 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS-DPPs: Multi-Source Determinantal Point Processes for Contextual Diversity Refinement of Composite Attributes in Text to Image Retrieval
Jul 09, 2025
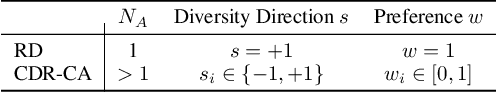
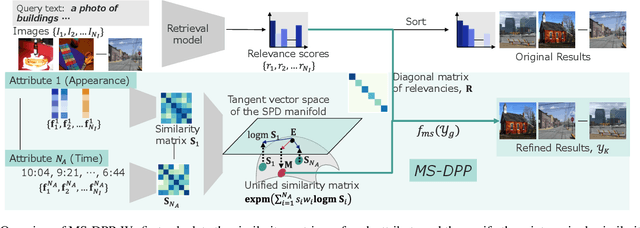
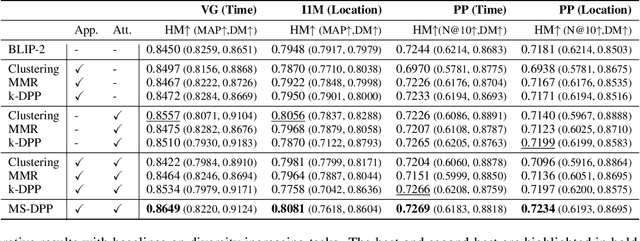
Result diversification (RD) is a crucial technique in Text-to-Image Retrieval for enhancing the efficiency of a practical application. Conventional methods focus solely on increasing the diversity metric of image appearances. However, the diversity metric and its desired value vary depending on the application, which limits the applications of RD. This paper proposes a novel task called CDR-CA (Contextual Diversity Refinement of Composite Attributes). CDR-CA aims to refine the diversities of multiple attributes, according to the application's context. To address this task, we propose Multi-Source DPPs, a simple yet strong baseline that extends the Determinantal Point Process (DPP) to multi-sources. We model MS-DPP as a single DPP model with a unified similarity matrix based on a manifold representation. We also introduce Tangent Normalization to reflect contexts. Extensive experiments demonstrate the effectiveness of the proposed method. Our code is publicly available at https://github.com/NEC-N-SOGI/msdpp.
Object-Aware Query Perturbation for Cross-Modal Image-Text Retrieval
Jul 17, 2024
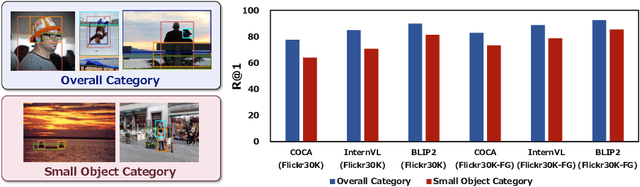
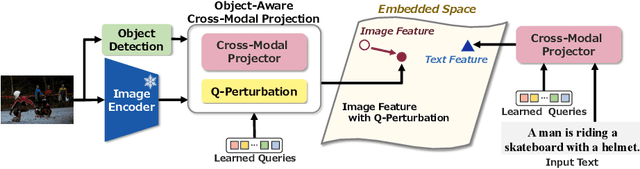
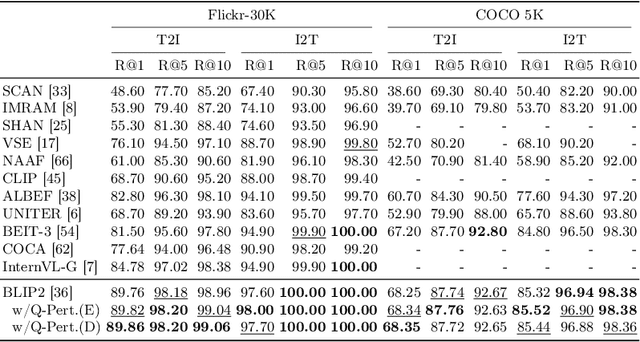
The pre-trained vision and language (V\&L) models have substantially improved the performance of cross-modal image-text retrieval. In general, however, V\&L models have limited retrieval performance for small objects because of the rough alignment between words and the small objects in the image. In contrast, it is known that human cognition is object-centric, and we pay more attention to important objects, even if they are small. To bridge this gap between the human cognition and the V\&L model's capability, we propose a cross-modal image-text retrieval framework based on ``object-aware query perturbation.'' The proposed method generates a key feature subspace of the detected objects and perturbs the corresponding queries using this subspace to improve the object awareness in the image. In our proposed method, object-aware cross-modal image-text retrieval is possible while keeping the rich expressive power and retrieval performance of existing V\&L models without additional fine-tuning. Comprehensive experiments on four public datasets show that our method outperforms conventional algorithms.
Future Predictive Success-or-Failure Classification for Long-Horizon Robotic Tasks
Apr 04, 2024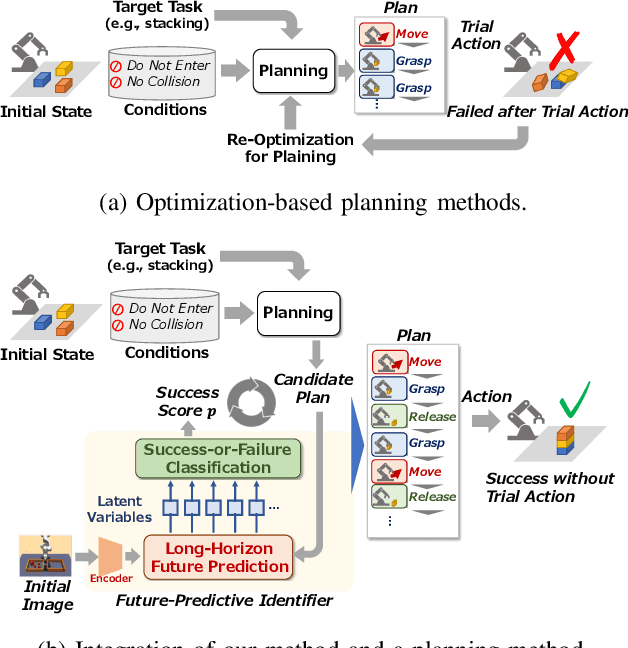
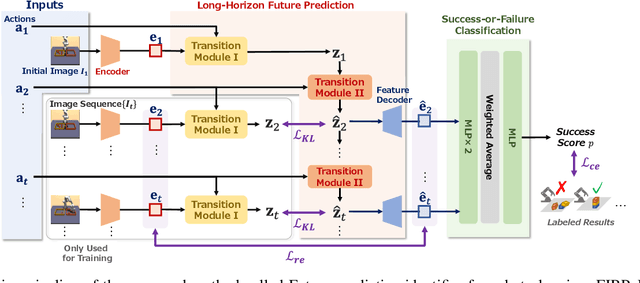
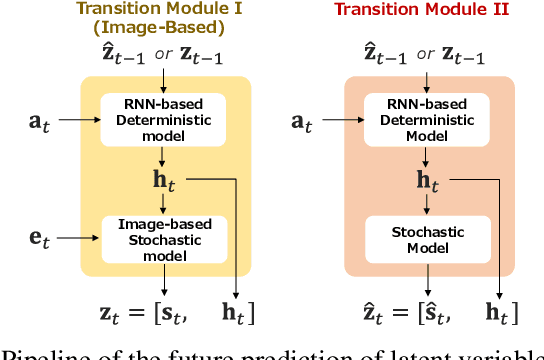
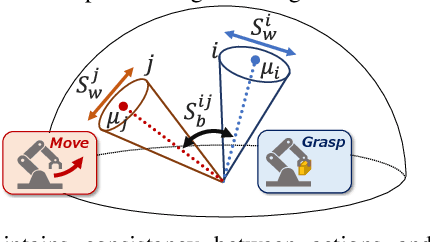
Automating long-horizon tasks with a robotic arm has been a central research topic in robotics. Optimization-based action planning is an efficient approach for creating an action plan to complete a given task. Construction of a reliable planning method requires a design process of conditions, e.g., to avoid collision between objects. The design process, however, has two critical issues: 1) iterative trials--the design process is time-consuming due to the trial-and-error process of modifying conditions, and 2) manual redesign--it is difficult to cover all the necessary conditions manually. To tackle these issues, this paper proposes a future-predictive success-or-failure-classification method to obtain conditions automatically. The key idea behind the proposed method is an end-to-end approach for determining whether the action plan can complete a given task instead of manually redesigning the conditions. The proposed method uses a long-horizon future-prediction method to enable success-or-failure classification without the execution of an action plan. This paper also proposes a regularization term called transition consistency regularization to provide easy-to-predict feature distribution. The regularization term improves future prediction and classification performance. The effectiveness of our method is demonstrated through classification and robotic-manipulation experiments.
Time-series Anomaly Detection based on Difference Subspace between Signal Subspaces
Apr 05, 2023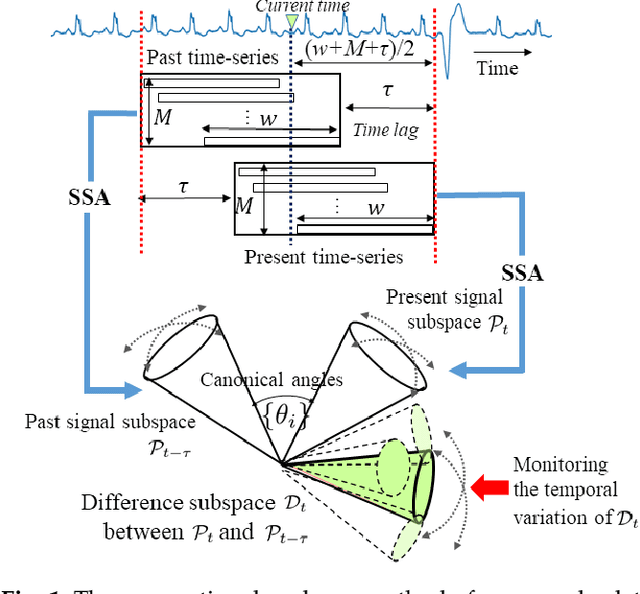
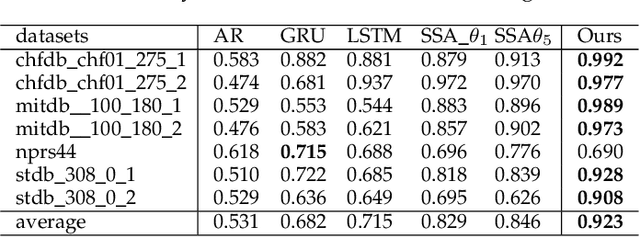
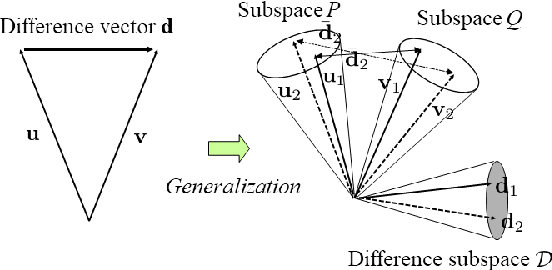
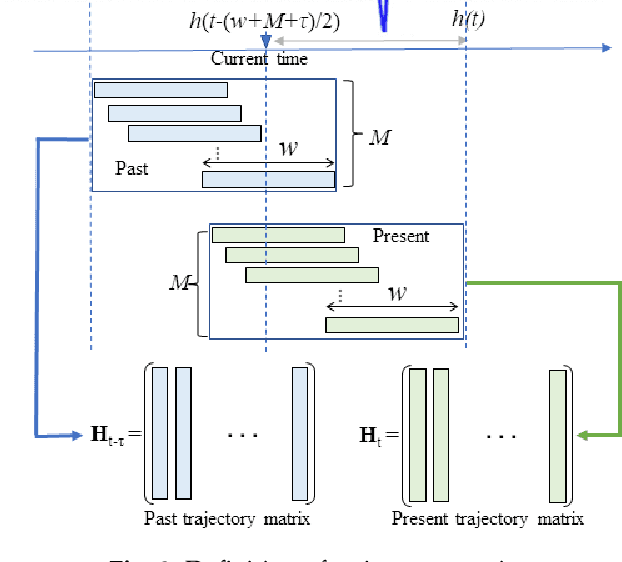
This paper proposes a new method for anomaly detection in time-series data by incorporating the concept of difference subspace into the singular spectrum analysis (SSA). The key idea is to monitor slight temporal variations of the difference subspace between two signal subspaces corresponding to the past and present time-series data, as anomaly score. It is a natural generalization of the conventional SSA-based method which measures the minimum angle between the two signal subspaces as the degree of changes. By replacing the minimum angle with the difference subspace, our method boosts the performance while using the SSA-based framework as it can capture the whole structural difference between the two subspaces in its magnitude and direction. We demonstrate our method's effectiveness through performance evaluations on public time-series datasets.
Visually explaining 3D-CNN predictions for video classification with an adaptive occlusion sensitivity analysis
Jul 26, 2022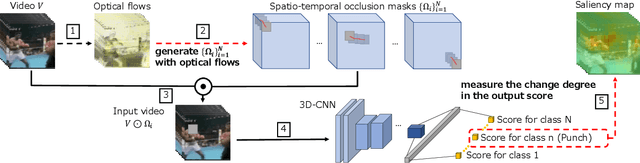
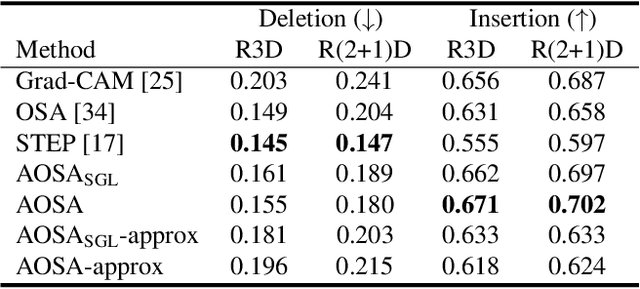
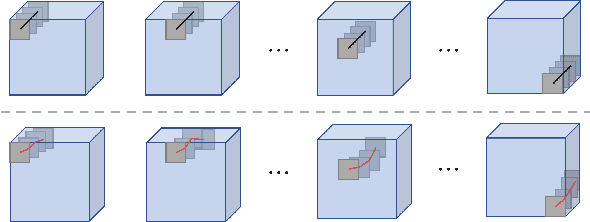
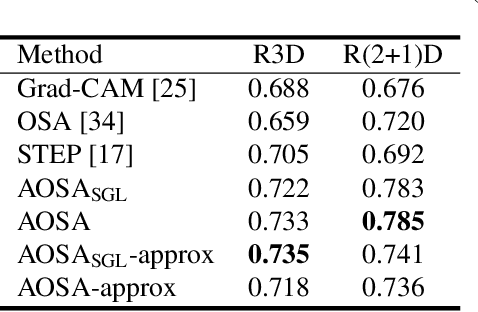
This paper proposes a method for visually explaining the decision-making process of 3D convolutional neural networks (CNN) with a temporal extension of occlusion sensitivity analysis. The key idea here is to occlude a specific volume of data by a 3D mask in an input 3D temporal-spatial data space and then measure the change degree in the output score. The occluded volume data that produces a larger change degree is regarded as a more critical element for classification. However, while the occlusion sensitivity analysis is commonly used to analyze single image classification, it is not so straightforward to apply this idea to video classification as a simple fixed cuboid cannot deal with the motions. To this end, we adapt the shape of a 3D occlusion mask to complicated motions of target objects. Our flexible mask adaptation is performed by considering the temporal continuity and spatial co-occurrence of the optical flows extracted from the input video data. We further propose to approximate our method by using the first-order partial derivative of the score with respect to an input image to reduce its computational cost. We demonstrate the effectiveness of our method through various and extensive comparisons with the conventional methods in terms of the deletion/insertion metric and the pointing metric on the UCF-101. The code is available at: https://github.com/uchiyama33/AOSA.
Grassmannian learning mutual subspace method for image set recognition
Nov 08, 2021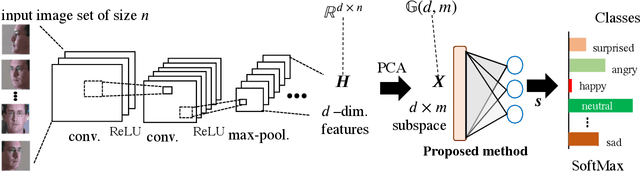
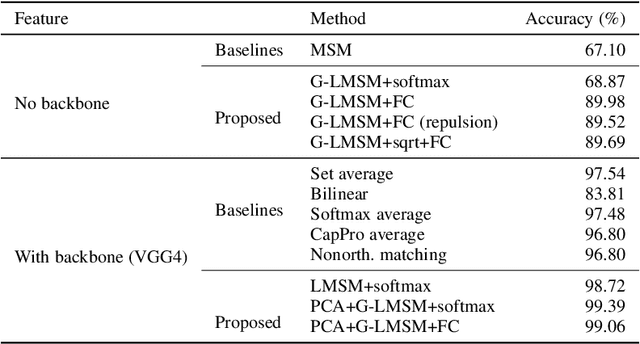
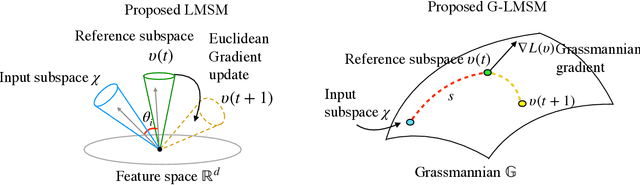
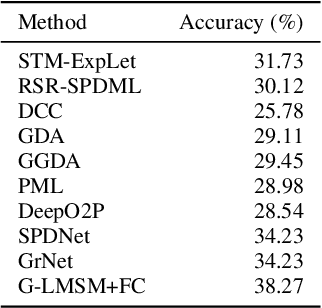
This paper addresses the problem of object recognition given a set of images as input (e.g., multiple camera sources and video frames). Convolutional neural network (CNN)-based frameworks do not exploit these sets effectively, processing a pattern as observed, not capturing the underlying feature distribution as it does not consider the variance of images in the set. To address this issue, we propose the Grassmannian learning mutual subspace method (G-LMSM), a NN layer embedded on top of CNNs as a classifier, that can process image sets more effectively and can be trained in an end-to-end manner. The image set is represented by a low-dimensional input subspace; and this input subspace is matched with reference subspaces by a similarity of their canonical angles, an interpretable and easy to compute metric. The key idea of G-LMSM is that the reference subspaces are learned as points on the Grassmann manifold, optimized with Riemannian stochastic gradient descent. This learning is stable, efficient and theoretically well-grounded. We demonstrate the effectiveness of our proposed method on hand shape recognition, face identification, and facial emotion recognition.
Discriminant analysis based on projection onto generalized difference subspace
Oct 30, 2019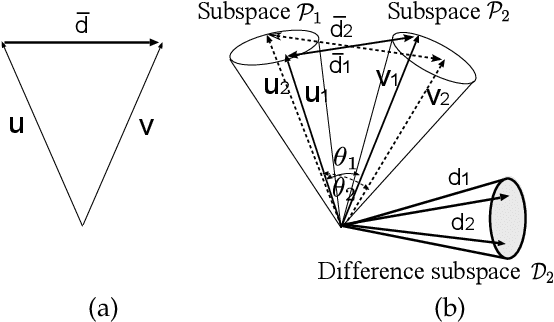

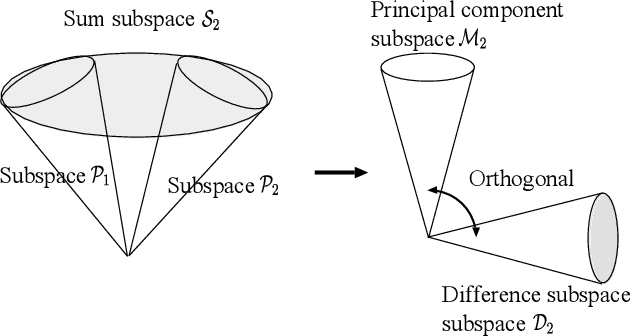
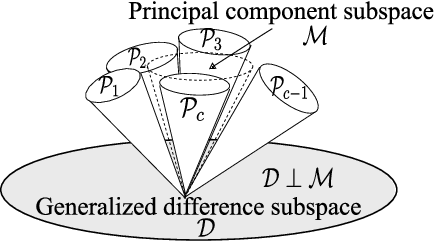
This paper discusses a new type of discriminant analysis based on the orthogonal projection of data onto a generalized difference subspace (GDS). In our previous work, we have demonstrated that GDS projection works as the quasi-orthogonalization of class subspaces, which is an effective feature extraction for subspace based classifiers. Interestingly, GDS projection also works as a discriminant feature extraction through a similar mechanism to the Fisher discriminant analysis (FDA). A direct proof of the connection between GDS projection and FDA is difficult due to the significant difference in their formulations. To avoid the difficulty, we first introduce geometrical Fisher discriminant analysis (gFDA) based on a simplified Fisher criterion. Our simplified Fisher criterion is derived from a heuristic yet practically plausible principle: the direction of the sample mean vector of a class is in most cases almost equal to that of the first principal component vector of the class, under the condition that the principal component vectors are calculated by applying the principal component analysis (PCA) without data centering. gFDA can work stably even under few samples, bypassing the small sample size (SSS) problem of FDA. Next, we prove that gFDA is equivalent to GDS projection with a small correction term. This equivalence ensures GDS projection to inherit the discriminant ability from FDA via gFDA. Furthermore, to enhance the performances of gFDA and GDS projection, we normalize the projected vectors on the discriminant spaces. Extensive experiments using the extended Yale B+ database and the CMU face database show that gFDA and GDS projection have equivalent or better performance than the original FDA and its extensions.
Resolving Marker Pose Ambiguity by Robust Rotation Averaging with Clique Constraints
Sep 26, 2019
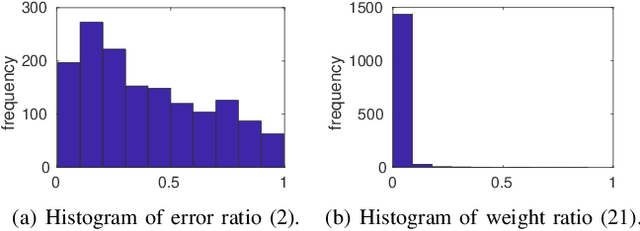

Planar markers are useful in robotics and computer vision for mapping and localisation. Given a detected marker in an image, a frequent task is to estimate the 6DOF pose of the marker relative to the camera, which is an instance of planar pose estimation (PPE). Although there are mature techniques, PPE suffers from a fundamental ambiguity problem, in that there can be more than one plausible pose solutions for a PPE instance. Especially when localisation of the marker corners is noisy, it is often difficult to disambiguate the pose solutions based on reprojection error alone. Previous methods choose between the possible solutions using a heuristic criteria, or simply ignore ambiguous markers. We propose to resolve the ambiguities by examining the consistencies of a set of markers across multiple views. Our specific contributions include a novel rotation averaging formulation that incorporates long-range dependencies between possible marker orientation solutions that arise from PPE ambiguities. We analyse the combinatorial complexity of the problem, and develop a novel lifted algorithm to effectively resolve marker pose ambiguities, without discarding any marker observations. Results on real and synthetic data show that our method is able to handle highly ambiguous inputs, and provides more accurate and/or complete marker-based mapping and localisation.
Constrained Mutual Convex Cone Method for Image Set Based Recognition
Mar 14, 2019

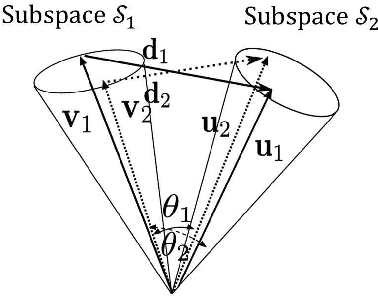

In this paper, we propose a method for image-set classification based on convex cone models. Image set classification aims to classify a set of images, which were usually obtained from video frames or multi-view cameras, into a target object. To accurately and stably classify a set, it is essential to represent structural information of the set accurately. There are various representative image features, such as histogram based features, HLAC, and Convolutional Neural Network (CNN) features. We should note that most of them have non-negativity and thus can be effectively represented by a convex cone. This leads us to introduce the convex cone representation to image-set classification. To establish a convex cone based framework, we mathematically define multiple angles between two convex cones, and then define the geometric similarity between the cones using the angles. Moreover, to enhance the framework, we introduce a discriminant space that maximizes the between-class variance (gaps) and minimizes the within-class variance of the projected convex cones onto the discriminant space, similar to the Fisher discriminant analysis. Finally, the classification is performed based on the similarity between projected convex cones. The effectiveness of the proposed method is demonstrated experimentally by using five databases: CMU PIE dataset, ETH-80, CMU Motion of Body dataset, Youtube Celebrity dataset, and a private database of multi-view hand shapes.
A Method Based on Convex Cone Model for Image-Set Classification with CNN Features
May 31, 2018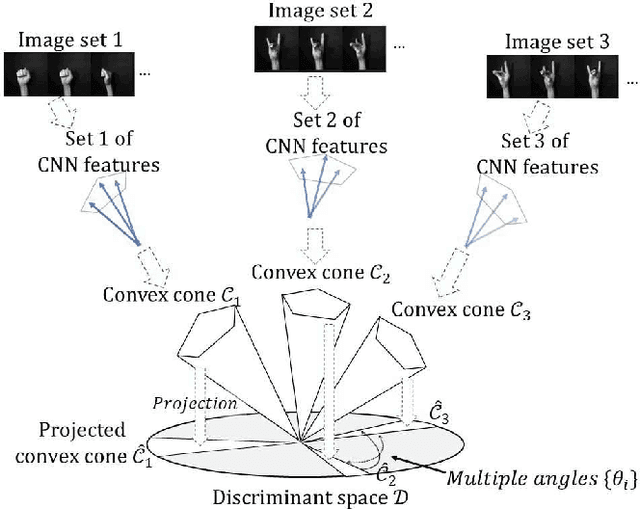

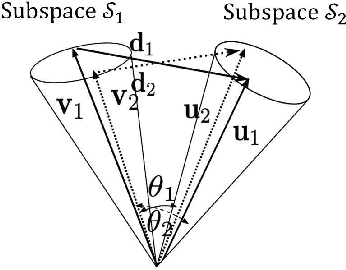

In this paper, we propose a method for image-set classification based on convex cone models, focusing on the effectiveness of convolutional neural network (CNN) features as inputs. CNN features have non-negative values when using the rectified linear unit as an activation function. This naturally leads us to model a set of CNN features by a convex cone and measure the geometric similarity of convex cones for classification. To establish this framework, we sequentially define multiple angles between two convex cones by repeating the alternating least squares method and then define the geometric similarity between the cones using the obtained angles. Moreover, to enhance our method, we introduce a discriminant space, maximizing the between-class variance (gaps) and minimizes the within-class variance of the projected convex cones onto the discriminant space, similar to a Fisher discriminant analysis. Finally, classification is based on the similarity between projected convex cones. The effectiveness of the proposed method was demonstrated experimentally using a private, multi-view hand shape dataset and two public databases.