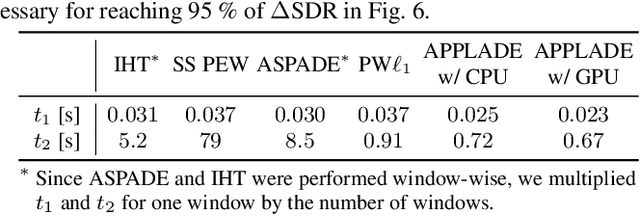
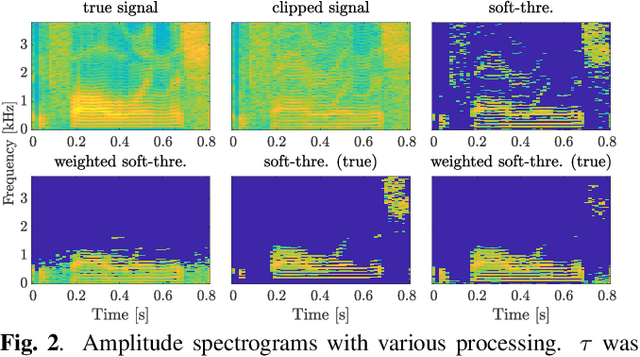
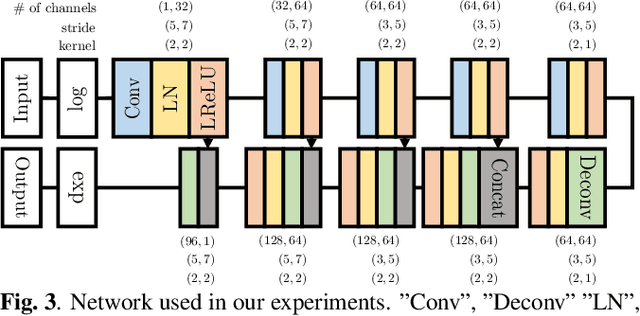
In this paper, we propose an audio declipping method that takes advantages of both sparse optimization and deep learning. Since sparsity-based audio declipping methods have been developed upon constrained optimization, they are adjustable and well-studied in theory. However, they always uniformly promote sparsity and ignore the individual properties of a signal. Deep neural network (DNN)-based methods can learn the properties of target signals and use them for audio declipping. Still, they cannot perform well if the training data have mismatches and/or constraints in the time domain are not imposed. In the proposed method, we use a DNN in an optimization algorithm. It is inspired by an idea called plug-and-play (PnP) and enables us to promote sparsity based on the learned information of data, considering constraints in the time domain. Our experiments confirmed that the proposed method is stable and robust to mismatches between training and test data.
Sparse time-frequency representation via atomic norm minimization
May 07, 2021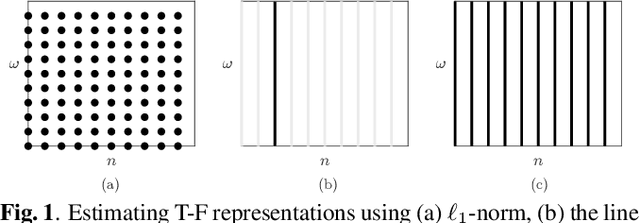
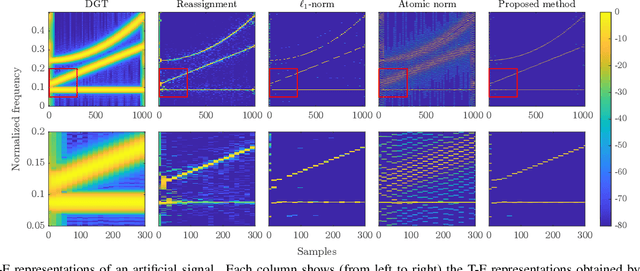
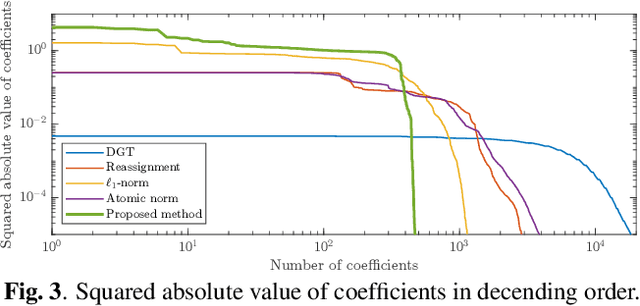
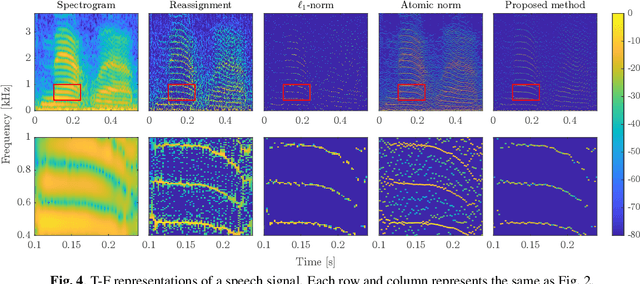
Nonstationary signals are commonly analyzed and processed in the time-frequency (T-F) domain that is obtained by the discrete Gabor transform (DGT). The T-F representation obtained by DGT is spread due to windowing, which may degrade the performance of T-F domain analysis and processing. To obtain a well-localized T-F representation, sparsity-aware methods using $\ell_1$-norm have been studied. However, they need to discretize a continuous parameter onto a grid, which causes a model mismatch. In this paper, we propose a method of estimating a sparse T-F representation using atomic norm. The atomic norm enables sparse optimization without discretization of continuous parameters. Numerical experiments show that the T-F representation obtained by the proposed method is sparser than the conventional methods.
Self-supervised Neural Audio-Visual Sound Source Localization via Probabilistic Spatial Modeling
Jul 28, 2020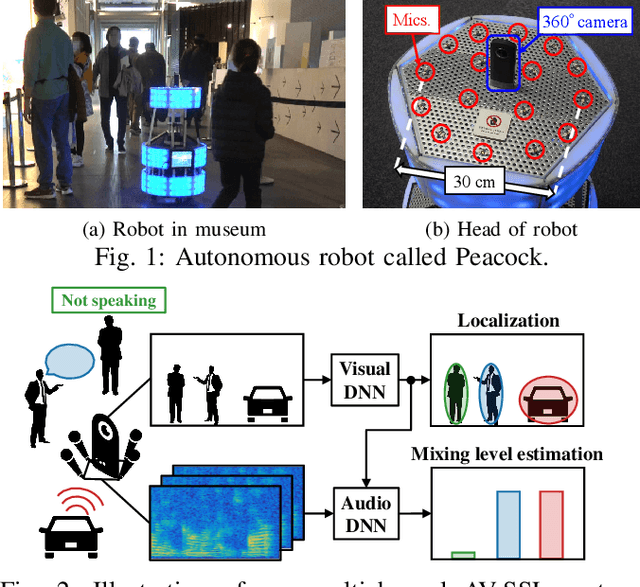

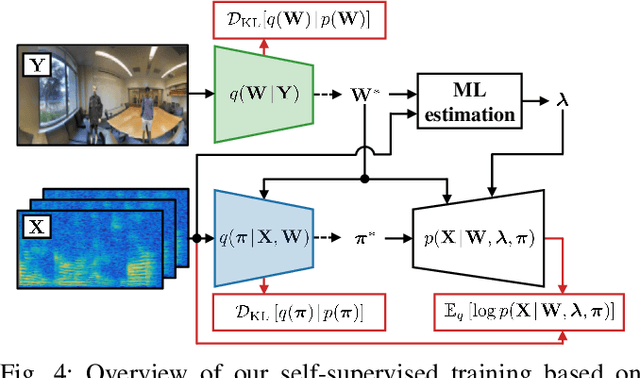

Detecting sound source objects within visual observation is important for autonomous robots to comprehend surrounding environments. Since sounding objects have a large variety with different appearances in our living environments, labeling all sounding objects is impossible in practice. This calls for self-supervised learning which does not require manual labeling. Most of conventional self-supervised learning uses monaural audio signals and images and cannot distinguish sound source objects having similar appearances due to poor spatial information in audio signals. To solve this problem, this paper presents a self-supervised training method using 360{\deg} images and multichannel audio signals. By incorporating with the spatial information in multichannel audio signals, our method trains deep neural networks (DNNs) to distinguish multiple sound source objects. Our system for localizing sound source objects in the image is composed of audio and visual DNNs. The visual DNN is trained to localize sound source candidates within an input image. The audio DNN verifies whether each candidate actually produces sound or not. These DNNs are jointly trained in a self-supervised manner based on a probabilistic spatial audio model. Experimental results with simulated data showed that the DNNs trained by our method localized multiple speakers. We also demonstrate that the visual DNN detected objects including talking visitors and specific exhibits from real data recorded in a science museum.
Deep Griffin-Lim Iteration
Mar 10, 2019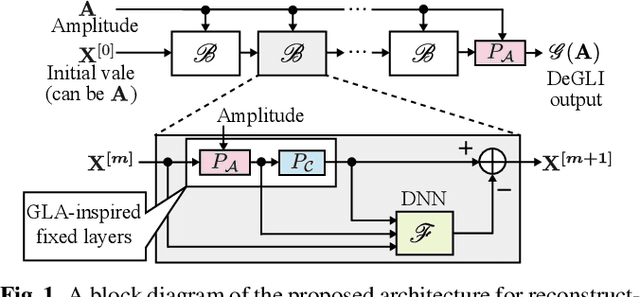
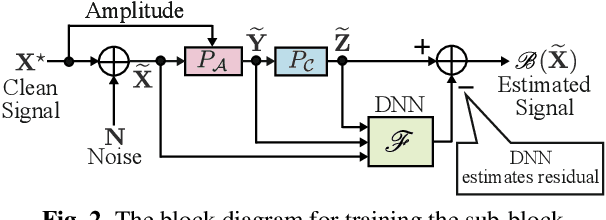
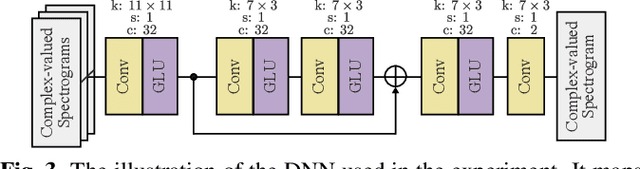
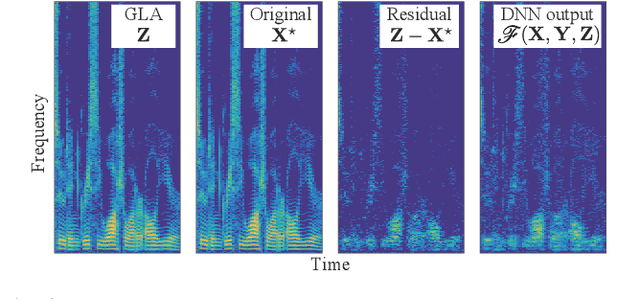
This paper presents a novel phase reconstruction method (only from a given amplitude spectrogram) by combining a signal-processing-based approach and a deep neural network (DNN). To retrieve a time-domain signal from its amplitude spectrogram, the corresponding phase is required. One of the popular phase reconstruction methods is the Griffin-Lim algorithm (GLA), which is based on the redundancy of the short-time Fourier transform. However, GLA often involves many iterations and produces low-quality signals owing to the lack of prior knowledge of the target signal. In order to address these issues, in this study, we propose an architecture which stacks a sub-block including two GLA-inspired fixed layers and a DNN. The number of stacked sub-blocks is adjustable, and we can trade the performance and computational load based on requirements of applications. The effectiveness of the proposed method is investigated by reconstructing phases from amplitude spectrograms of speeches.