 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Agnostic Point-Level Supervision for Temporal Action Detection
Dec 30, 2024

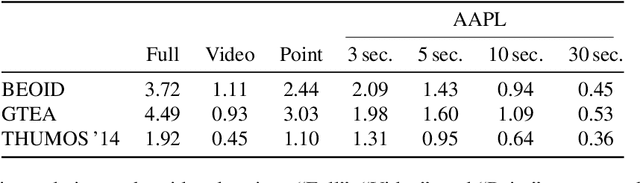
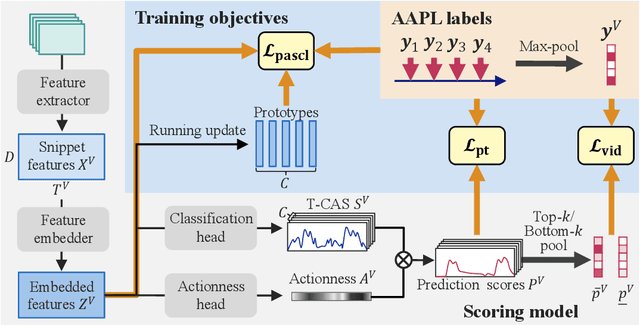
We propose action-agnostic point-level (AAPL) supervision for temporal action detection to achieve accurate action instance detection with a lightly annotated dataset. In the proposed scheme, a small portion of video frames is sampled in an unsupervised manner and presented to human annotators, who then label the frames with action categories. Unlike point-level supervision, which requires annotators to search for every action instance in an untrimmed video, frames to annotate are selected without human intervention in AAPL supervision. We also propose a detection model and learning method to effectively utilize the AAPL labels. Extensive experiments on the variety of datasets (THUMOS '14, FineAction, GTEA, BEOID, and ActivityNet 1.3) demonstrate that the proposed approach is competitive with or outperforms prior methods for video-level and point-level supervision in terms of the trade-off between the annotation cost and detection performance.
Non-iterative optimization of pseudo-labeling thresholds for training object detection models from multiple datasets
Oct 19, 2022
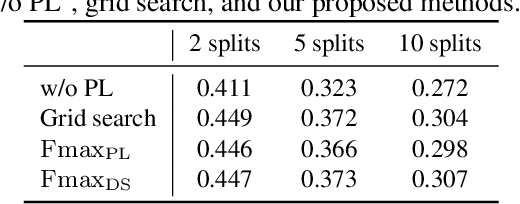
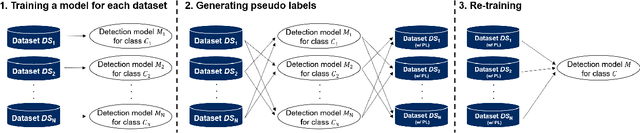
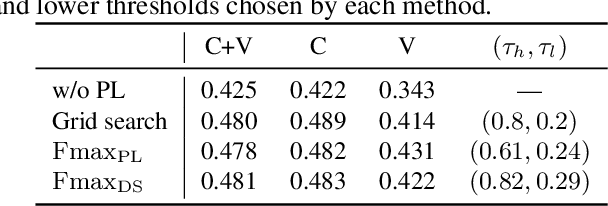
We propose a non-iterative method to optimize pseudo-labeling thresholds for learning object detection from a collection of low-cost datasets, each of which is annotated for only a subset of all the object classes. A popular approach to this problem is first to train teacher models and then to use their confident predictions as pseudo ground-truth labels when training a student model. To obtain the best result, however, thresholds for prediction confidence must be adjusted. This process typically involves iterative search and repeated training of student models and is time-consuming. Therefore, we develop a method to optimize the thresholds without iterative optimization by maximizing the $F_\beta$-score on a validation dataset, which measures the quality of pseudo labels and can be measured without training a student model. We experimentally demonstrate that our proposed method achieves an mAP comparable to that of grid search on the COCO and VOC datasets.
* ICIP2022
Lower-bounded proper losses for weakly supervised classification
Mar 04, 2021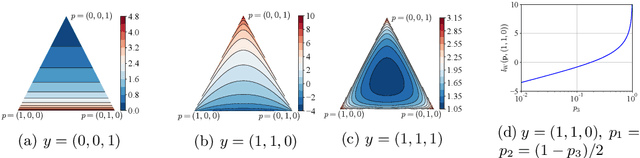
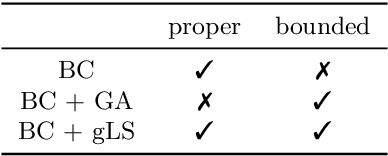

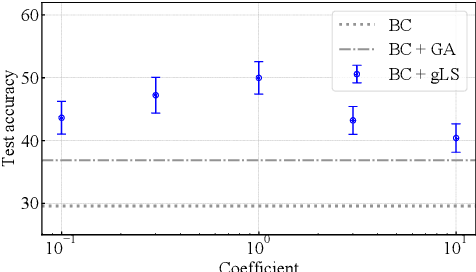
This paper discusses the problem of weakly supervised learning of classification, in which instances are given weak labels that are produced by some label-corruption process. The goal is to derive conditions under which loss functions for weak-label learning are proper and lower-bounded -- two essential requirements for the losses used in class-probability estimation. To this end, we derive a representation theorem for proper losses in supervised learning, which dualizes the Savage representation. We use this theorem to characterize proper weak-label losses and find a condition for them to be lower-bounded. Based on these theoretical findings, we derive a novel regularization scheme called generalized logit squeezing, which makes any proper weak-label loss bounded from below, without losing properness. Furthermore, we experimentally demonstrate the effectiveness of our proposed approach, as compared to improper or unbounded losses. Those results highlight the importance of properness and lower-boundedness. The code is publicly available at https://github.com/yoshum/lower-bounded-proper-losses.