 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan ChatGPT Code Communication Data Fairly?: Empirical Evidence from Multiple Collaborative Tasks
Oct 23, 2025Assessing communication and collaboration at scale depends on a labor intensive task of coding communication data into categories according to different frameworks. Prior research has established that ChatGPT can be directly instructed with coding rubrics to code the communication data and achieves accuracy comparable to human raters. However, whether the coding from ChatGPT or similar AI technology exhibits bias against different demographic groups, such as gender and race, remains unclear. To fill this gap, this paper investigates ChatGPT-based automated coding of communication data using a typical coding framework for collaborative problem solving, examining differences across gender and racial groups. The analysis draws on data from three types of collaborative tasks: negotiation, problem solving, and decision making. Our results show that ChatGPT-based coding exhibits no significant bias across gender and racial groups, paving the road for its adoption in large-scale assessment of collaboration and communication.
Test Security in Remote Testing Age: Perspectives from Process Data Analytics and AI
Nov 20, 2024The COVID-19 pandemic has accelerated the implementation and acceptance of remotely proctored high-stake assessments. While the flexible administration of the tests brings forth many values, it raises test security-related concerns. Meanwhile, artificial intelligence (AI) has witnessed tremendous advances in the last five years. Many AI tools (such as the very recent ChatGPT) can generate high-quality responses to test items. These new developments require test security research beyond the statistical analysis of scores and response time. Data analytics and AI methods based on clickstream process data can get us deeper insight into the test-taking process and hold great promise for securing remotely administered high-stakes tests. This chapter uses real-world examples to show that this is indeed the case.
Scaling up the Evaluation of Collaborative Problem Solving: Promises and Challenges of Coding Chat Data with ChatGPT
Nov 15, 2024



Collaborative problem solving (CPS) is widely recognized as a critical 21st century skill. Efficiently coding communication data is a big challenge in scaling up research on assessing CPS. This paper reports the findings on using ChatGPT to directly code CPS chat data by benchmarking performance across multiple datasets and coding frameworks. We found that ChatGPT-based coding outperformed human coding in tasks where the discussions were characterized by colloquial languages but fell short in tasks where the discussions dealt with specialized scientific terminology and contexts. The findings offer practical guidelines for researchers to develop strategies for efficient and scalable analysis of communication data from CPS tasks.
Evaluating AI-Generated Essays with GRE Analytical Writing Assessment
Oct 24, 2024
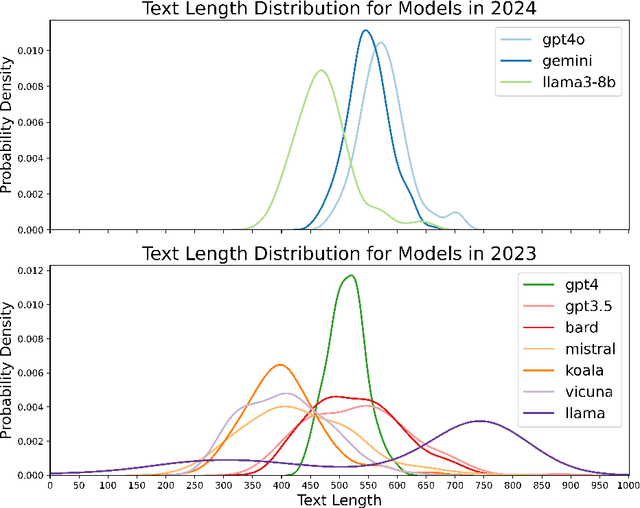

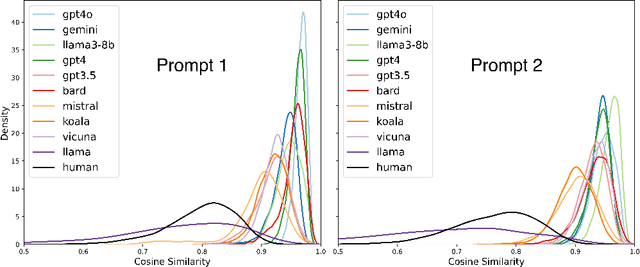
The recent revolutionary advance in generative AI enables the generation of realistic and coherent texts by large language models (LLMs). Despite many existing evaluation metrics on the quality of the generated texts, there is still a lack of rigorous assessment of how well LLMs perform in complex and demanding writing assessments. This study examines essays generated by ten leading LLMs for the analytical writing assessment of the Graduate Record Exam (GRE). We assessed these essays using both human raters and the e-rater automated scoring engine as used in the GRE scoring pipeline. Notably, the top-performing Gemini and GPT-4o received an average score of 4.78 and 4.67, respectively, falling between "generally thoughtful, well-developed analysis of the issue and conveys meaning clearly" and "presents a competent analysis of the issue and conveys meaning with acceptable clarity" according to the GRE scoring guideline. We also evaluated the detection accuracy of these essays, with detectors trained on essays generated by the same and different LLMs.
A GMBCG Galaxy Cluster Catalog of 55,424 Rich Clusters from SDSS DR7
Dec 22, 2010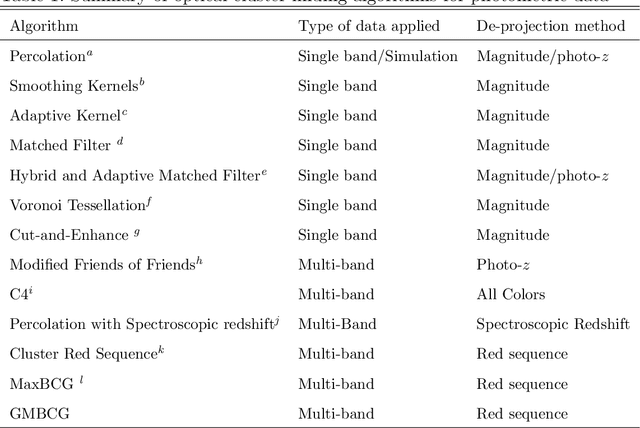
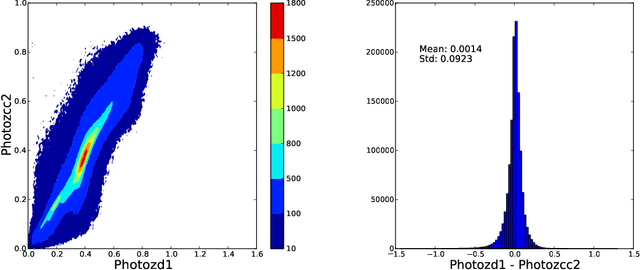
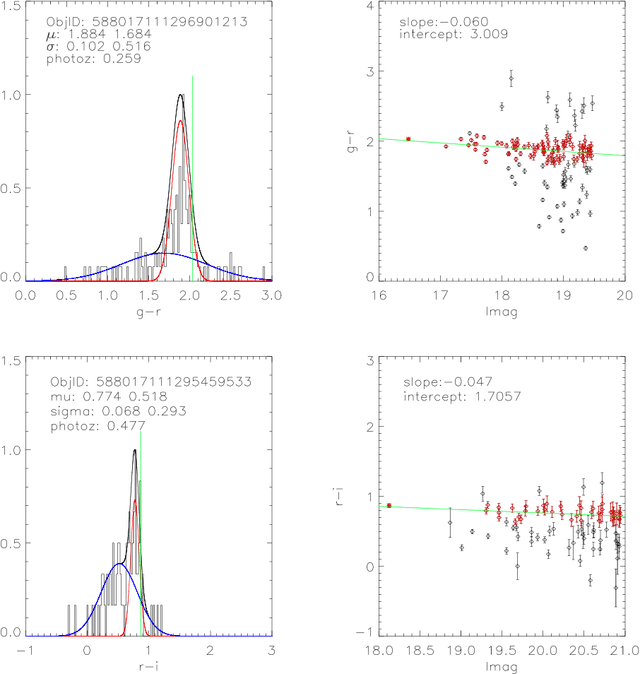
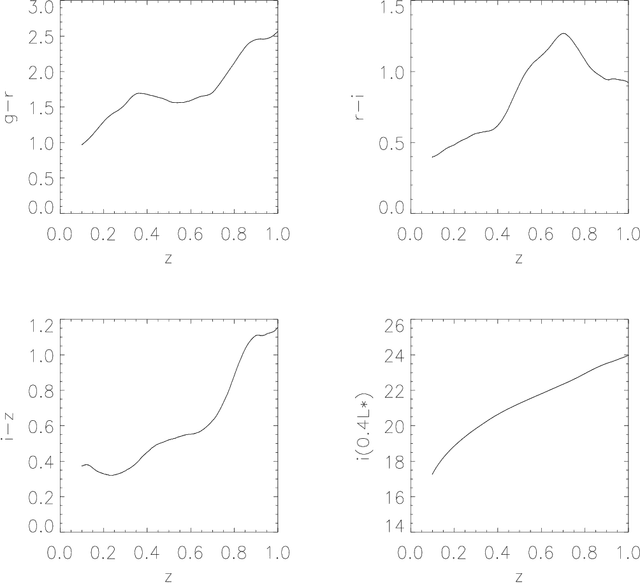
We present a large catalog of optically selected galaxy clusters from the application of a new Gaussian Mixture Brightest Cluster Galaxy (GMBCG) algorithm to SDSS Data Release 7 data. The algorithm detects clusters by identifying the red sequence plus Brightest Cluster Galaxy (BCG) feature, which is unique for galaxy clusters and does not exist among field galaxies. Red sequence clustering in color space is detected using an Error Corrected Gaussian Mixture Model. We run GMBCG on 8240 square degrees of photometric data from SDSS DR7 to assemble the largest ever optical galaxy cluster catalog, consisting of over 55,000 rich clusters across the redshift range from 0.1 < z < 0.55. We present Monte Carlo tests of completeness and purity and perform cross-matching with X-ray clusters and with the maxBCG sample at low redshift. These tests indicate high completeness and purity across the full redshift range for clusters with 15 or more members.
* Updated to match the published version. The catalog can be accessed from: http://home.fnal.gov/~jghao/gmbcg_sdss_catalog.html