 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentThink: A Unified Framework for Tool-Augmented Chain-of-Thought Reasoning in Vision-Language Models for Autonomous Driving
May 21, 2025



Vision-Language Models (VLMs) show promise for autonomous driving, yet their struggle with hallucinations, inefficient reasoning, and limited real-world validation hinders accurate perception and robust step-by-step reasoning. To overcome this, we introduce \textbf{AgentThink}, a pioneering unified framework that, for the first time, integrates Chain-of-Thought (CoT) reasoning with dynamic, agent-style tool invocation for autonomous driving tasks. AgentThink's core innovations include: \textbf{(i) Structured Data Generation}, by establishing an autonomous driving tool library to automatically construct structured, self-verified reasoning data explicitly incorporating tool usage for diverse driving scenarios; \textbf{(ii) A Two-stage Training Pipeline}, employing Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO) to equip VLMs with the capability for autonomous tool invocation; and \textbf{(iii) Agent-style Tool-Usage Evaluation}, introducing a novel multi-tool assessment protocol to rigorously evaluate the model's tool invocation and utilization. Experiments on the DriveLMM-o1 benchmark demonstrate AgentThink significantly boosts overall reasoning scores by \textbf{53.91\%} and enhances answer accuracy by \textbf{33.54\%}, while markedly improving reasoning quality and consistency. Furthermore, ablation studies and robust zero-shot/few-shot generalization experiments across various benchmarks underscore its powerful capabilities. These findings highlight a promising trajectory for developing trustworthy and tool-aware autonomous driving models.
ODVerse33: Is the New YOLO Version Always Better? A Multi Domain benchmark from YOLO v5 to v11
Feb 20, 2025You Look Only Once (YOLO) models have been widely used for building real-time object detectors across various domains. With the increasing frequency of new YOLO versions being released, key questions arise. Are the newer versions always better than their previous versions? What are the core innovations in each YOLO version and how do these changes translate into real-world performance gains? In this paper, we summarize the key innovations from YOLOv1 to YOLOv11, introduce a comprehensive benchmark called ODverse33, which includes 33 datasets spanning 11 diverse domains (Autonomous driving, Agricultural, Underwater, Medical, Videogame, Industrial, Aerial, Wildlife, Retail, Microscopic, and Security), and explore the practical impact of model improvements in real-world, multi-domain applications through extensive experimental results. We hope this study can provide some guidance to the extensive users of object detection models and give some references for future real-time object detector development.
Discourse-Driven Evaluation: Unveiling Factual Inconsistency in Long Document Summarization
Feb 10, 2025Detecting factual inconsistency for long document summarization remains challenging, given the complex structure of the source article and long summary length. In this work, we study factual inconsistency errors and connect them with a line of discourse analysis. We find that errors are more common in complex sentences and are associated with several discourse features. We propose a framework that decomposes long texts into discourse-inspired chunks and utilizes discourse information to better aggregate sentence-level scores predicted by natural language inference models. Our approach shows improved performance on top of different model baselines over several evaluation benchmarks, covering rich domains of texts, focusing on long document summarization. This underscores the significance of incorporating discourse features in developing models for scoring summaries for long document factual inconsistency.
Evaluating AI-Generated Essays with GRE Analytical Writing Assessment
Oct 24, 2024
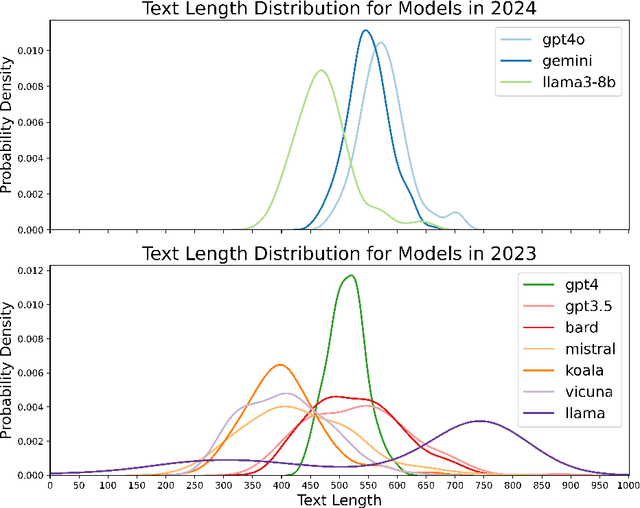

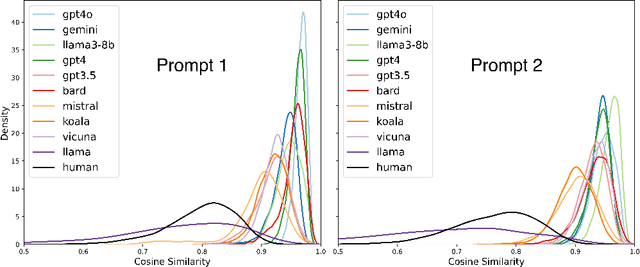
The recent revolutionary advance in generative AI enables the generation of realistic and coherent texts by large language models (LLMs). Despite many existing evaluation metrics on the quality of the generated texts, there is still a lack of rigorous assessment of how well LLMs perform in complex and demanding writing assessments. This study examines essays generated by ten leading LLMs for the analytical writing assessment of the Graduate Record Exam (GRE). We assessed these essays using both human raters and the e-rater automated scoring engine as used in the GRE scoring pipeline. Notably, the top-performing Gemini and GPT-4o received an average score of 4.78 and 4.67, respectively, falling between "generally thoughtful, well-developed analysis of the issue and conveys meaning clearly" and "presents a competent analysis of the issue and conveys meaning with acceptable clarity" according to the GRE scoring guideline. We also evaluated the detection accuracy of these essays, with detectors trained on essays generated by the same and different LLMs.
ReflectSumm: A Benchmark for Course Reflection Summarization
Mar 27, 2024



This paper introduces ReflectSumm, a novel summarization dataset specifically designed for summarizing students' reflective writing. The goal of ReflectSumm is to facilitate developing and evaluating novel summarization techniques tailored to real-world scenarios with little training data, %practical tasks with potential implications in the opinion summarization domain in general and the educational domain in particular. The dataset encompasses a diverse range of summarization tasks and includes comprehensive metadata, enabling the exploration of various research questions and supporting different applications. To showcase its utility, we conducted extensive evaluations using multiple state-of-the-art baselines. The results provide benchmarks for facilitating further research in this area.
Universal Machine Learning Kohn-Sham Hamiltonian for Materials
Feb 14, 2024While density functional theory (DFT) serves as a prevalent computational approach in electronic structure calculations, its computational demands and scalability limitations persist. Recently, leveraging neural networks to parameterize the Kohn-Sham DFT Hamiltonian has emerged as a promising avenue for accelerating electronic structure computations. Despite advancements, challenges such as the necessity for computing extensive DFT training data to explore new systems and the complexity of establishing accurate ML models for multi-elemental materials still exist. Addressing these hurdles, this study introduces a universal electronic Hamiltonian model trained on Hamiltonian matrices obtained from first-principles DFT calculations of nearly all crystal structures on the Materials Project. We demonstrate its generality in predicting electronic structures across the whole periodic table, including complex multi-elemental systems. By offering a reliable efficient framework for computing electronic properties, this universal Hamiltonian model lays the groundwork for advancements in diverse fields related to electronic structures.
Overview of ImageArg-2023: The First Shared Task in Multimodal Argument Mining
Oct 24, 2023This paper presents an overview of the ImageArg shared task, the first multimodal Argument Mining shared task co-located with the 10th Workshop on Argument Mining at EMNLP 2023. The shared task comprises two classification subtasks - (1) Subtask-A: Argument Stance Classification; (2) Subtask-B: Image Persuasiveness Classification. The former determines the stance of a tweet containing an image and a piece of text toward a controversial topic (e.g., gun control and abortion). The latter determines whether the image makes the tweet text more persuasive. The shared task received 31 submissions for Subtask-A and 21 submissions for Subtask-B from 9 different teams across 6 countries. The top submission in Subtask-A achieved an F1-score of 0.8647 while the best submission in Subtask-B achieved an F1-score of 0.5561.
STRONG -- Structure Controllable Legal Opinion Summary Generation
Sep 29, 2023
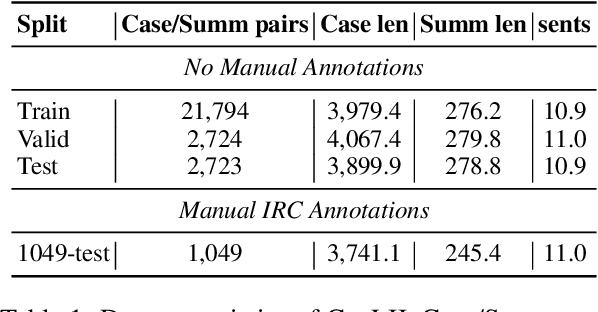


We propose an approach for the structure controllable summarization of long legal opinions that considers the argument structure of the document. Our approach involves using predicted argument role information to guide the model in generating coherent summaries that follow a provided structure pattern. We demonstrate the effectiveness of our approach on a dataset of legal opinions and show that it outperforms several strong baselines with respect to ROUGE, BERTScore, and structure similarity.
Towards Argument-Aware Abstractive Summarization of Long Legal Opinions with Summary Reranking
Jun 01, 2023We propose a simple approach for the abstractive summarization of long legal opinions that considers the argument structure of the document. Legal opinions often contain complex and nuanced argumentation, making it challenging to generate a concise summary that accurately captures the main points of the legal opinion. Our approach involves using argument role information to generate multiple candidate summaries, then reranking these candidates based on alignment with the document's argument structure. We demonstrate the effectiveness of our approach on a dataset of long legal opinions and show that it outperforms several strong baselines.
Time-reversal equivariant neural network potential and Hamiltonian for magnetic materials
Nov 21, 2022This work presents Time-reversal Equivariant Neural Network (TENN) framework. With TENN, the time-reversal symmetry is considered in the equivariant neural network (ENN), which generalizes the ENN to consider physical quantities related to time-reversal symmetry such as spin and velocity of atoms. TENN-e3, as the time-reversal-extension of E(3) equivariant neural network, is developed to keep the Time-reversal E(3) equivariant with consideration of whether to include the spin-orbit effect for both collinear and non-collinear magnetic moments situations for magnetic material. TENN-e3 can construct spin neural network potential and the Hamiltonian of magnetic material from ab-initio calculations. Time-reversal-E(3)-equivariant convolutions for interactions of spinor and geometric tensors are employed in TENN-e3. Compared to the popular ENN, TENN-e3 can describe the complex spin-lattice coupling with high accuracy and keep time-reversal symmetry which is not preserved in the existing E(3)-equivariant model. Also, the Hamiltonian of magnetic material with time-reversal symmetry can be built with TENN-e3. TENN paves a new way to spin-lattice dynamics simulations over long-time scales and electronic structure calculations of large-scale magnetic materials.