 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Memory Transformer for Object Goal Navigation
Mar 24, 2022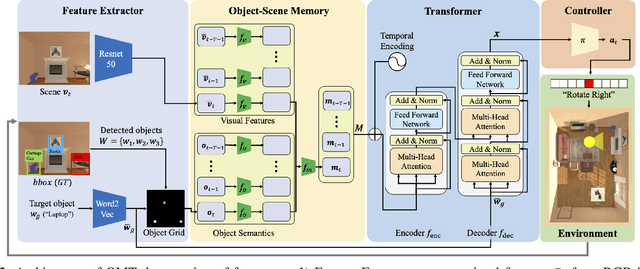
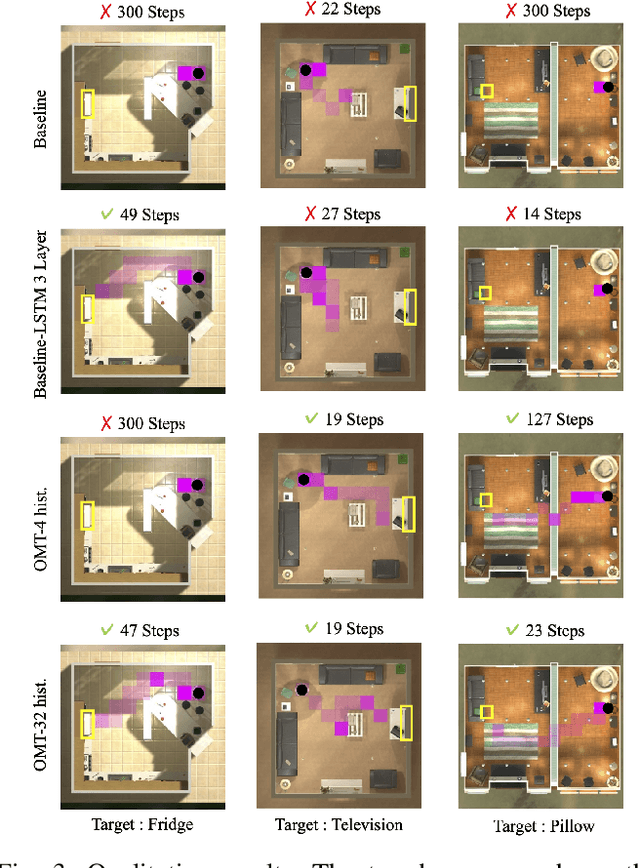
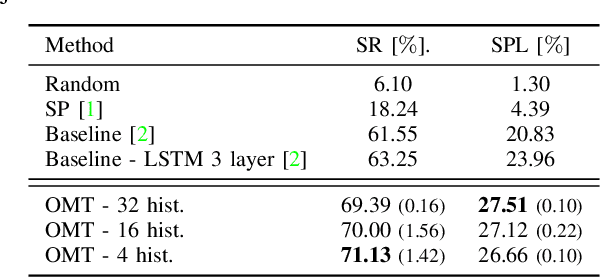
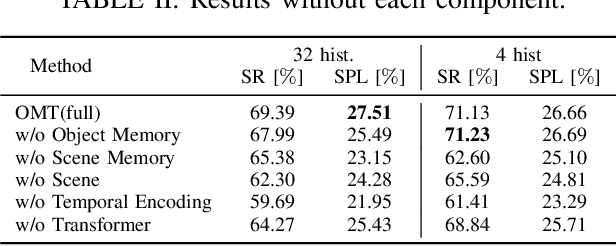
This paper presents a reinforcement learning method for object goal navigation (ObjNav) where an agent navigates in 3D indoor environments to reach a target object based on long-term observations of objects and scenes. To this end, we propose Object Memory Transformer (OMT) that consists of two key ideas: 1) Object-Scene Memory (OSM) that enables to store long-term scenes and object semantics, and 2) Transformer that attends to salient objects in the sequence of previously observed scenes and objects stored in OSM. This mechanism allows the agent to efficiently navigate in the indoor environment without prior knowledge about the environments, such as topological maps or 3D meshes. To the best of our knowledge, this is the first work that uses a long-term memory of object semantics in a goal-oriented navigation task. Experimental results conducted on the AI2-THOR dataset show that OMT outperforms previous approaches in navigating in unknown environments. In particular, we show that utilizing the long-term object semantics information improves the efficiency of navigation.
Adaptive Future Frame Prediction with Ensemble Network
Nov 16, 2020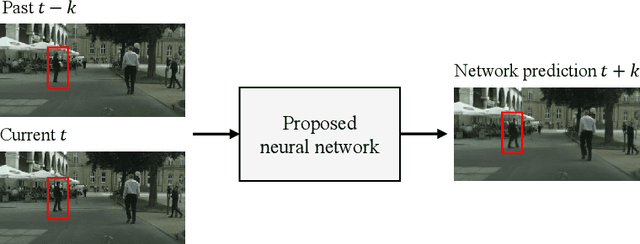
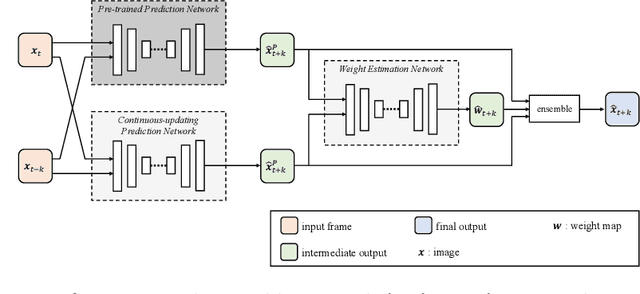

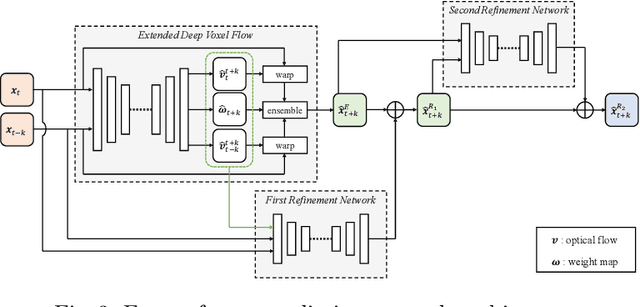
Future frame prediction in videos is a challenging problem because videos include complicated movements and large appearance changes. Learning-based future frame prediction approaches have been proposed in kinds of literature. A common limitation of the existing learning-based approaches is a mismatch of training data and test data. In the future frame prediction task, we can obtain the ground truth data by just waiting for a few frames. It means we can update the prediction model online in the test phase. Then, we propose an adaptive update framework for the future frame prediction task. The proposed adaptive updating framework consists of a pre-trained prediction network, a continuous-updating prediction network, and a weight estimation network. We also show that our pre-trained prediction model achieves comparable performance to the existing state-of-the-art approaches. We demonstrate that our approach outperforms existing methods especially for dynamically changing scenes.
Deep Reactive Planning in Dynamic Environments
Nov 05, 2020
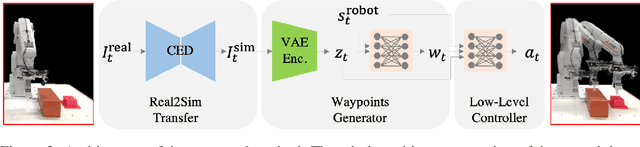


The main novelty of the proposed approach is that it allows a robot to learn an end-to-end policy which can adapt to changes in the environment during execution. While goal conditioning of policies has been studied in the RL literature, such approaches are not easily extended to cases where the robot's goal can change during execution. This is something that humans are naturally able to do. However, it is difficult for robots to learn such reflexes (i.e., to naturally respond to dynamic environments), especially when the goal location is not explicitly provided to the robot, and instead needs to be perceived through a vision sensor. In the current work, we present a method that can achieve such behavior by combining traditional kinematic planning, deep learning, and deep reinforcement learning in a synergistic fashion to generalize to arbitrary environments. We demonstrate the proposed approach for several reaching and pick-and-place tasks in simulation, as well as on a real system of a 6-DoF industrial manipulator. A video describing our work could be found \url{https://youtu.be/hE-Ew59GRPQ}.
Self-supervised Neural Audio-Visual Sound Source Localization via Probabilistic Spatial Modeling
Jul 28, 2020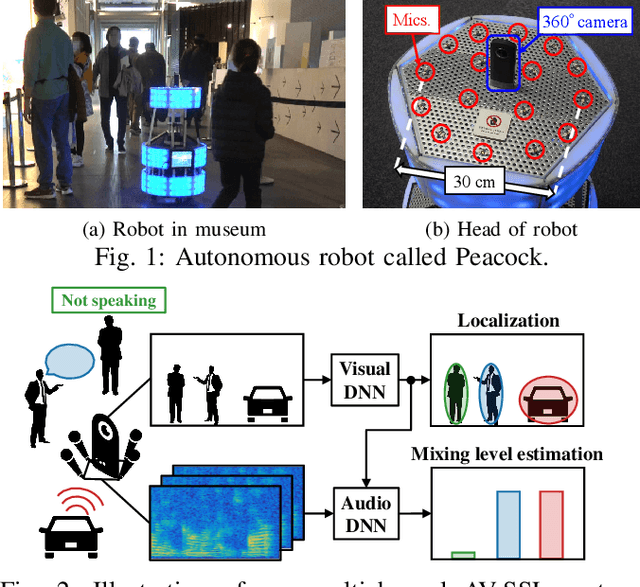

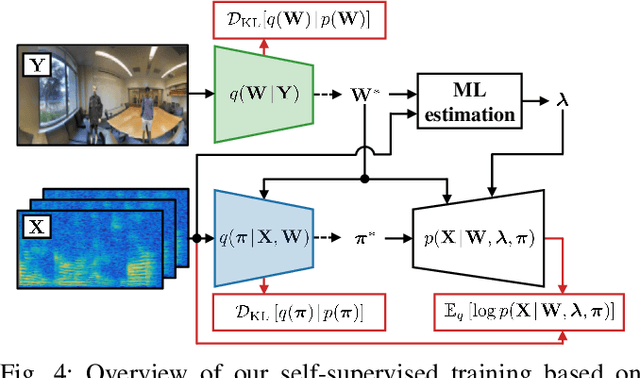

Detecting sound source objects within visual observation is important for autonomous robots to comprehend surrounding environments. Since sounding objects have a large variety with different appearances in our living environments, labeling all sounding objects is impossible in practice. This calls for self-supervised learning which does not require manual labeling. Most of conventional self-supervised learning uses monaural audio signals and images and cannot distinguish sound source objects having similar appearances due to poor spatial information in audio signals. To solve this problem, this paper presents a self-supervised training method using 360{\deg} images and multichannel audio signals. By incorporating with the spatial information in multichannel audio signals, our method trains deep neural networks (DNNs) to distinguish multiple sound source objects. Our system for localizing sound source objects in the image is composed of audio and visual DNNs. The visual DNN is trained to localize sound source candidates within an input image. The audio DNN verifies whether each candidate actually produces sound or not. These DNNs are jointly trained in a self-supervised manner based on a probabilistic spatial audio model. Experimental results with simulated data showed that the DNNs trained by our method localized multiple speakers. We also demonstrate that the visual DNN detected objects including talking visitors and specific exhibits from real data recorded in a science museum.
3D Object Detection Method Based on YOLO and K-Means for Image and Point Clouds
Apr 21, 2020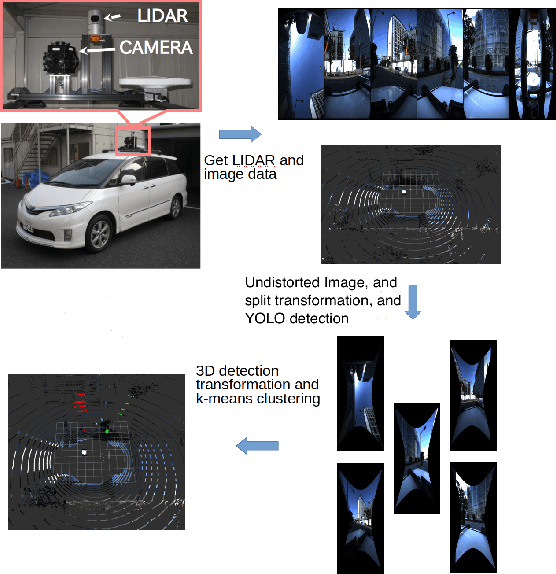


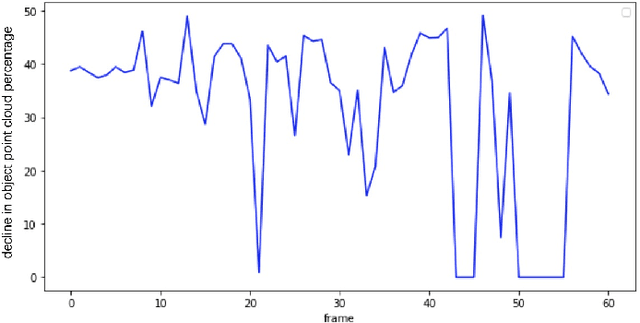
Lidar based 3D object detection and classification tasks are essential for autonomous driving(AD). A lidar sensor can provide the 3D point cloud data reconstruction of the surrounding environment. However, real time detection in 3D point clouds still needs a strong algorithmic. This paper proposes a 3D object detection method based on point cloud and image which consists of there parts.(1)Lidar-camera calibration and undistorted image transformation. (2)YOLO-based detection and PointCloud extraction, (3)K-means based point cloud segmentation and detection experiment test and evaluation in depth image. In our research, camera can capture the image to make the Real-time 2D object detection by using YOLO, we transfer the bounding box to node whose function is making 3d object detection on point cloud data from Lidar. By comparing whether 2D coordinate transferred from the 3D point is in the object bounding box or not can achieve High-speed 3D object recognition function in GPU. The accuracy and precision get imporved after k-means clustering in point cloud. The speed of our detection method is a advantage faster than PointNet.
Learning-Based Human Segmentation and Velocity Estimation Using Automatic Labeled LiDAR Sequence for Training
Mar 11, 2020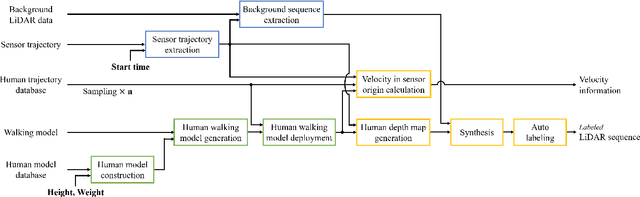

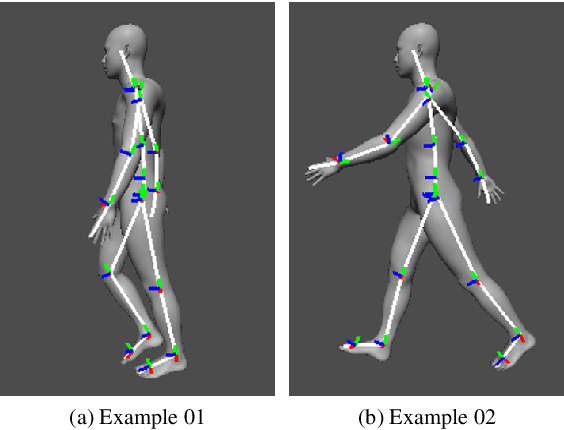

In this paper, we propose an automatic labeled sequential data generation pipeline for human segmentation and velocity estimation with point clouds. Considering the impact of deep neural networks, state-of-the-art network architectures have been proposed for human recognition using point clouds captured by Light Detection and Ranging (LiDAR). However, one disadvantage is that legacy datasets may only cover the image domain without providing important label information and this limitation has disturbed the progress of research to date. Therefore, we develop an automatic labeled sequential data generation pipeline, in which we can control any parameter or data generation environment with pixel-wise and per-frame ground truth segmentation and pixel-wise velocity information for human recognition. Our approach uses a precise human model and reproduces a precise motion to generate realistic artificial data. We present more than 7K video sequences which consist of 32 frames generated by the proposed pipeline. With the proposed sequence generator, we confirm that human segmentation performance is improved when using the video domain compared to when using the image domain. We also evaluate our data by comparing with data generated under different conditions. In addition, we estimate pedestrian velocity with LiDAR by only utilizing data generated by the proposed pipeline.
Efficient Exploration in Constrained Environments with Goal-Oriented Reference Path
Mar 03, 2020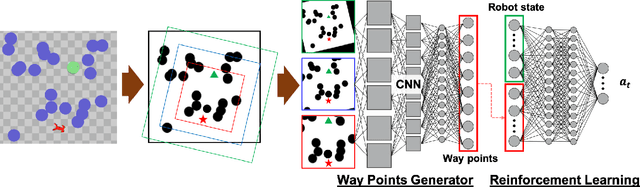
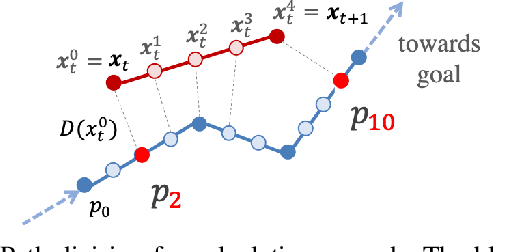
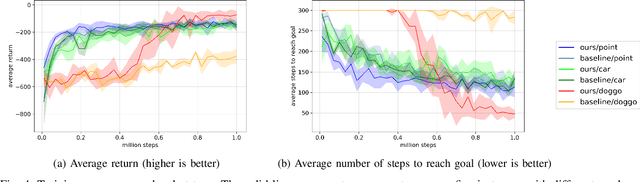
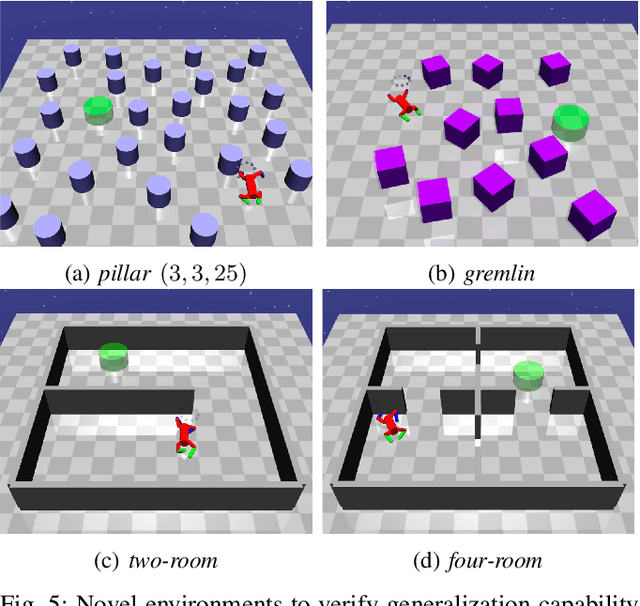
In this paper, we consider the problem of building learning agents that can efficiently learn to navigate in constrained environments. The main goal is to design agents that can efficiently learn to understand and generalize to different environments using high-dimensional inputs (a 2D map), while following feasible paths that avoid obstacles in obstacle-cluttered environment. To achieve this, we make use of traditional path planning algorithms, supervised learning, and reinforcement learning algorithms in a synergistic way. The key idea is to decouple the navigation problem into planning and control, the former of which is achieved by supervised learning whereas the latter is done by reinforcement learning. Specifically, we train a deep convolutional network that can predict collision-free paths based on a map of the environment-- this is then used by a reinforcement learning algorithm to learn to closely follow the path. This allows the trained agent to achieve good generalization while learning faster. We test our proposed method in the recently proposed Safety Gym suite that allows testing of safety-constraints during training of learning agents. We compare our proposed method with existing work and show that our method consistently improves the sample efficiency and generalization capability to novel environments.
Deep Bayesian Unsupervised Source Separation Based on a Complex Gaussian Mixture Model
Aug 29, 2019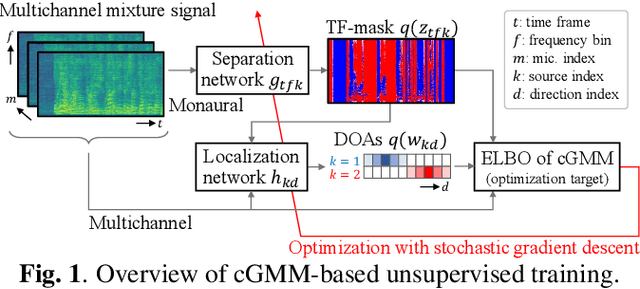
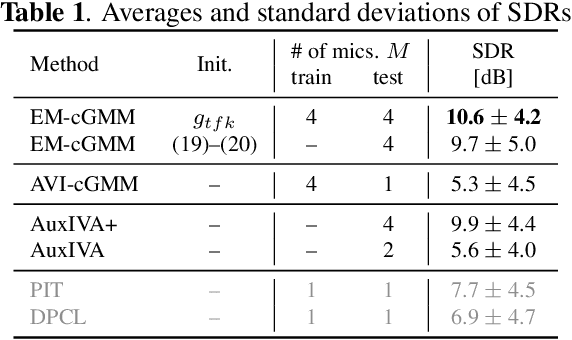
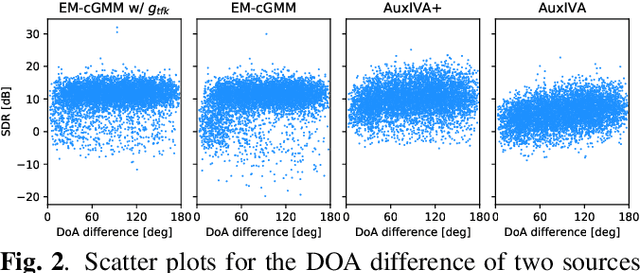

This paper presents an unsupervised method that trains neural source separation by using only multichannel mixture signals. Conventional neural separation methods require a lot of supervised data to achieve excellent performance. Although multichannel methods based on spatial information can work without such training data, they are often sensitive to parameter initialization and degraded with the sources located close to each other. The proposed method uses a cost function based on a spatial model called a complex Gaussian mixture model (cGMM). This model has the time-frequency (TF) masks and direction of arrivals (DoAs) of sources as latent variables and is used for training separation and localization networks that respectively estimate these variables. This joint training solves the frequency permutation ambiguity of the spatial model in a unified deep Bayesian framework. In addition, the pre-trained network can be used not only for conducting monaural separation but also for efficiently initializing a multichannel separation algorithm. Experimental results with simulated speech mixtures showed that our method outperformed a conventional initialization method.
Automatic Labeled LiDAR Data Generation based on Precise Human Model
Feb 14, 2019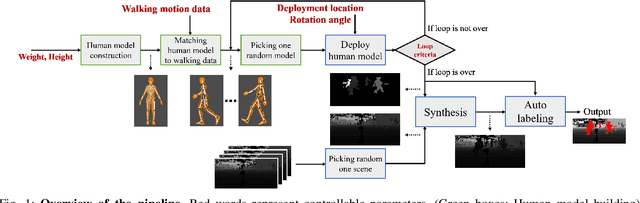
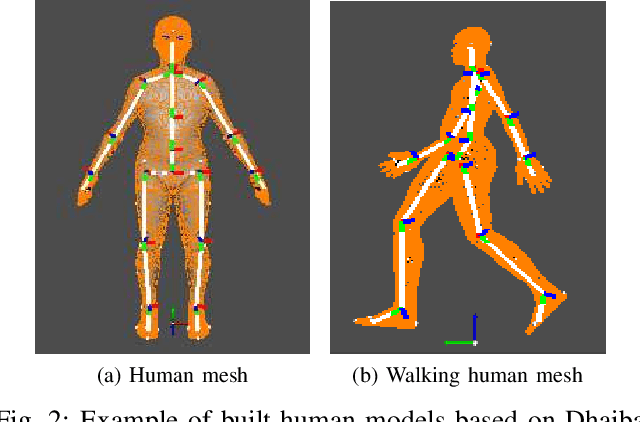

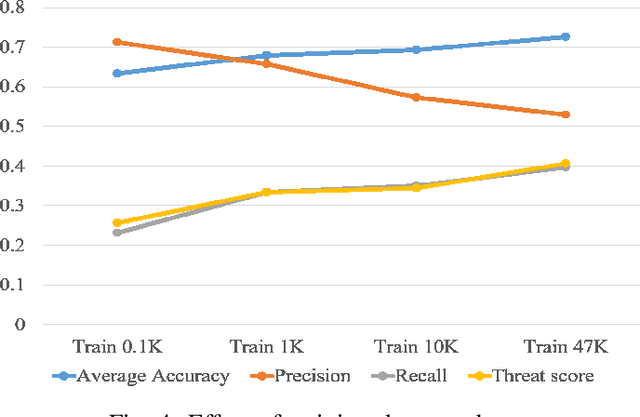
Following improvements in deep neural networks, state-of-the-art networks have been proposed for human recognition using point clouds captured by LiDAR. However, the performance of these networks strongly depends on the training data. An issue with collecting training data is labeling. Labeling by humans is necessary to obtain the ground truth label; however, labeling requires huge costs. Therefore, we propose an automatic labeled data generation pipeline, for which we can change any parameters or data generation environments. Our approach uses a human model named Dhaiba and a background of Miraikan and consequently generated realistic artificial data. We present 500k+ data generated by the proposed pipeline. This paper also describes the specification of the pipeline and data details with evaluations of various approaches.