 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-Based Human Segmentation and Velocity Estimation Using Automatic Labeled LiDAR Sequence for Training
Paper and Code
Mar 11, 2020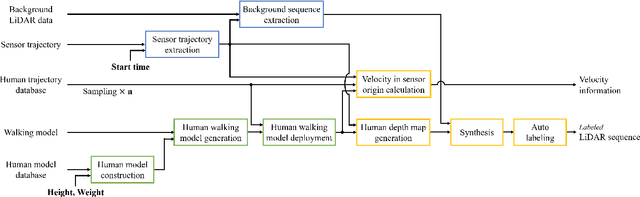

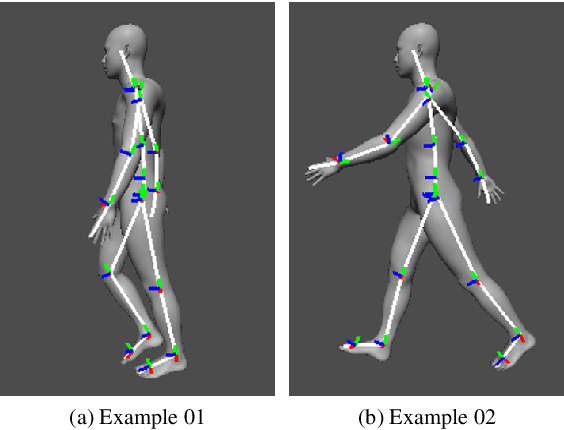

In this paper, we propose an automatic labeled sequential data generation pipeline for human segmentation and velocity estimation with point clouds. Considering the impact of deep neural networks, state-of-the-art network architectures have been proposed for human recognition using point clouds captured by Light Detection and Ranging (LiDAR). However, one disadvantage is that legacy datasets may only cover the image domain without providing important label information and this limitation has disturbed the progress of research to date. Therefore, we develop an automatic labeled sequential data generation pipeline, in which we can control any parameter or data generation environment with pixel-wise and per-frame ground truth segmentation and pixel-wise velocity information for human recognition. Our approach uses a precise human model and reproduces a precise motion to generate realistic artificial data. We present more than 7K video sequences which consist of 32 frames generated by the proposed pipeline. With the proposed sequence generator, we confirm that human segmentation performance is improved when using the video domain compared to when using the image domain. We also evaluate our data by comparing with data generated under different conditions. In addition, we estimate pedestrian velocity with LiDAR by only utilizing data generated by the proposed pipeline.