 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating AI-Generated Essays with GRE Analytical Writing Assessment
Paper and Code
Oct 24, 2024
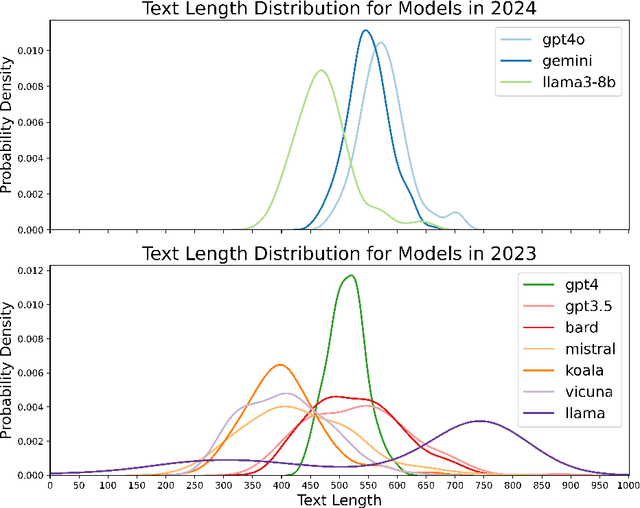

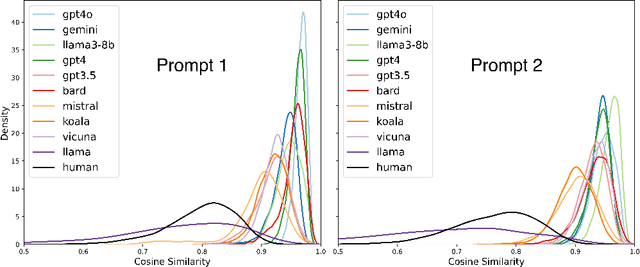
The recent revolutionary advance in generative AI enables the generation of realistic and coherent texts by large language models (LLMs). Despite many existing evaluation metrics on the quality of the generated texts, there is still a lack of rigorous assessment of how well LLMs perform in complex and demanding writing assessments. This study examines essays generated by ten leading LLMs for the analytical writing assessment of the Graduate Record Exam (GRE). We assessed these essays using both human raters and the e-rater automated scoring engine as used in the GRE scoring pipeline. Notably, the top-performing Gemini and GPT-4o received an average score of 4.78 and 4.67, respectively, falling between "generally thoughtful, well-developed analysis of the issue and conveys meaning clearly" and "presents a competent analysis of the issue and conveys meaning with acceptable clarity" according to the GRE scoring guideline. We also evaluated the detection accuracy of these essays, with detectors trained on essays generated by the same and different LLMs.