 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS-DPPs: Multi-Source Determinantal Point Processes for Contextual Diversity Refinement of Composite Attributes in Text to Image Retrieval
Jul 09, 2025
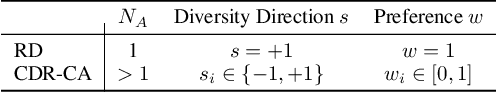
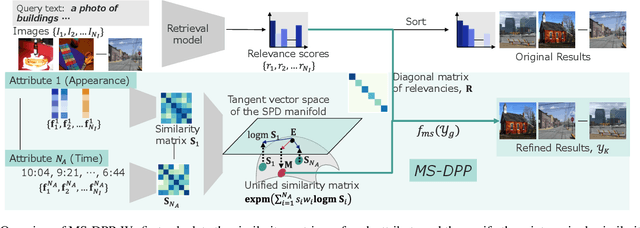
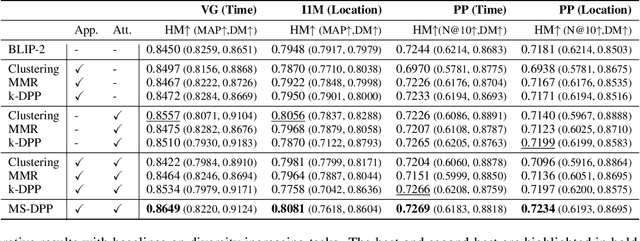
Result diversification (RD) is a crucial technique in Text-to-Image Retrieval for enhancing the efficiency of a practical application. Conventional methods focus solely on increasing the diversity metric of image appearances. However, the diversity metric and its desired value vary depending on the application, which limits the applications of RD. This paper proposes a novel task called CDR-CA (Contextual Diversity Refinement of Composite Attributes). CDR-CA aims to refine the diversities of multiple attributes, according to the application's context. To address this task, we propose Multi-Source DPPs, a simple yet strong baseline that extends the Determinantal Point Process (DPP) to multi-sources. We model MS-DPP as a single DPP model with a unified similarity matrix based on a manifold representation. We also introduce Tangent Normalization to reflect contexts. Extensive experiments demonstrate the effectiveness of the proposed method. Our code is publicly available at https://github.com/NEC-N-SOGI/msdpp.
Action-Agnostic Point-Level Supervision for Temporal Action Detection
Dec 30, 2024

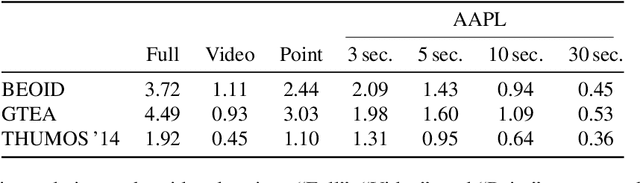
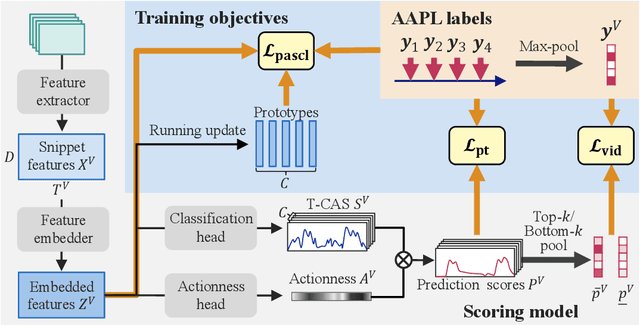
We propose action-agnostic point-level (AAPL) supervision for temporal action detection to achieve accurate action instance detection with a lightly annotated dataset. In the proposed scheme, a small portion of video frames is sampled in an unsupervised manner and presented to human annotators, who then label the frames with action categories. Unlike point-level supervision, which requires annotators to search for every action instance in an untrimmed video, frames to annotate are selected without human intervention in AAPL supervision. We also propose a detection model and learning method to effectively utilize the AAPL labels. Extensive experiments on the variety of datasets (THUMOS '14, FineAction, GTEA, BEOID, and ActivityNet 1.3) demonstrate that the proposed approach is competitive with or outperforms prior methods for video-level and point-level supervision in terms of the trade-off between the annotation cost and detection performance.
Object-Aware Query Perturbation for Cross-Modal Image-Text Retrieval
Jul 17, 2024
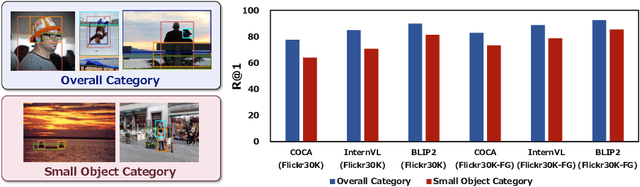
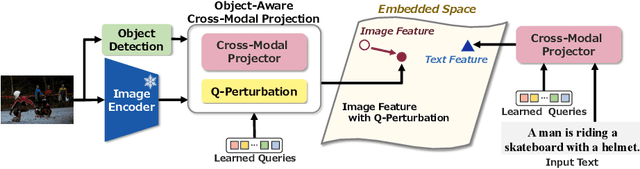
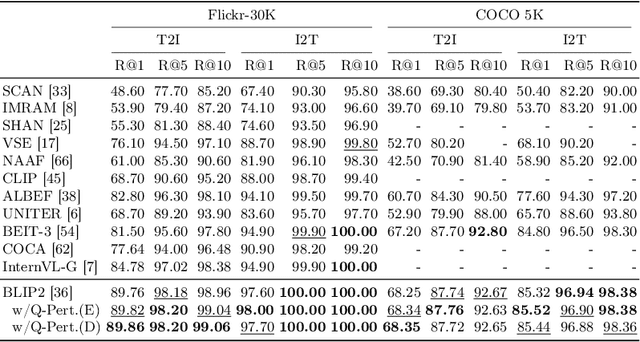
The pre-trained vision and language (V\&L) models have substantially improved the performance of cross-modal image-text retrieval. In general, however, V\&L models have limited retrieval performance for small objects because of the rough alignment between words and the small objects in the image. In contrast, it is known that human cognition is object-centric, and we pay more attention to important objects, even if they are small. To bridge this gap between the human cognition and the V\&L model's capability, we propose a cross-modal image-text retrieval framework based on ``object-aware query perturbation.'' The proposed method generates a key feature subspace of the detected objects and perturbs the corresponding queries using this subspace to improve the object awareness in the image. In our proposed method, object-aware cross-modal image-text retrieval is possible while keeping the rich expressive power and retrieval performance of existing V\&L models without additional fine-tuning. Comprehensive experiments on four public datasets show that our method outperforms conventional algorithms.
Future Predictive Success-or-Failure Classification for Long-Horizon Robotic Tasks
Apr 04, 2024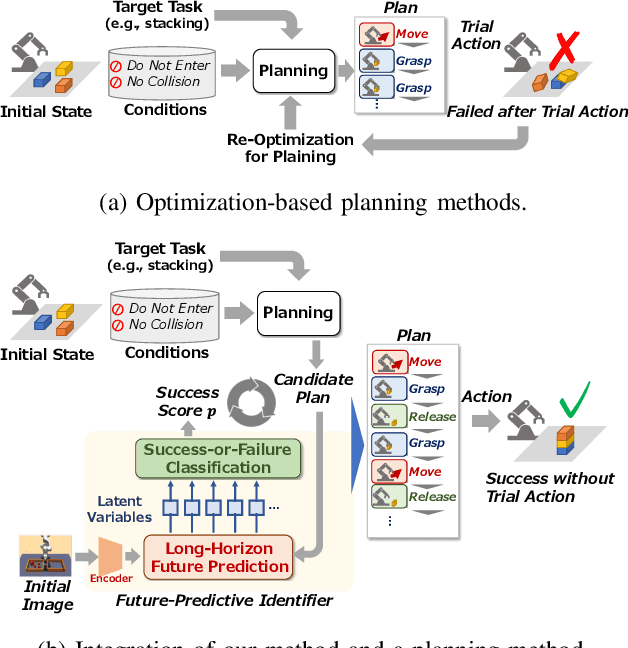
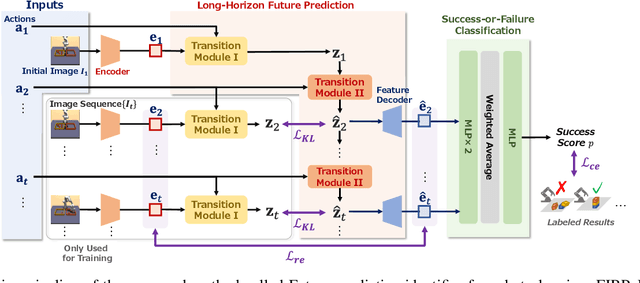
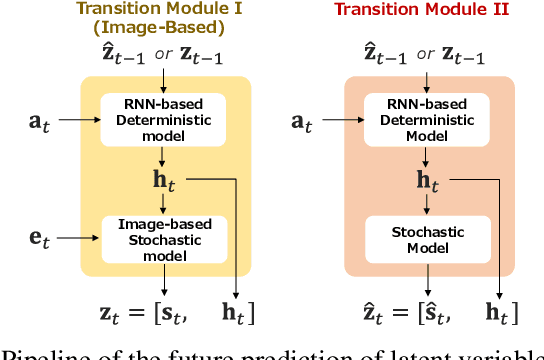
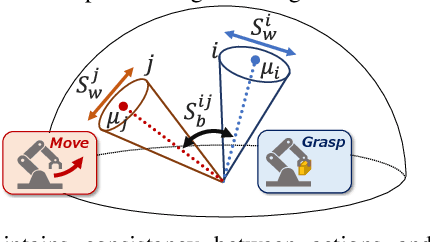
Automating long-horizon tasks with a robotic arm has been a central research topic in robotics. Optimization-based action planning is an efficient approach for creating an action plan to complete a given task. Construction of a reliable planning method requires a design process of conditions, e.g., to avoid collision between objects. The design process, however, has two critical issues: 1) iterative trials--the design process is time-consuming due to the trial-and-error process of modifying conditions, and 2) manual redesign--it is difficult to cover all the necessary conditions manually. To tackle these issues, this paper proposes a future-predictive success-or-failure-classification method to obtain conditions automatically. The key idea behind the proposed method is an end-to-end approach for determining whether the action plan can complete a given task instead of manually redesigning the conditions. The proposed method uses a long-horizon future-prediction method to enable success-or-failure classification without the execution of an action plan. This paper also proposes a regularization term called transition consistency regularization to provide easy-to-predict feature distribution. The regularization term improves future prediction and classification performance. The effectiveness of our method is demonstrated through classification and robotic-manipulation experiments.
Non-iterative optimization of pseudo-labeling thresholds for training object detection models from multiple datasets
Oct 19, 2022
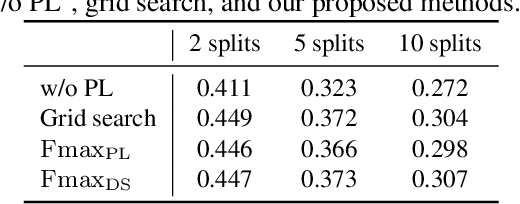
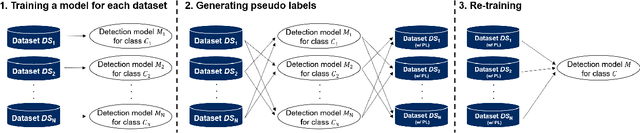
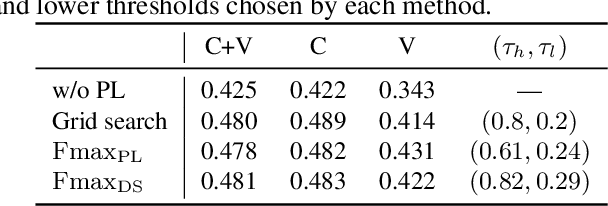
We propose a non-iterative method to optimize pseudo-labeling thresholds for learning object detection from a collection of low-cost datasets, each of which is annotated for only a subset of all the object classes. A popular approach to this problem is first to train teacher models and then to use their confident predictions as pseudo ground-truth labels when training a student model. To obtain the best result, however, thresholds for prediction confidence must be adjusted. This process typically involves iterative search and repeated training of student models and is time-consuming. Therefore, we develop a method to optimize the thresholds without iterative optimization by maximizing the $F_\beta$-score on a validation dataset, which measures the quality of pseudo labels and can be measured without training a student model. We experimentally demonstrate that our proposed method achieves an mAP comparable to that of grid search on the COCO and VOC datasets.
* ICIP2022