 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Self-Distillation for Image Classification
Dec 30, 2025Supervised training of deep neural networks for classification typically relies on hard targets, which promote overconfidence and can limit calibration, generalization, and robustness. Self-distillation methods aim to mitigate this by leveraging inter-class and sample-specific information present in the model's own predictions, but often remain dependent on hard targets, reducing their effectiveness. With this in mind, we propose Bayesian Self-Distillation (BSD), a principled method for constructing sample-specific target distributions via Bayesian inference using the model's own predictions. Unlike existing approaches, BSD does not rely on hard targets after initialization. BSD consistently yields higher test accuracy (e.g. +1.4% for ResNet-50 on CIFAR-100) and significantly lower Expected Calibration Error (ECE) (-40% ResNet-50, CIFAR-100) than existing architecture-preserving self-distillation methods for a range of deep architectures and datasets. Additional benefits include improved robustness against data corruptions, perturbations, and label noise. When combined with a contrastive loss, BSD achieves state-of-the-art robustness under label noise for single-stage, single-network methods.
Domain Randomization for Object Detection in Manufacturing Applications using Synthetic Data: A Comprehensive Study
Jun 09, 2025This paper addresses key aspects of domain randomization in generating synthetic data for manufacturing object detection applications. To this end, we present a comprehensive data generation pipeline that reflects different factors: object characteristics, background, illumination, camera settings, and post-processing. We also introduce the Synthetic Industrial Parts Object Detection dataset (SIP15-OD) consisting of 15 objects from three industrial use cases under varying environments as a test bed for the study, while also employing an industrial dataset publicly available for robotic applications. In our experiments, we present more abundant results and insights into the feasibility as well as challenges of sim-to-real object detection. In particular, we identified material properties, rendering methods, post-processing, and distractors as important factors. Our method, leveraging these, achieves top performance on the public dataset with Yolov8 models trained exclusively on synthetic data; mAP@50 scores of 96.4% for the robotics dataset, and 94.1%, 99.5%, and 95.3% across three of the SIP15-OD use cases, respectively. The results showcase the effectiveness of the proposed domain randomization, potentially covering the distribution close to real data for the applications.
NT-ViT: Neural Transcoding Vision Transformers for EEG-to-fMRI Synthesis
Sep 18, 2024This paper introduces the Neural Transcoding Vision Transformer (\modelname), a generative model designed to estimate high-resolution functional Magnetic Resonance Imaging (fMRI) samples from simultaneous Electroencephalography (EEG) data. A key feature of \modelname is its Domain Matching (DM) sub-module which effectively aligns the latent EEG representations with those of fMRI volumes, enhancing the model's accuracy and reliability. Unlike previous methods that tend to struggle with fidelity and reproducibility of images, \modelname addresses these challenges by ensuring methodological integrity and higher-quality reconstructions which we showcase through extensive evaluation on two benchmark datasets; \modelname outperforms the current state-of-the-art by a significant margin in both cases, e.g. achieving a $10\times$ reduction in RMSE and a $3.14\times$ increase in SSIM on the Oddball dataset. An ablation study also provides insights into the contribution of each component to the model's overall effectiveness. This development is critical in offering a new approach to lessen the time and financial constraints typically linked with high-resolution brain imaging, thereby aiding in the swift and precise diagnosis of neurological disorders. Although it is not a replacement for actual fMRI but rather a step towards making such imaging more accessible, we believe that it represents a pivotal advancement in clinical practice and neuroscience research. Code is available at \url{https://github.com/rom42pla/ntvit}.
Towards Sim-to-Real Industrial Parts Classification with Synthetic Dataset
Apr 12, 2024



This paper is about effectively utilizing synthetic data for training deep neural networks for industrial parts classification, in particular, by taking into account the domain gap against real-world images. To this end, we introduce a synthetic dataset that may serve as a preliminary testbed for the Sim-to-Real challenge; it contains 17 objects of six industrial use cases, including isolated and assembled parts. A few subsets of objects exhibit large similarities in shape and albedo for reflecting challenging cases of industrial parts. All the sample images come with and without random backgrounds and post-processing for evaluating the importance of domain randomization. We call it Synthetic Industrial Parts dataset (SIP-17). We study the usefulness of SIP-17 through benchmarking the performance of five state-of-the-art deep network models, supervised and self-supervised, trained only on the synthetic data while testing them on real data. By analyzing the results, we deduce some insights on the feasibility and challenges of using synthetic data for industrial parts classification and for further developing larger-scale synthetic datasets. Our dataset and code are publicly available.
* Published in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
ZoDi: Zero-Shot Domain Adaptation with Diffusion-Based Image Transfer
Mar 20, 2024
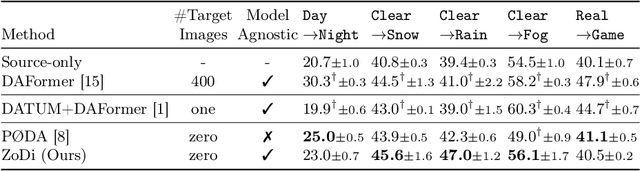
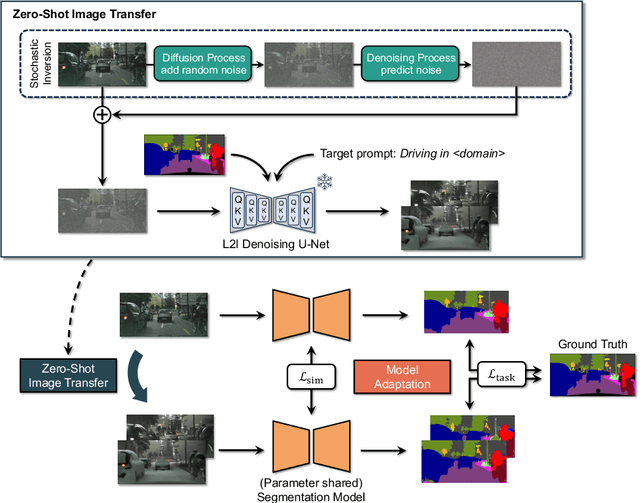
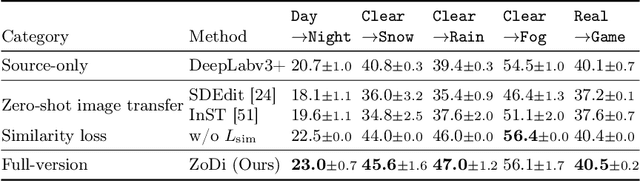
Deep learning models achieve high accuracy in segmentation tasks among others, yet domain shift often degrades the models' performance, which can be critical in real-world scenarios where no target images are available. This paper proposes a zero-shot domain adaptation method based on diffusion models, called ZoDi, which is two-fold by the design: zero-shot image transfer and model adaptation. First, we utilize an off-the-shelf diffusion model to synthesize target-like images by transferring the domain of source images to the target domain. In this we specifically try to maintain the layout and content by utilising layout-to-image diffusion models with stochastic inversion. Secondly, we train the model using both source images and synthesized images with the original segmentation maps while maximizing the feature similarity of images from the two domains to learn domain-robust representations. Through experiments we show benefits of ZoDi in the task of image segmentation over state-of-the-art methods. It is also more applicable than existing CLIP-based methods because it assumes no specific backbone or models, and it enables to estimate the model's performance without target images by inspecting generated images. Our implementation will be publicly available.
Marginal Thresholding in Noisy Image Segmentation
May 04, 2023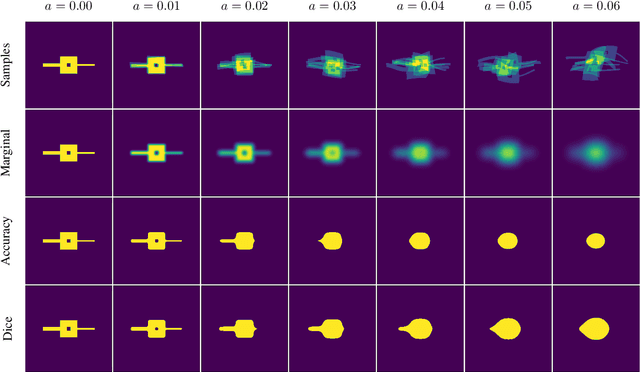

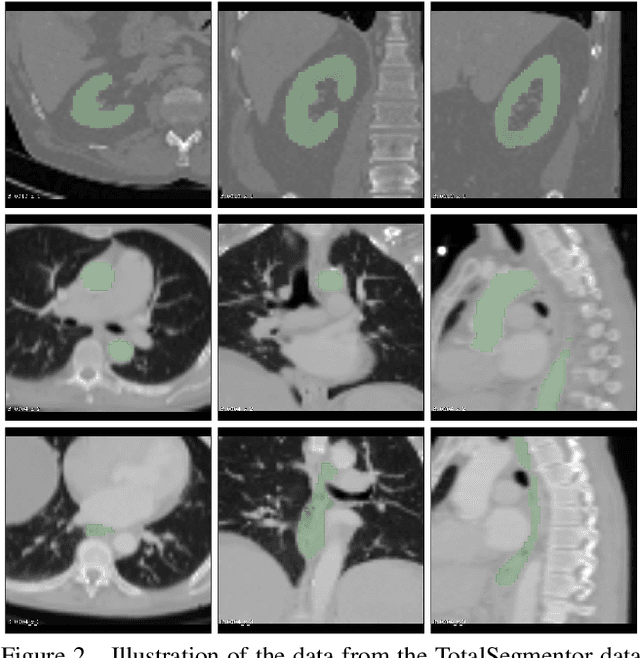
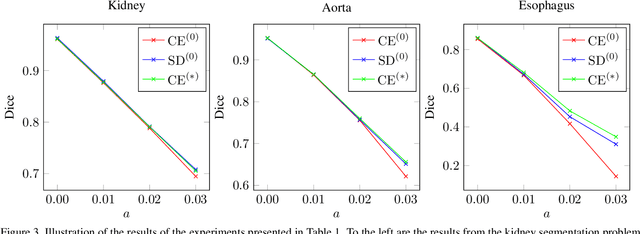
This work presents a study on label noise in medical image segmentation by considering a noise model based on Gaussian field deformations. Such noise is of interest because it yields realistic looking segmentations and because it is unbiased in the sense that the expected deformation is the identity mapping. Efficient methods for sampling and closed form solutions for the marginal probabilities are provided. Moreover, theoretically optimal solutions to the loss functions cross-entropy and soft-Dice are studied and it is shown how they diverge as the level of noise increases. Based on recent work on loss function characterization, it is shown that optimal solutions to soft-Dice can be recovered by thresholding solutions to cross-entropy with a particular a priori unknown threshold that efficiently can be computed. This raises the question whether the decrease in performance seen when using cross-entropy as compared to soft-Dice is caused by using the wrong threshold. The hypothesis is validated in 5-fold studies on three organ segmentation problems from the TotalSegmentor data set, using 4 different strengths of noise. The results show that changing the threshold leads the performance of cross-entropy to go from systematically worse than soft-Dice to similar or better results than soft-Dice.
Time-series Anomaly Detection based on Difference Subspace between Signal Subspaces
Apr 05, 2023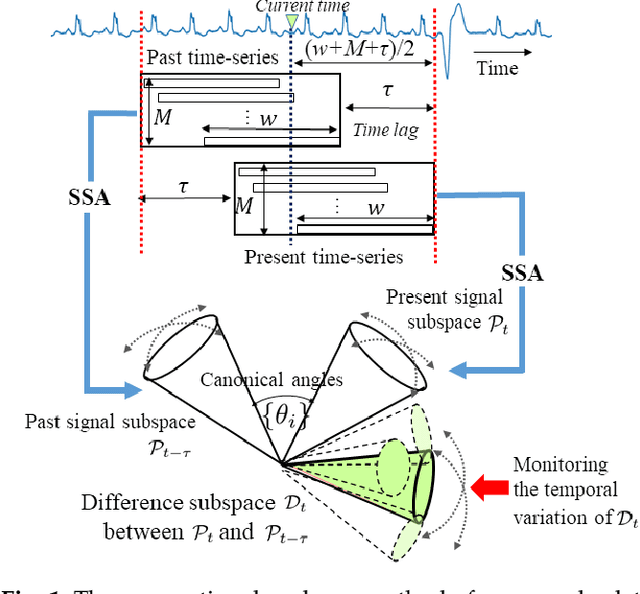
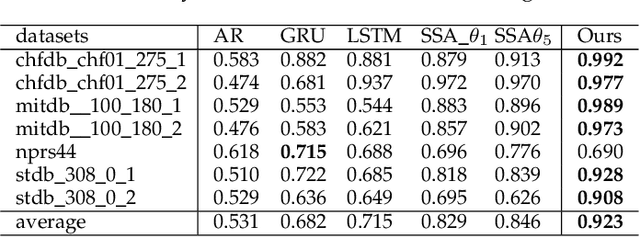
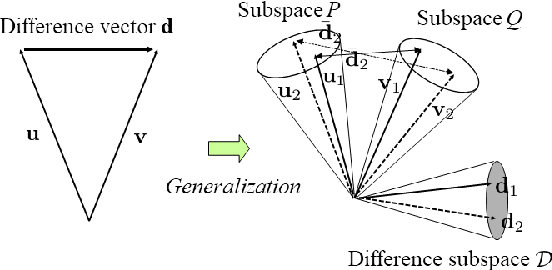
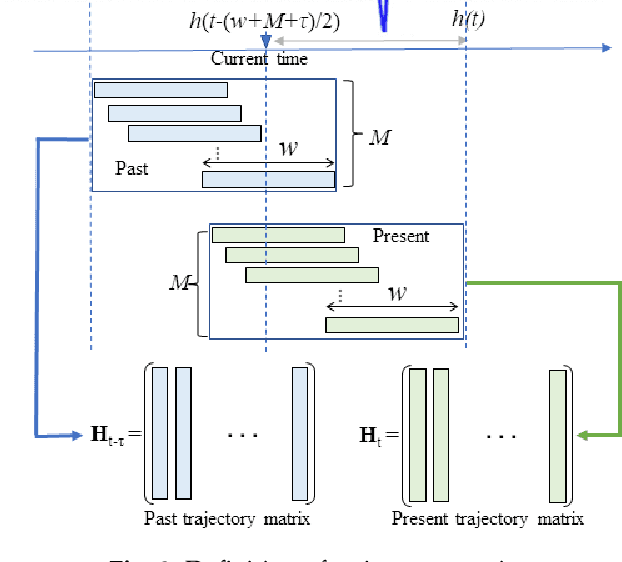
This paper proposes a new method for anomaly detection in time-series data by incorporating the concept of difference subspace into the singular spectrum analysis (SSA). The key idea is to monitor slight temporal variations of the difference subspace between two signal subspaces corresponding to the past and present time-series data, as anomaly score. It is a natural generalization of the conventional SSA-based method which measures the minimum angle between the two signal subspaces as the degree of changes. By replacing the minimum angle with the difference subspace, our method boosts the performance while using the SSA-based framework as it can capture the whole structural difference between the two subspaces in its magnitude and direction. We demonstrate our method's effectiveness through performance evaluations on public time-series datasets.
Noisy Image Segmentation With Soft-Dice
Apr 04, 2023

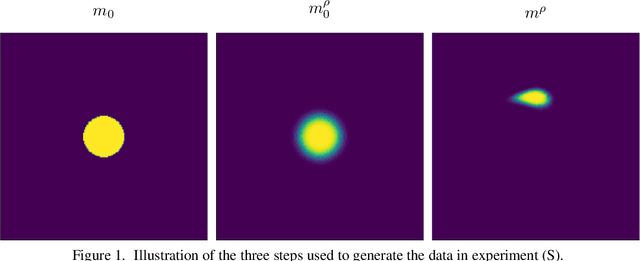

This paper presents a study on the soft-Dice loss, one of the most popular loss functions in medical image segmentation, for situations where noise is present in target labels. In particular, the set of optimal solutions are characterized and sharp bounds on the volume bias of these solutions are provided. It is further shown that a sequence of soft segmentations converging to optimal soft-Dice also converges to optimal Dice when converted to hard segmentations using thresholding. This is an important result because soft-Dice is often used as a proxy for maximizing the Dice metric. Finally, experiments confirming the theoretical results are provided.
Dense FixMatch: a simple semi-supervised learning method for pixel-wise prediction tasks
Oct 18, 2022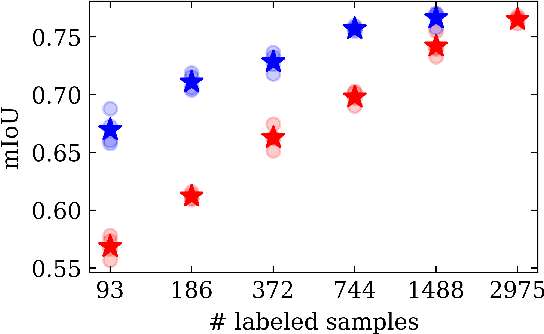

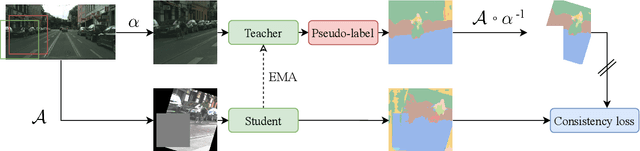

We propose Dense FixMatch, a simple method for online semi-supervised learning of dense and structured prediction tasks combining pseudo-labeling and consistency regularization via strong data augmentation. We enable the application of FixMatch in semi-supervised learning problems beyond image classification by adding a matching operation on the pseudo-labels. This allows us to still use the full strength of data augmentation pipelines, including geometric transformations. We evaluate it on semi-supervised semantic segmentation on Cityscapes and Pascal VOC with different percentages of labeled data and ablate design choices and hyper-parameters. Dense FixMatch significantly improves results compared to supervised learning using only labeled data, approaching its performance with 1/4 of the labeled samples.
Towards a Unified View of Affinity-Based Knowledge Distillation
Sep 30, 2022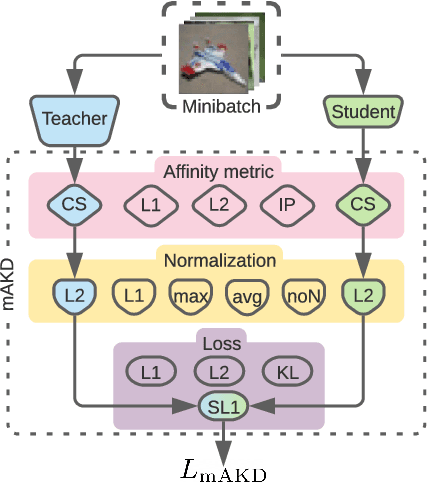
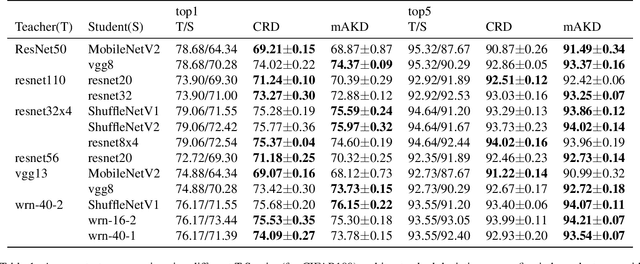
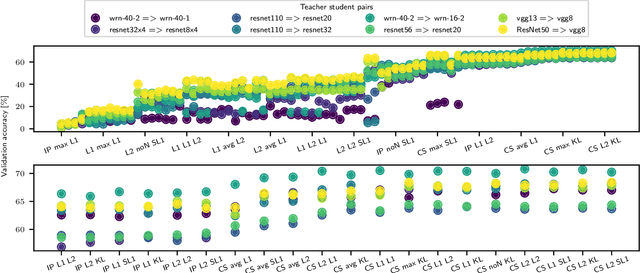

Knowledge transfer between artificial neural networks has become an important topic in deep learning. Among the open questions are what kind of knowledge needs to be preserved for the transfer, and how it can be effectively achieved. Several recent work have shown good performance of distillation methods using relation-based knowledge. These algorithms are extremely attractive in that they are based on simple inter-sample similarities. Nevertheless, a proper metric of affinity and use of it in this context is far from well understood. In this paper, by explicitly modularising knowledge distillation into a framework of three components, i.e. affinity, normalisation, and loss, we give a unified treatment of these algorithms as well as study a number of unexplored combinations of the modules. With this framework we perform extensive evaluations of numerous distillation objectives for image classification, and obtain a few useful insights for effective design choices while demonstrating how relation-based knowledge distillation could achieve comparable performance to the state of the art in spite of the simplicity.