 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Unified View of Affinity-Based Knowledge Distillation
Sep 30, 2022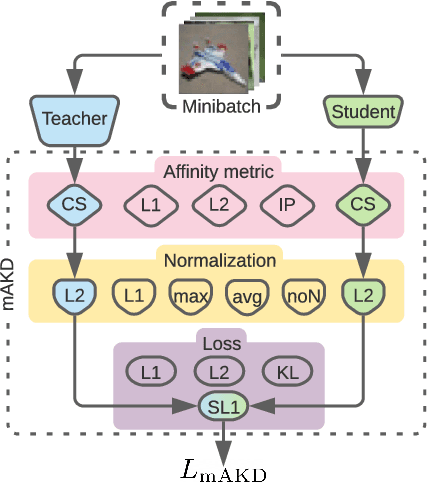
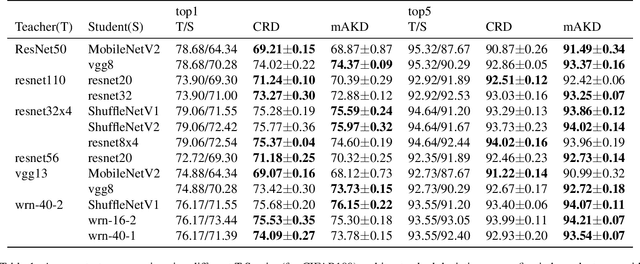
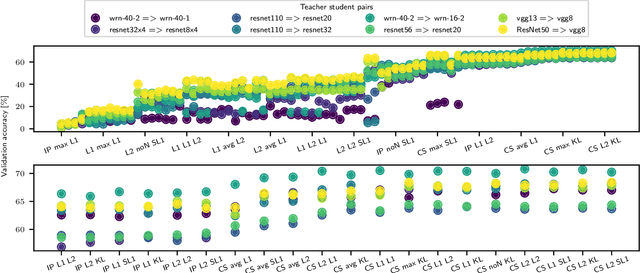

Knowledge transfer between artificial neural networks has become an important topic in deep learning. Among the open questions are what kind of knowledge needs to be preserved for the transfer, and how it can be effectively achieved. Several recent work have shown good performance of distillation methods using relation-based knowledge. These algorithms are extremely attractive in that they are based on simple inter-sample similarities. Nevertheless, a proper metric of affinity and use of it in this context is far from well understood. In this paper, by explicitly modularising knowledge distillation into a framework of three components, i.e. affinity, normalisation, and loss, we give a unified treatment of these algorithms as well as study a number of unexplored combinations of the modules. With this framework we perform extensive evaluations of numerous distillation objectives for image classification, and obtain a few useful insights for effective design choices while demonstrating how relation-based knowledge distillation could achieve comparable performance to the state of the art in spite of the simplicity.
Target Aware Network Adaptation for Efficient Representation Learning
Oct 02, 2018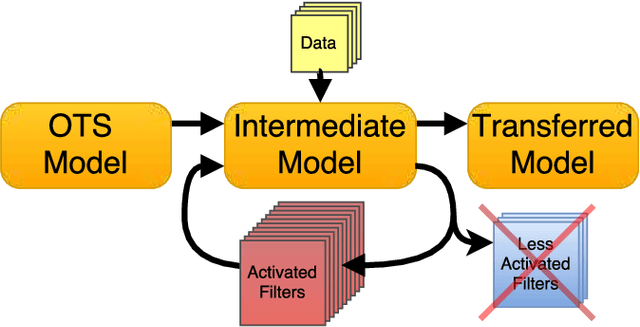

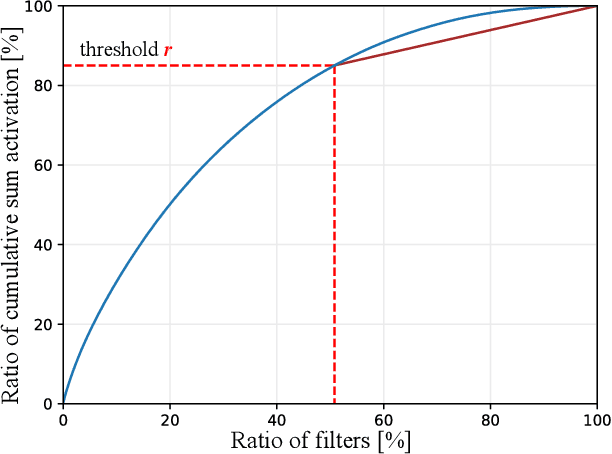
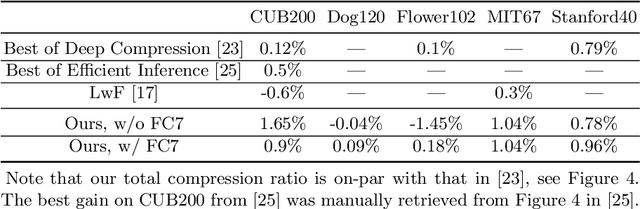
This paper presents an automatic network adaptation method that finds a ConvNet structure well-suited to a given target task, e.g., image classification, for efficiency as well as accuracy in transfer learning. We call the concept target-aware transfer learning. Given only small-scale labeled data, and starting from an ImageNet pre-trained network, we exploit a scheme of removing its potential redundancy for the target task through iterative operations of filter-wise pruning and network optimization. The basic motivation is that compact networks are on one hand more efficient and should also be more tolerant, being less complex, against the risk of overfitting which would hinder the generalization of learned representations in the context of transfer learning. Further, unlike existing methods involving network simplification, we also let the scheme identify redundant portions across the entire network, which automatically results in a network structure adapted to the task at hand. We achieve this with a few novel ideas: (i) cumulative sum of activation statistics for each layer, and (ii) a priority evaluation of pruning across multiple layers. Experimental results by the method on five datasets (Flower102, CUB200-2011, Dog120, MIT67, and Stanford40) show favorable accuracies over the related state-of-the-art techniques while enhancing the computational and storage efficiency of the transferred model.