 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Unified View of Affinity-Based Knowledge Distillation
Paper and Code
Sep 30, 2022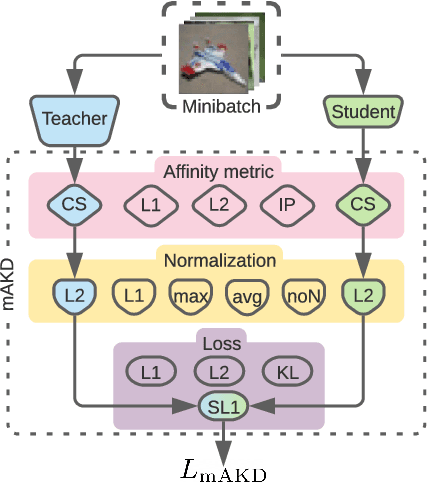
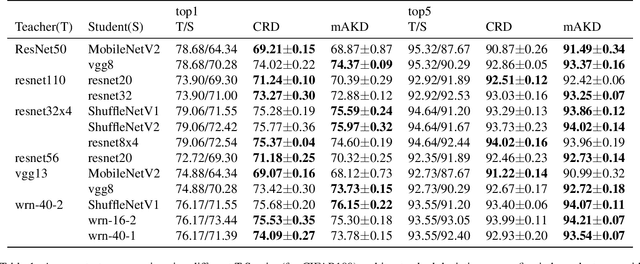
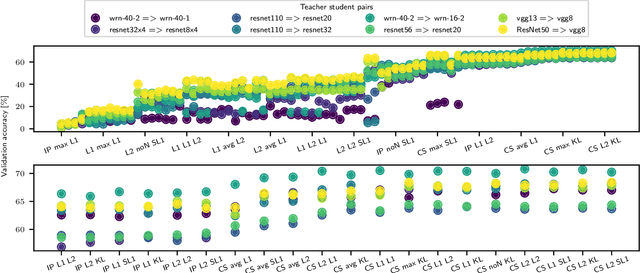

Knowledge transfer between artificial neural networks has become an important topic in deep learning. Among the open questions are what kind of knowledge needs to be preserved for the transfer, and how it can be effectively achieved. Several recent work have shown good performance of distillation methods using relation-based knowledge. These algorithms are extremely attractive in that they are based on simple inter-sample similarities. Nevertheless, a proper metric of affinity and use of it in this context is far from well understood. In this paper, by explicitly modularising knowledge distillation into a framework of three components, i.e. affinity, normalisation, and loss, we give a unified treatment of these algorithms as well as study a number of unexplored combinations of the modules. With this framework we perform extensive evaluations of numerous distillation objectives for image classification, and obtain a few useful insights for effective design choices while demonstrating how relation-based knowledge distillation could achieve comparable performance to the state of the art in spite of the simplicity.