 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoundSil-DS: Deep Denoising and Segmentation of Sound-field Images with Silhouettes
Nov 12, 2024Development of optical technology has enabled imaging of two-dimensional (2D) sound fields. This acousto-optic sensing enables understanding of the interaction between sound and objects such as reflection and diffraction. Moreover, it is expected to be used an advanced measurement technology for sonars in self-driving vehicles and assistive robots. However, the low sound-pressure sensitivity of the acousto-optic sensing results in high intensity of noise on images. Therefore, denoising is an essential task to visualize and analyze the sound fields. In addition to denoising, segmentation of sound and object silhouette is also required to analyze interactions between them. In this paper, we propose sound-field-images-with-object-silhouette denoising and segmentation (SoundSil-DS) that jointly perform denoising and segmentation for sound fields and object silhouettes on a visualized image. We developed a new model based on the current state-of-the-art denoising network. We also created a dataset to train and evaluate the proposed method through acoustic simulation. The proposed method was evaluated using both simulated and measured data. We confirmed that our method can applied to experimentally measured data. These results suggest that the proposed method may improve the post-processing for sound fields, such as physical model-based three-dimensional reconstruction since it can remove unwanted noise and separate sound fields and other object silhouettes. Our code is available at https://github.com/nttcslab/soundsil-ds.
hear-your-action: human action recognition by ultrasound active sensing
Sep 15, 2023



Action recognition is a key technology for many industrial applications. Methods using visual information such as images are very popular. However, privacy issues prevent widespread usage due to the inclusion of private information, such as visible faces and scene backgrounds, which are not necessary for recognizing user action. In this paper, we propose a privacy-preserving action recognition by ultrasound active sensing. As action recognition from ultrasound active sensing in a non-invasive manner is not well investigated, we create a new dataset for action recognition and conduct a comparison of features for classification. We calculated feature values by focusing on the temporal variation of the amplitude of ultrasound reflected waves and performed classification using a support vector machine and VGG for eight fundamental action classes. We confirmed that our method achieved an accuracy of 97.9% when trained and evaluated on the same person and in the same environment. Additionally, our method achieved an accuracy of 89.5% even when trained and evaluated on different people. We also report the analyses of accuracies in various conditions and limitations.
Invisible-to-Visible: Privacy-Aware Human Segmentation using Airborne Ultrasound via Collaborative Learning Probabilistic U-Net
May 11, 2022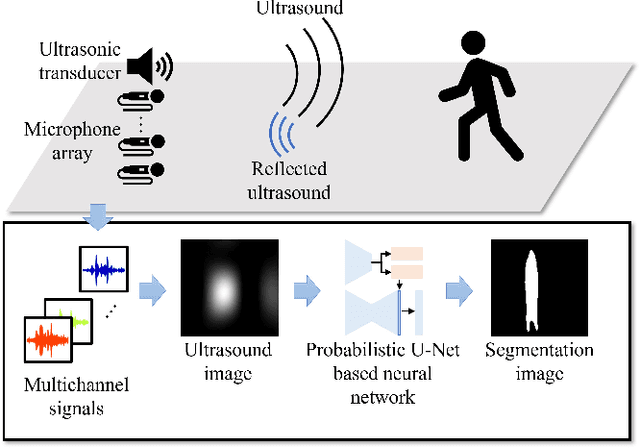

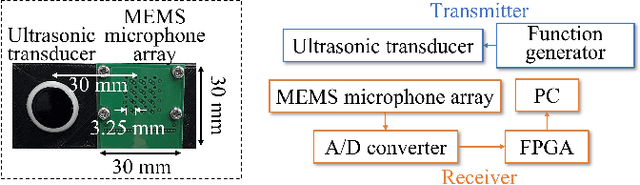
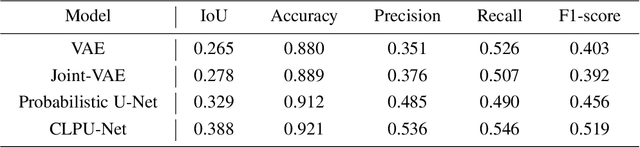
Color images are easy to understand visually and can acquire a great deal of information, such as color and texture. They are highly and widely used in tasks such as segmentation. On the other hand, in indoor person segmentation, it is necessary to collect person data considering privacy. We propose a new task for human segmentation from invisible information, especially airborne ultrasound. We first convert ultrasound waves to reflected ultrasound directional images (ultrasound images) to perform segmentation from invisible information. Although ultrasound images can roughly identify a person's location, the detailed shape is ambiguous. To address this problem, we propose a collaborative learning probabilistic U-Net that uses ultrasound and segmentation images simultaneously during training, closing the probabilistic distributions between ultrasound and segmentation images by comparing the parameters of the latent spaces. In inference, only ultrasound images can be used to obtain segmentation results. As a result of performance verification, the proposed method could estimate human segmentations more accurately than conventional probabilistic U-Net and other variational autoencoder models.
Invisible-to-Visible: Privacy-Aware Human Instance Segmentation using Airborne Ultrasound via Collaborative Learning Variational Autoencoder
Apr 15, 2022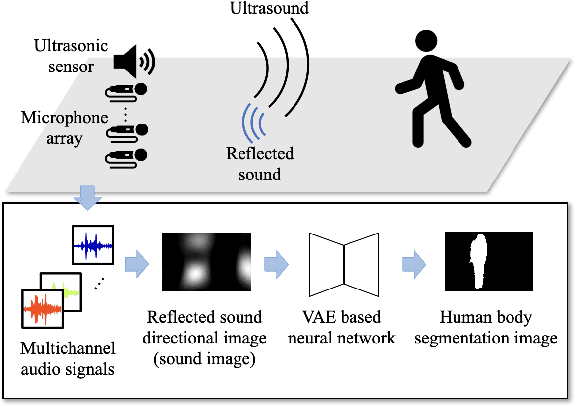
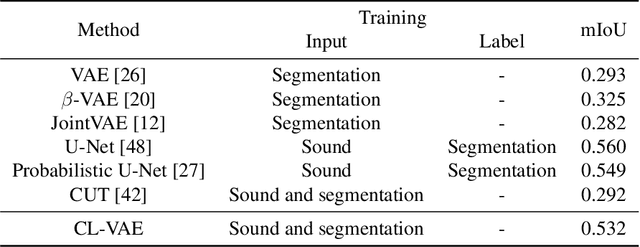
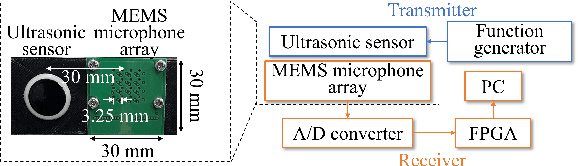

In action understanding in indoor, we have to recognize human pose and action considering privacy. Although camera images can be used for highly accurate human action recognition, camera images do not preserve privacy. Therefore, we propose a new task for human instance segmentation from invisible information, especially airborne ultrasound, for action recognition. To perform instance segmentation from invisible information, we first convert sound waves to reflected sound directional images (sound images). Although the sound images can roughly identify the location of a person, the detailed shape is ambiguous. To address this problem, we propose a collaborative learning variational autoencoder (CL-VAE) that simultaneously uses sound and RGB images during training. In inference, it is possible to obtain instance segmentation results only from sound images. As a result of performance verification, CL-VAE could estimate human instance segmentations more accurately than conventional variational autoencoder and some other models. Since this method can obtain human segmentations individually, it could be applied to human action recognition tasks with privacy protection.