 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRectified Lagrangian for Out-of-Distribution Detection in Modern Hopfield Networks
Feb 19, 2025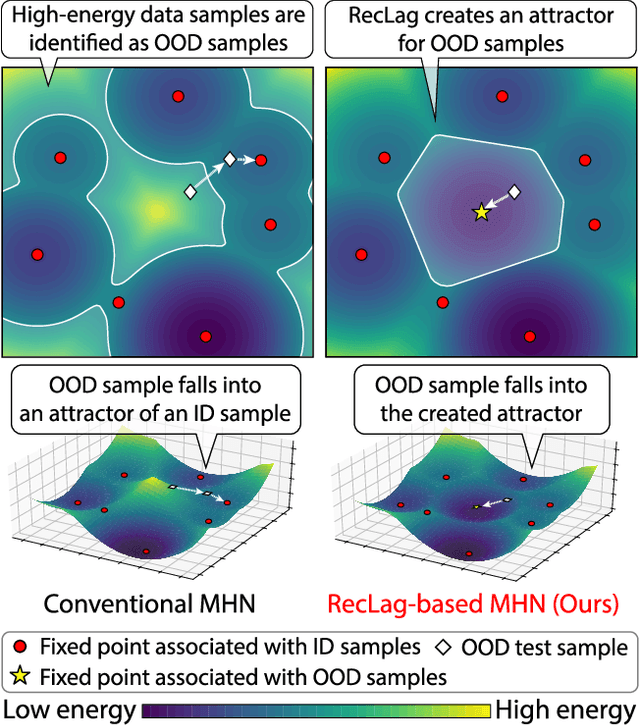
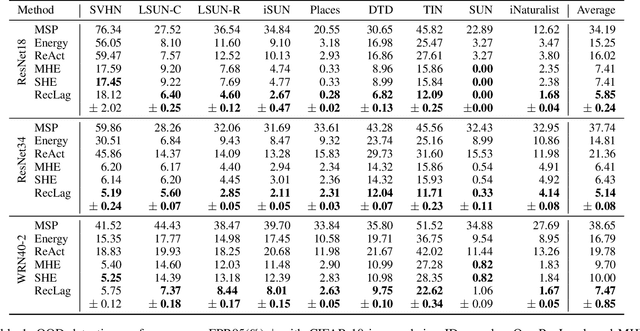
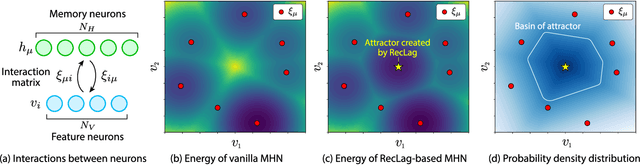
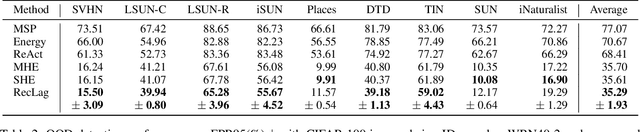
Modern Hopfield networks (MHNs) have recently gained significant attention in the field of artificial intelligence because they can store and retrieve a large set of patterns with an exponentially large memory capacity. A MHN is generally a dynamical system defined with Lagrangians of memory and feature neurons, where memories associated with in-distribution (ID) samples are represented by attractors in the feature space. One major problem in existing MHNs lies in managing out-of-distribution (OOD) samples because it was originally assumed that all samples are ID samples. To address this, we propose the rectified Lagrangian (RegLag), a new Lagrangian for memory neurons that explicitly incorporates an attractor for OOD samples in the dynamical system of MHNs. RecLag creates a trivial point attractor for any interaction matrix, enabling OOD detection by identifying samples that fall into this attractor as OOD. The interaction matrix is optimized so that the probability densities can be estimated to identify ID/OOD. We demonstrate the effectiveness of RecLag-based MHNs compared to energy-based OOD detection methods, including those using state-of-the-art Hopfield energies, across nine image datasets.
Adaptive Adversarial Cross-Entropy Loss for Sharpness-Aware Minimization
Jun 20, 2024



Recent advancements in learning algorithms have demonstrated that the sharpness of the loss surface is an effective measure for improving the generalization gap. Building upon this concept, Sharpness-Aware Minimization (SAM) was proposed to enhance model generalization and achieved state-of-the-art performance. SAM consists of two main steps, the weight perturbation step and the weight updating step. However, the perturbation in SAM is determined by only the gradient of the training loss, or cross-entropy loss. As the model approaches a stationary point, this gradient becomes small and oscillates, leading to inconsistent perturbation directions and also has a chance of diminishing the gradient. Our research introduces an innovative approach to further enhancing model generalization. We propose the Adaptive Adversarial Cross-Entropy (AACE) loss function to replace standard cross-entropy loss for SAM's perturbation. AACE loss and its gradient uniquely increase as the model nears convergence, ensuring consistent perturbation direction and addressing the gradient diminishing issue. Additionally, a novel perturbation-generating function utilizing AACE loss without normalization is proposed, enhancing the model's exploratory capabilities in near-optimum stages. Empirical testing confirms the effectiveness of AACE, with experiments demonstrating improved performance in image classification tasks using Wide ResNet and PyramidNet across various datasets. The reproduction code is available online
Hyperspectral Image Dataset for Individual Penguin Identification
May 23, 2024



Remote individual animal identification is important for food safety, sport, and animal conservation. Numerous existing remote individual animal identification studies have focused on RGB images. In this paper, we tackle individual penguin identification using hyperspectral (HS) images. To the best of our knowledge, it is the first work to analyze spectral differences between penguin individuals using an HS camera. We have constructed a novel penguin HS image dataset, including 990 hyperspectral images of 27 penguins. We experimentally demonstrate that the spectral information of HS image pixels can be used for individual penguin identification. The experimental results show the effectiveness of using HS images for individual penguin identification. The dataset and source code are available here: https://033labcodes.github.io/igrass24_penguin/
Two-Step Color-Polarization Demosaicking Network
Sep 13, 2022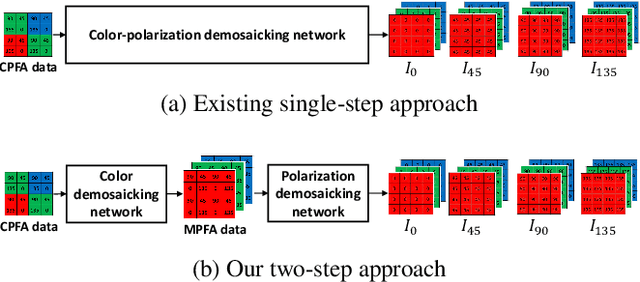
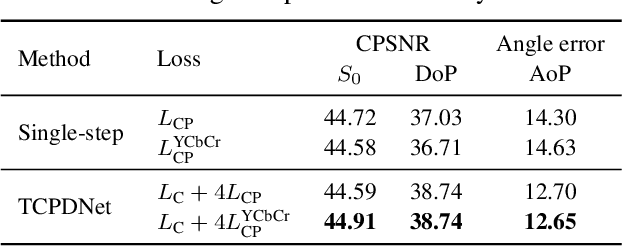
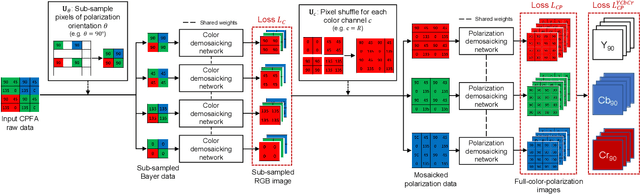
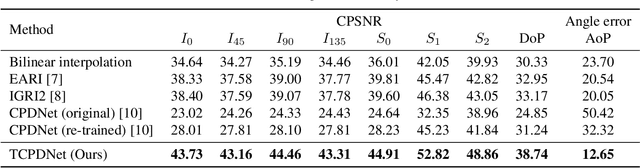
Polarization information of light in a scene is valuable for various image processing and computer vision tasks. A division-of-focal-plane polarimeter is a promising approach to capture the polarization images of different orientations in one shot, while it requires color-polarization demosaicking. In this paper, we propose a two-step color-polarization demosaicking network~(TCPDNet), which consists of two sub-tasks of color demosaicking and polarization demosaicking. We also introduce a reconstruction loss in the YCbCr color space to improve the performance of TCPDNet. Experimental comparisons demonstrate that TCPDNet outperforms existing methods in terms of the image quality of polarization images and the accuracy of Stokes parameters.
PoF: Post-Training of Feature Extractor for Improving Generalization
Jul 05, 2022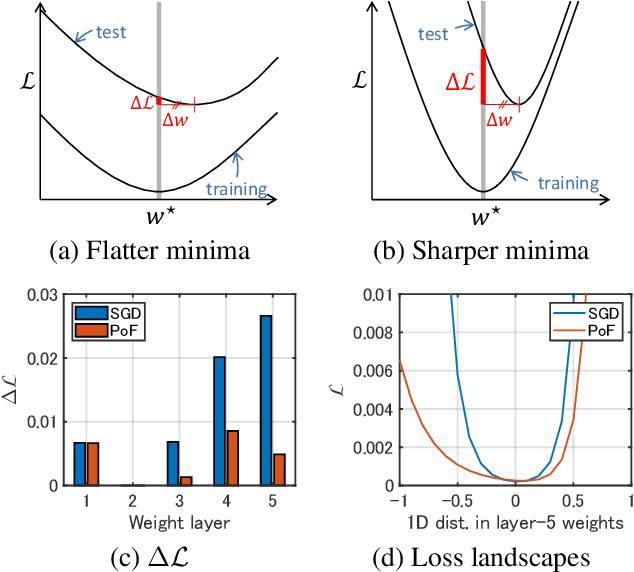
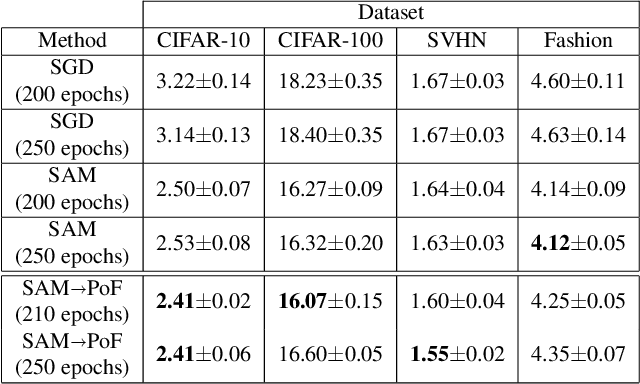
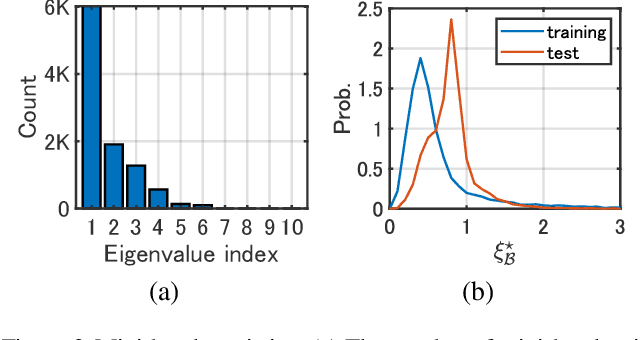
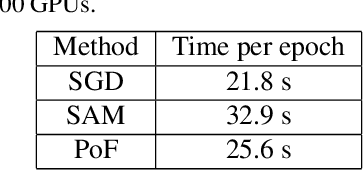
It has been intensively investigated that the local shape, especially flatness, of the loss landscape near a minimum plays an important role for generalization of deep models. We developed a training algorithm called PoF: Post-Training of Feature Extractor that updates the feature extractor part of an already-trained deep model to search a flatter minimum. The characteristics are two-fold: 1) Feature extractor is trained under parameter perturbations in the higher-layer parameter space, based on observations that suggest flattening higher-layer parameter space, and 2) the perturbation range is determined in a data-driven manner aiming to reduce a part of test loss caused by the positive loss curvature. We provide a theoretical analysis that shows the proposed algorithm implicitly reduces the target Hessian components as well as the loss. Experimental results show that PoF improved model performance against baseline methods on both CIFAR-10 and CIFAR-100 datasets for only 10-epoch post-training, and on SVHN dataset for 50-epoch post-training. Source code is available at: \url{https://github.com/DensoITLab/PoF-v1
Multi-Modal Pedestrian Detection with Large Misalignment Based on Modal-Wise Regression and Multi-Modal IoU
Jul 23, 2021
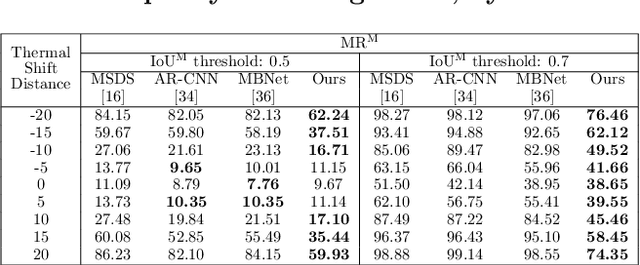
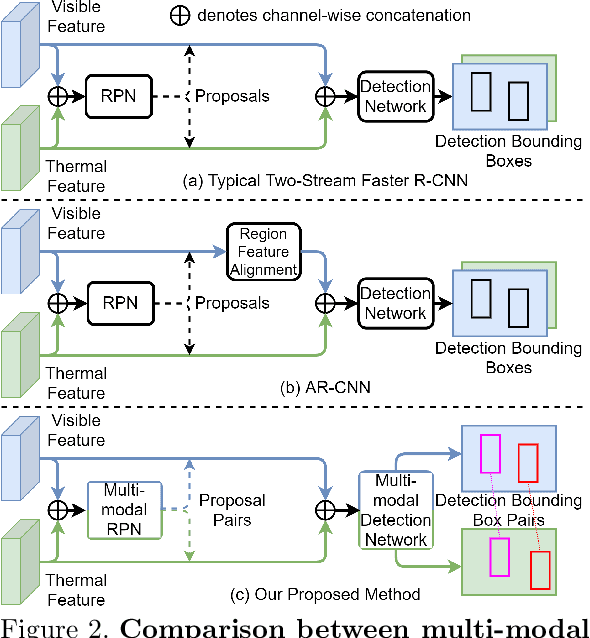
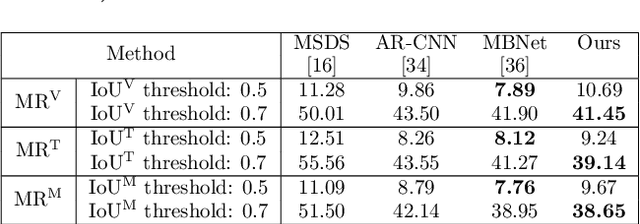
The combined use of multiple modalities enables accurate pedestrian detection under poor lighting conditions by using the high visibility areas from these modalities together. The vital assumption for the combination use is that there is no or only a weak misalignment between the two modalities. In general, however, this assumption often breaks in actual situations. Due to this assumption's breakdown, the position of the bounding boxes does not match between the two modalities, resulting in a significant decrease in detection accuracy, especially in regions where the amount of misalignment is large. In this paper, we propose a multi-modal Faster-RCNN that is robust against large misalignment. The keys are 1) modal-wise regression and 2) multi-modal IoU for mini-batch sampling. To deal with large misalignment, we perform bounding box regression for both the RPN and detection-head with both modalities. We also propose a new sampling strategy called "multi-modal mini-batch sampling" that integrates the IoU for both modalities. We demonstrate that the proposed method's performance is much better than that of the state-of-the-art methods for data with large misalignment through actual image experiments.
Geometric Data Augmentation Based on Feature Map Ensemble
Jul 22, 2021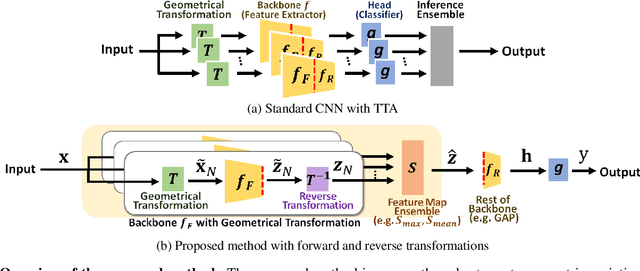

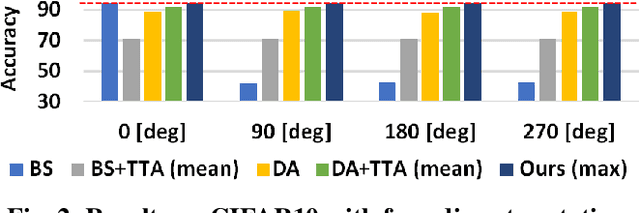
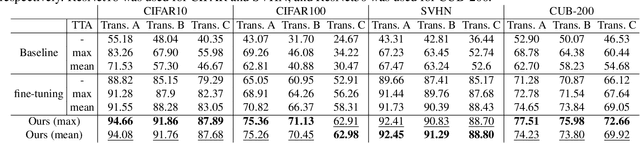
Deep convolutional networks have become the mainstream in computer vision applications. Although CNNs have been successful in many computer vision tasks, it is not free from drawbacks. The performance of CNN is dramatically degraded by geometric transformation, such as large rotations. In this paper, we propose a novel CNN architecture that can improve the robustness against geometric transformations without modifying the existing backbones of their CNNs. The key is to enclose the existing backbone with a geometric transformation (and the corresponding reverse transformation) and a feature map ensemble. The proposed method can inherit the strengths of existing CNNs that have been presented so far. Furthermore, the proposed method can be employed in combination with state-of-the-art data augmentation algorithms to improve their performance. We demonstrate the effectiveness of the proposed method using standard datasets such as CIFAR, CUB-200, and Mnist-rot-12k.
Deep Snapshot HDR Imaging Using Multi-Exposure Color Filter Array
Nov 20, 2020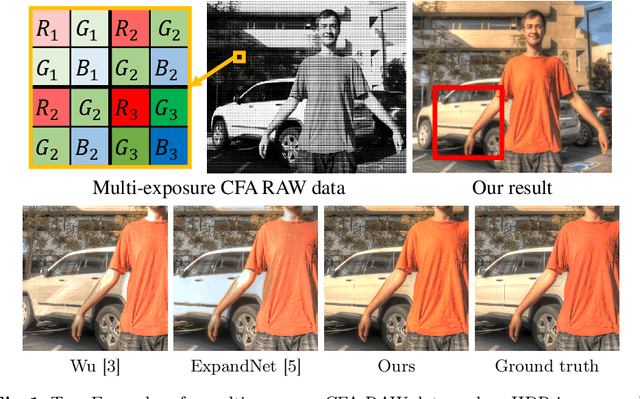

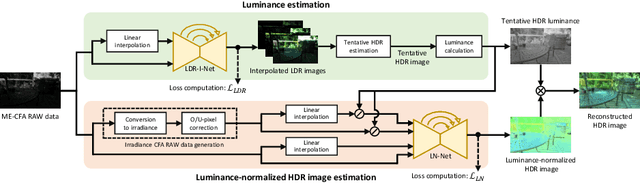

In this paper, we propose a deep snapshot high dynamic range (HDR) imaging framework that can effectively reconstruct an HDR image from the RAW data captured using a multi-exposure color filter array (ME-CFA), which consists of a mosaic pattern of RGB filters with different exposure levels. To effectively learn the HDR image reconstruction network, we introduce the idea of luminance normalization that simultaneously enables effective loss computation and input data normalization by considering relative local contrasts in the "normalized-by-luminance" HDR domain. This idea makes it possible to equally handle the errors in both bright and dark areas regardless of absolute luminance levels, which significantly improves the visual image quality in a tone-mapped domain. Experimental results using two public HDR image datasets demonstrate that our framework outperforms other snapshot methods and produces high-quality HDR images with fewer visual artifacts.
Adaptive Future Frame Prediction with Ensemble Network
Nov 16, 2020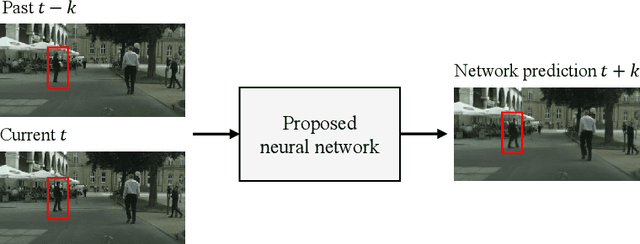
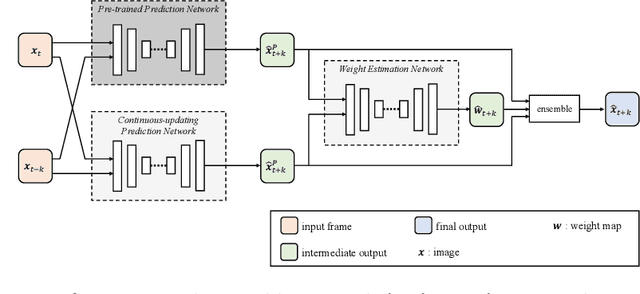

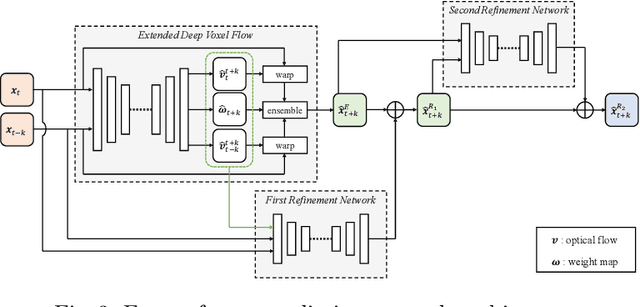
Future frame prediction in videos is a challenging problem because videos include complicated movements and large appearance changes. Learning-based future frame prediction approaches have been proposed in kinds of literature. A common limitation of the existing learning-based approaches is a mismatch of training data and test data. In the future frame prediction task, we can obtain the ground truth data by just waiting for a few frames. It means we can update the prediction model online in the test phase. Then, we propose an adaptive update framework for the future frame prediction task. The proposed adaptive updating framework consists of a pre-trained prediction network, a continuous-updating prediction network, and a weight estimation network. We also show that our pre-trained prediction model achieves comparable performance to the existing state-of-the-art approaches. We demonstrate that our approach outperforms existing methods especially for dynamically changing scenes.
Human Segmentation with Dynamic LiDAR Data
Oct 16, 2020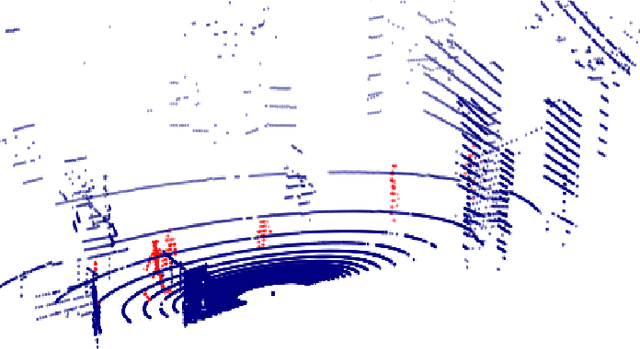
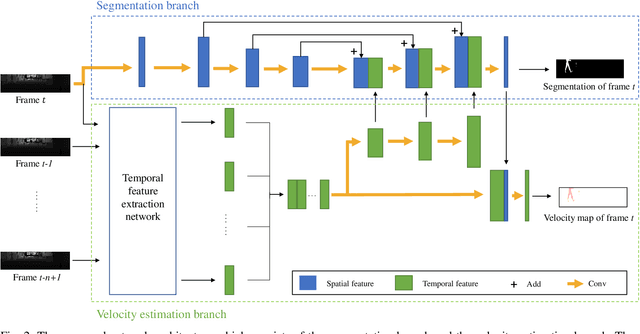
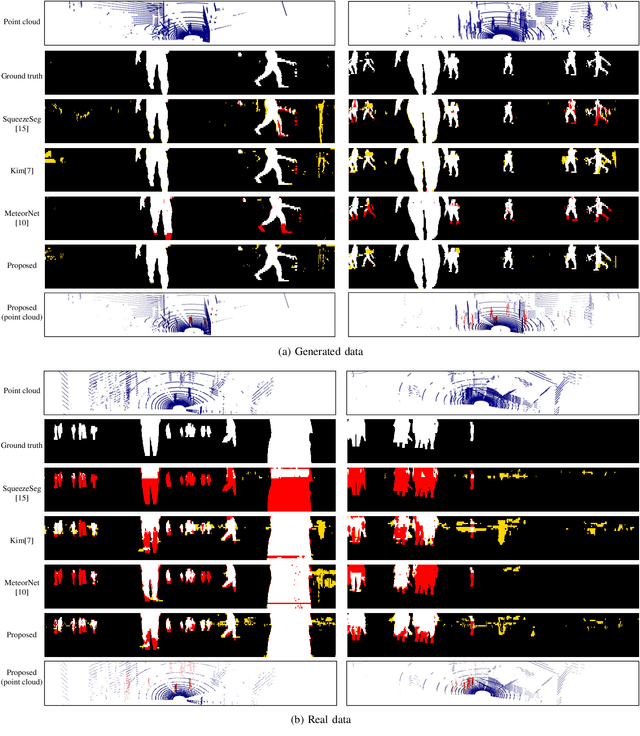
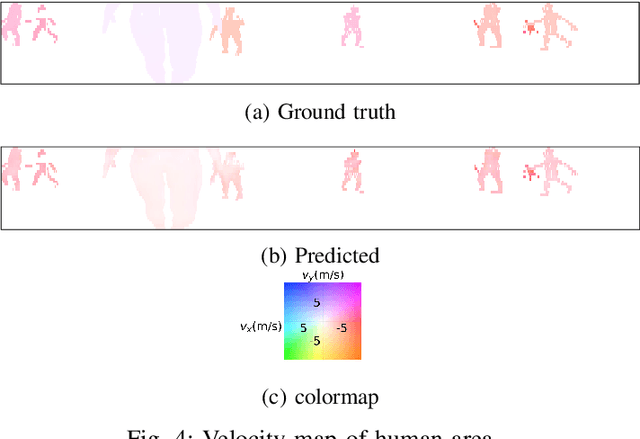
Consecutive LiDAR scans compose dynamic 3D sequences, which contain more abundant information than a single frame. Similar to the development history of image and video perception, dynamic 3D sequence perception starts to come into sight after inspiring research on static 3D data perception. This work proposes a spatio-temporal neural network for human segmentation with the dynamic LiDAR point clouds. It takes a sequence of depth images as input. It has a two-branch structure, i.e., the spatial segmentation branch and the temporal velocity estimation branch. The velocity estimation branch is designed to capture motion cues from the input sequence and then propagates them to the other branch. So that the segmentation branch segments humans according to both spatial and temporal features. These two branches are jointly learned on a generated dynamic point cloud dataset for human recognition. Our works fill in the blank of dynamic point cloud perception with the spherical representation of point cloud and achieves high accuracy. The experiments indicate that the introduction of temporal feature benefits the segmentation of dynamic point cloud.