 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS-DPPs: Multi-Source Determinantal Point Processes for Contextual Diversity Refinement of Composite Attributes in Text to Image Retrieval
Jul 09, 2025
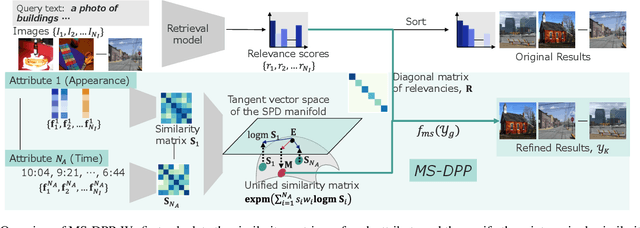
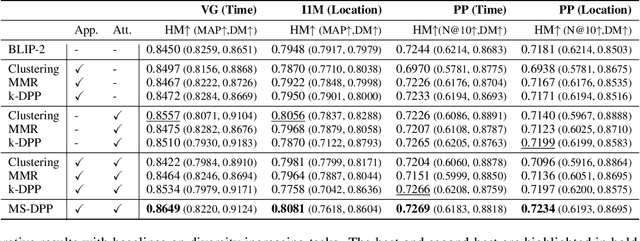
Result diversification (RD) is a crucial technique in Text-to-Image Retrieval for enhancing the efficiency of a practical application. Conventional methods focus solely on increasing the diversity metric of image appearances. However, the diversity metric and its desired value vary depending on the application, which limits the applications of RD. This paper proposes a novel task called CDR-CA (Contextual Diversity Refinement of Composite Attributes). CDR-CA aims to refine the diversities of multiple attributes, according to the application's context. To address this task, we propose Multi-Source DPPs, a simple yet strong baseline that extends the Determinantal Point Process (DPP) to multi-sources. We model MS-DPP as a single DPP model with a unified similarity matrix based on a manifold representation. We also introduce Tangent Normalization to reflect contexts. Extensive experiments demonstrate the effectiveness of the proposed method. Our code is publicly available at https://github.com/NEC-N-SOGI/msdpp.
Action-Agnostic Point-Level Supervision for Temporal Action Detection
Dec 30, 2024

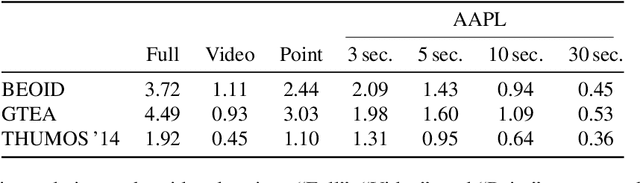
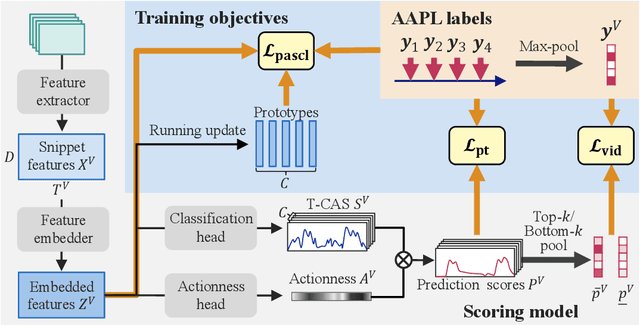
We propose action-agnostic point-level (AAPL) supervision for temporal action detection to achieve accurate action instance detection with a lightly annotated dataset. In the proposed scheme, a small portion of video frames is sampled in an unsupervised manner and presented to human annotators, who then label the frames with action categories. Unlike point-level supervision, which requires annotators to search for every action instance in an untrimmed video, frames to annotate are selected without human intervention in AAPL supervision. We also propose a detection model and learning method to effectively utilize the AAPL labels. Extensive experiments on the variety of datasets (THUMOS '14, FineAction, GTEA, BEOID, and ActivityNet 1.3) demonstrate that the proposed approach is competitive with or outperforms prior methods for video-level and point-level supervision in terms of the trade-off between the annotation cost and detection performance.
Black-Box Forgetting
Nov 01, 2024Large-scale pre-trained models (PTMs) provide remarkable zero-shot classification capability covering a wide variety of object classes. However, practical applications do not always require the classification of all kinds of objects, and leaving the model capable of recognizing unnecessary classes not only degrades overall accuracy but also leads to operational disadvantages. To mitigate this issue, we explore the selective forgetting problem for PTMs, where the task is to make the model unable to recognize only the specified classes while maintaining accuracy for the rest. All the existing methods assume "white-box" settings, where model information such as architectures, parameters, and gradients is available for training. However, PTMs are often "black-box," where information on such models is unavailable for commercial reasons or social responsibilities. In this paper, we address a novel problem of selective forgetting for black-box models, named Black-Box Forgetting, and propose an approach to the problem. Given that information on the model is unavailable, we optimize the input prompt to decrease the accuracy of specified classes through derivative-free optimization. To avoid difficult high-dimensional optimization while ensuring high forgetting performance, we propose Latent Context Sharing, which introduces common low-dimensional latent components among multiple tokens for the prompt. Experiments on four standard benchmark datasets demonstrate the superiority of our method with reasonable baselines. The code is available at https://github.com/yusukekwn/Black-Box-Forgetting.
Object-Aware Query Perturbation for Cross-Modal Image-Text Retrieval
Jul 17, 2024
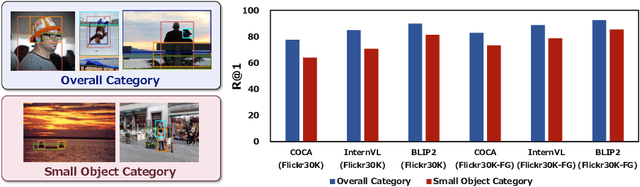
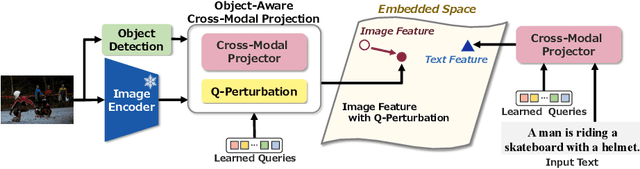
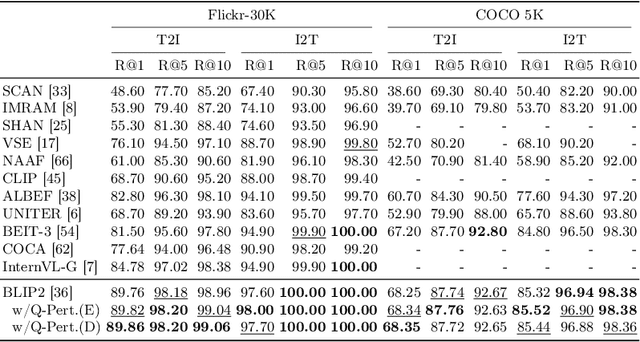
The pre-trained vision and language (V\&L) models have substantially improved the performance of cross-modal image-text retrieval. In general, however, V\&L models have limited retrieval performance for small objects because of the rough alignment between words and the small objects in the image. In contrast, it is known that human cognition is object-centric, and we pay more attention to important objects, even if they are small. To bridge this gap between the human cognition and the V\&L model's capability, we propose a cross-modal image-text retrieval framework based on ``object-aware query perturbation.'' The proposed method generates a key feature subspace of the detected objects and perturbs the corresponding queries using this subspace to improve the object awareness in the image. In our proposed method, object-aware cross-modal image-text retrieval is possible while keeping the rich expressive power and retrieval performance of existing V\&L models without additional fine-tuning. Comprehensive experiments on four public datasets show that our method outperforms conventional algorithms.
Future Predictive Success-or-Failure Classification for Long-Horizon Robotic Tasks
Apr 04, 2024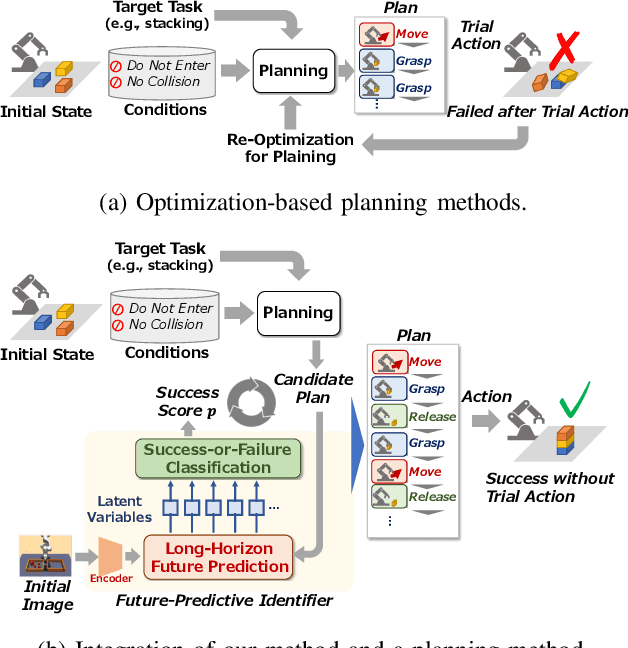
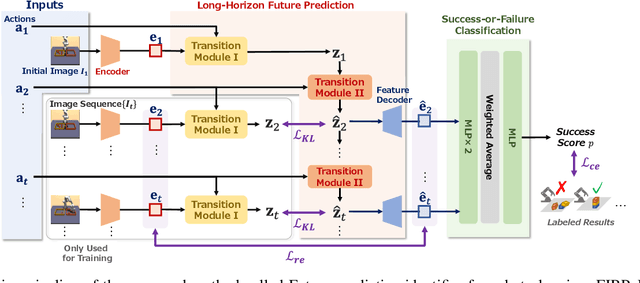
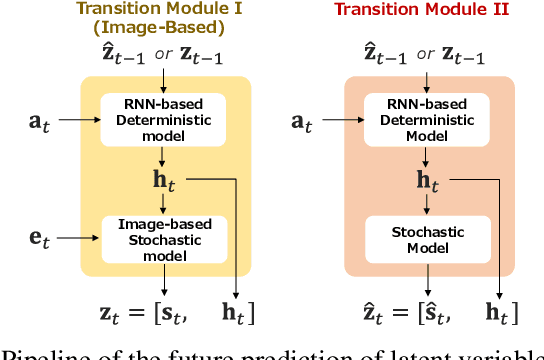
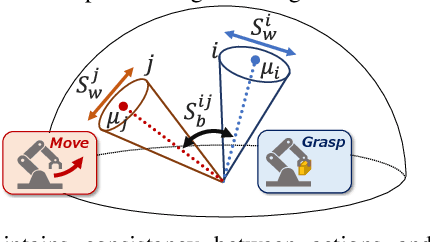
Automating long-horizon tasks with a robotic arm has been a central research topic in robotics. Optimization-based action planning is an efficient approach for creating an action plan to complete a given task. Construction of a reliable planning method requires a design process of conditions, e.g., to avoid collision between objects. The design process, however, has two critical issues: 1) iterative trials--the design process is time-consuming due to the trial-and-error process of modifying conditions, and 2) manual redesign--it is difficult to cover all the necessary conditions manually. To tackle these issues, this paper proposes a future-predictive success-or-failure-classification method to obtain conditions automatically. The key idea behind the proposed method is an end-to-end approach for determining whether the action plan can complete a given task instead of manually redesigning the conditions. The proposed method uses a long-horizon future-prediction method to enable success-or-failure classification without the execution of an action plan. This paper also proposes a regularization term called transition consistency regularization to provide easy-to-predict feature distribution. The regularization term improves future prediction and classification performance. The effectiveness of our method is demonstrated through classification and robotic-manipulation experiments.
One-Shot Machine Unlearning with Mnemonic Code
Jun 09, 2023



Deep learning has achieved significant improvements in accuracy and has been applied to various fields. With the spread of deep learning, a new problem has also emerged; deep learning models can sometimes have undesirable information from an ethical standpoint. This problem must be resolved if deep learning is to make sensitive decisions such as hiring and prison sentencing. Machine unlearning (MU) is the research area that responds to such demands. MU aims at forgetting about undesirable training data from a trained deep learning model. A naive MU approach is to re-train the whole model with the training data from which the undesirable data has been removed. However, re-training the whole model can take a huge amount of time and consumes significant computer resources. To make MU even more practical, a simple-yet-effective MU method is required. In this paper, we propose a one-shot MU method, which does not need additional training. To design one-shot MU, we add noise to the model parameters that are sensitive to undesirable information. In our proposed method, we use the Fisher information matrix (FIM) to estimate the sensitive model parameters. Training data were usually used to evaluate the FIM in existing methods. In contrast, we avoid the need to retain the training data for calculating the FIM by using class-specific synthetic signals called mnemonic code. Extensive experiments using artificial and natural datasets demonstrate that our method outperforms the existing methods.
Multi-Modal Pedestrian Detection with Large Misalignment Based on Modal-Wise Regression and Multi-Modal IoU
Jul 23, 2021
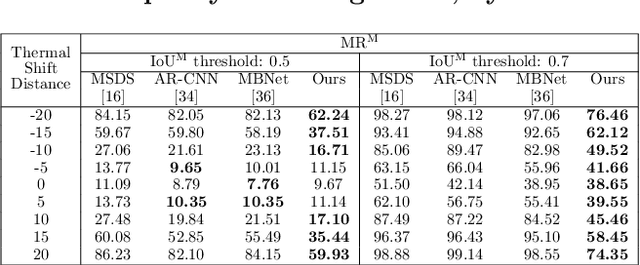
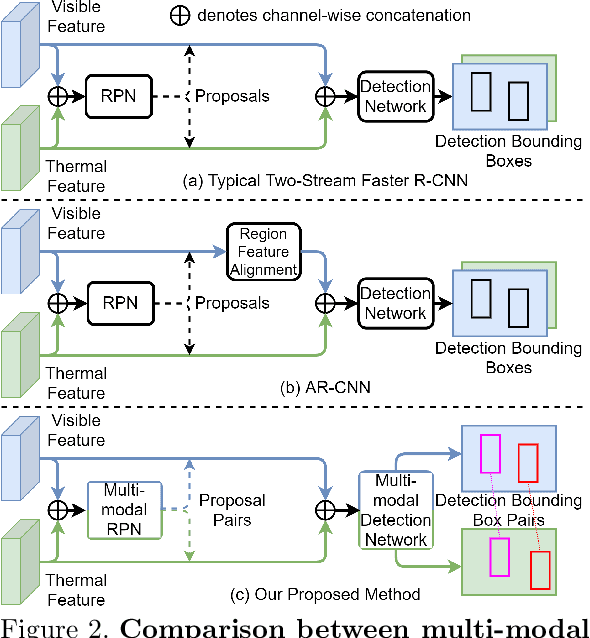
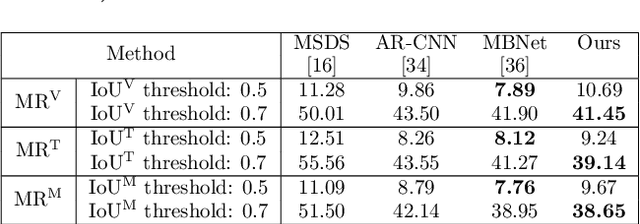
The combined use of multiple modalities enables accurate pedestrian detection under poor lighting conditions by using the high visibility areas from these modalities together. The vital assumption for the combination use is that there is no or only a weak misalignment between the two modalities. In general, however, this assumption often breaks in actual situations. Due to this assumption's breakdown, the position of the bounding boxes does not match between the two modalities, resulting in a significant decrease in detection accuracy, especially in regions where the amount of misalignment is large. In this paper, we propose a multi-modal Faster-RCNN that is robust against large misalignment. The keys are 1) modal-wise regression and 2) multi-modal IoU for mini-batch sampling. To deal with large misalignment, we perform bounding box regression for both the RPN and detection-head with both modalities. We also propose a new sampling strategy called "multi-modal mini-batch sampling" that integrates the IoU for both modalities. We demonstrate that the proposed method's performance is much better than that of the state-of-the-art methods for data with large misalignment through actual image experiments.
Geometric Data Augmentation Based on Feature Map Ensemble
Jul 22, 2021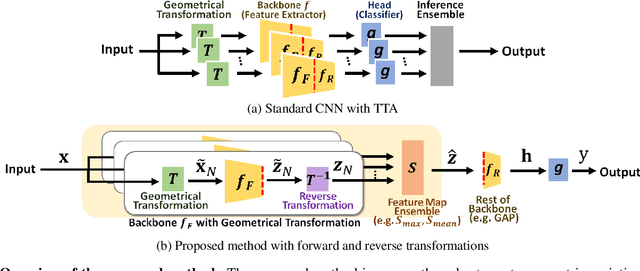

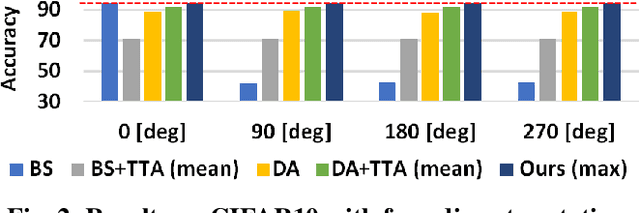
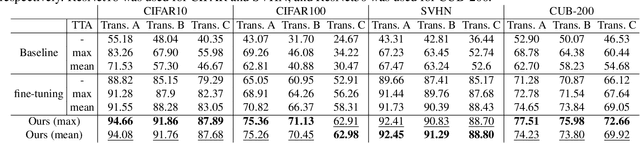
Deep convolutional networks have become the mainstream in computer vision applications. Although CNNs have been successful in many computer vision tasks, it is not free from drawbacks. The performance of CNN is dramatically degraded by geometric transformation, such as large rotations. In this paper, we propose a novel CNN architecture that can improve the robustness against geometric transformations without modifying the existing backbones of their CNNs. The key is to enclose the existing backbone with a geometric transformation (and the corresponding reverse transformation) and a feature map ensemble. The proposed method can inherit the strengths of existing CNNs that have been presented so far. Furthermore, the proposed method can be employed in combination with state-of-the-art data augmentation algorithms to improve their performance. We demonstrate the effectiveness of the proposed method using standard datasets such as CIFAR, CUB-200, and Mnist-rot-12k.
Generalized Domain Adaptation
Jun 03, 2021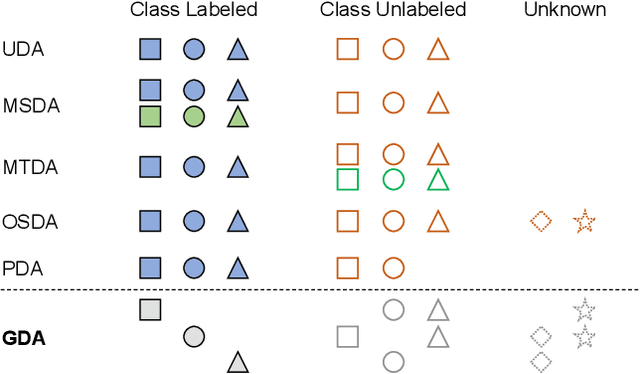

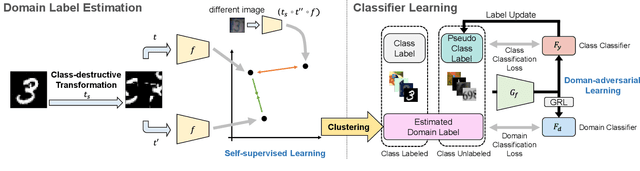
Many variants of unsupervised domain adaptation (UDA) problems have been proposed and solved individually. Its side effect is that a method that works for one variant is often ineffective for or not even applicable to another, which has prevented practical applications. In this paper, we give a general representation of UDA problems, named Generalized Domain Adaptation (GDA). GDA covers the major variants as special cases, which allows us to organize them in a comprehensive framework. Moreover, this generalization leads to a new challenging setting where existing methods fail, such as when domain labels are unknown, and class labels are only partially given to each domain. We propose a novel approach to the new setting. The key to our approach is self-supervised class-destructive learning, which enables the learning of class-invariant representations and domain-adversarial classifiers without using any domain labels. Extensive experiments using three benchmark datasets demonstrate that our method outperforms the state-of-the-art UDA methods in the new setting and that it is competitive in existing UDA variations as well.
Gradient-Based Low-Light Image Enhancement
Sep 25, 2018

A low-light image enhancement is a highly demanded image processing technique, especially for consumer digital cameras and cameras on mobile phones. In this paper, a gradient-based low-light image enhancement algorithm is proposed. The key is to enhance the gradients of dark region, because the gradients are more sensitive for human visual system than absolute values. In addition, we involve the intensity-range constraints for the image integration. By using the intensity-range constraints, we can integrate the output image with enhanced gradients preserving the given gradient information while enforcing the intensity range of the output image within a certain intensity range. Experiments demonstrate that the proposed gradient-based low-light image enhancement can effectively enhance the low-light images.