 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights into the origin of halo mass profiles from machine learning
May 09, 2022
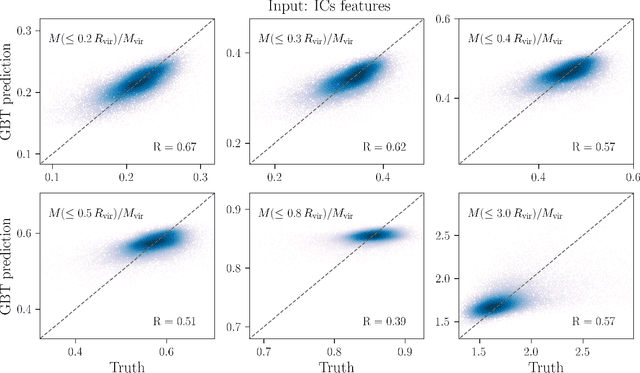
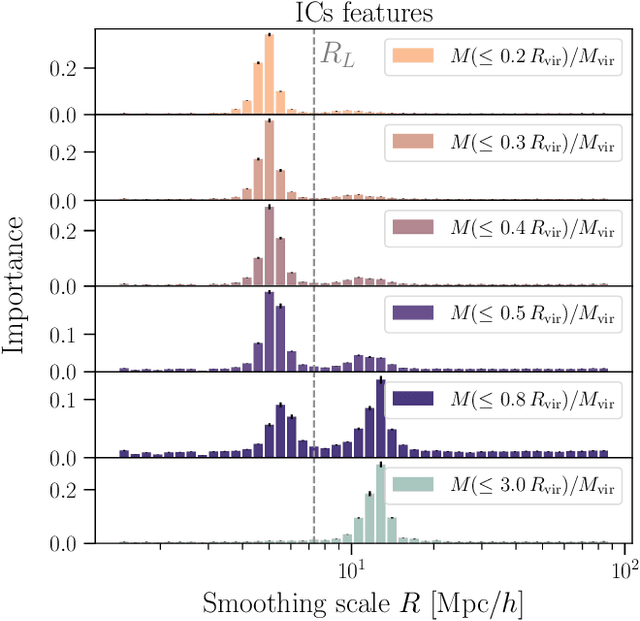

The mass distribution of dark matter haloes is the result of the hierarchical growth of initial density perturbations through mass accretion and mergers. We use an interpretable machine-learning framework to provide physical insights into the origin of the spherically-averaged mass profile of dark matter haloes. We train a gradient-boosted-trees algorithm to predict the final mass profiles of cluster-sized haloes, and measure the importance of the different inputs provided to the algorithm. We find two primary scales in the initial conditions (ICs) that impact the final mass profile: the density at approximately the scale of the haloes' Lagrangian patch $R_L$ ($R\sim 0.7\, R_L$) and that in the large-scale environment ($R\sim 1.7~R_L$). The model also identifies three primary time-scales in the halo assembly history that affect the final profile: (i) the formation time of the virialized, collapsed material inside the halo, (ii) the dynamical time, which captures the dynamically unrelaxed, infalling component of the halo over its first orbit, (iii) a third, most recent time-scale, which captures the impact on the outer profile of recent massive merger events. While the inner profile retains memory of the ICs, this information alone is insufficient to yield accurate predictions for the outer profile. As we add information about the haloes' mass accretion history, we find a significant improvement in the predicted profiles at all radii. Our machine-learning framework provides novel insights into the role of the ICs and the mass assembly history in determining the final mass profile of cluster-sized haloes.
Hierarchical Inference With Bayesian Neural Networks: An Application to Strong Gravitational Lensing
Oct 28, 2020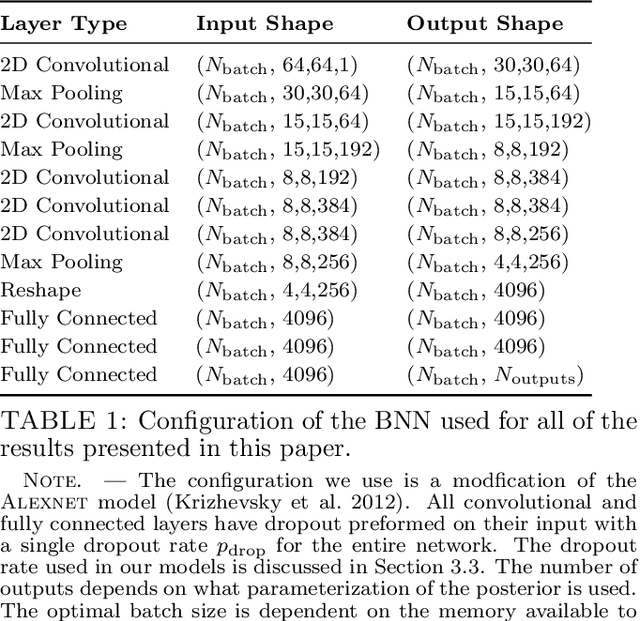
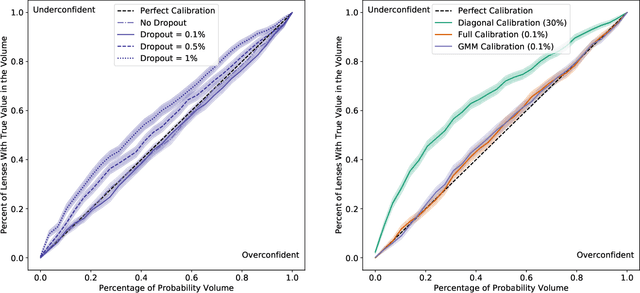
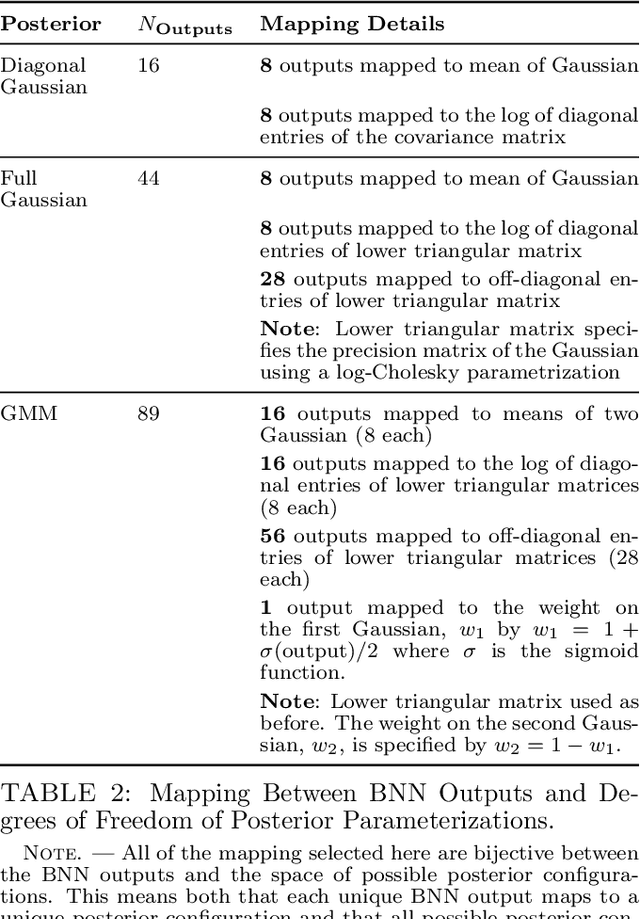
In the past few years, approximate Bayesian Neural Networks (BNNs) have demonstrated the ability to produce statistically consistent posteriors on a wide range of inference problems at unprecedented speed and scale. However, any disconnect between training sets and the distribution of real-world objects can introduce bias when BNNs are applied to data. This is a common challenge in astrophysics and cosmology, where the unknown distribution of objects in our Universe is often the science goal. In this work, we incorporate BNNs with flexible posterior parameterizations into a hierarchical inference framework that allows for the reconstruction of population hyperparameters and removes the bias introduced by the training distribution. We focus on the challenge of producing posterior PDFs for strong gravitational lens mass model parameters given Hubble Space Telescope (HST) quality single-filter, lens-subtracted, synthetic imaging data. We show that the posterior PDFs are sufficiently accurate (i.e., statistically consistent with the truth) across a wide variety of power-law elliptical lens mass distributions. We then apply our approach to test data sets whose lens parameters are drawn from distributions that are drastically different from the training set. We show that our hierarchical inference framework mitigates the bias introduced by an unrepresentative training set's interim prior. Simultaneously, given a sufficiently broad training set, we can precisely reconstruct the population hyperparameters governing our test distributions. Our full pipeline, from training to hierarchical inference on thousands of lenses, can be run in a day. The framework presented here will allow us to efficiently exploit the full constraining power of future ground- and space-based surveys.
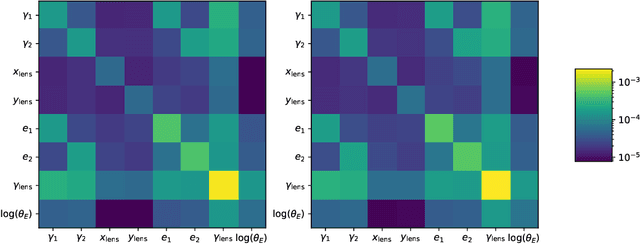
A GMBCG Galaxy Cluster Catalog of 55,424 Rich Clusters from SDSS DR7
Dec 22, 2010
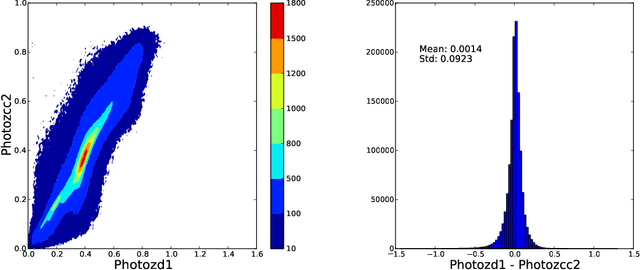
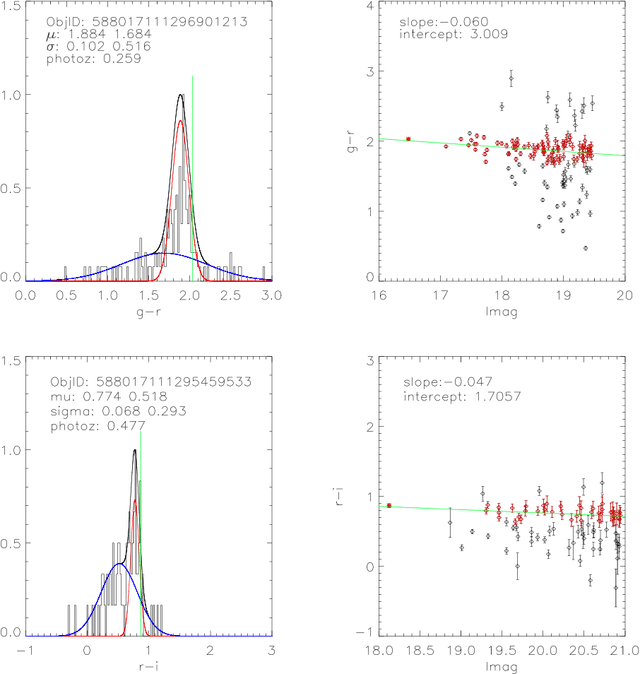
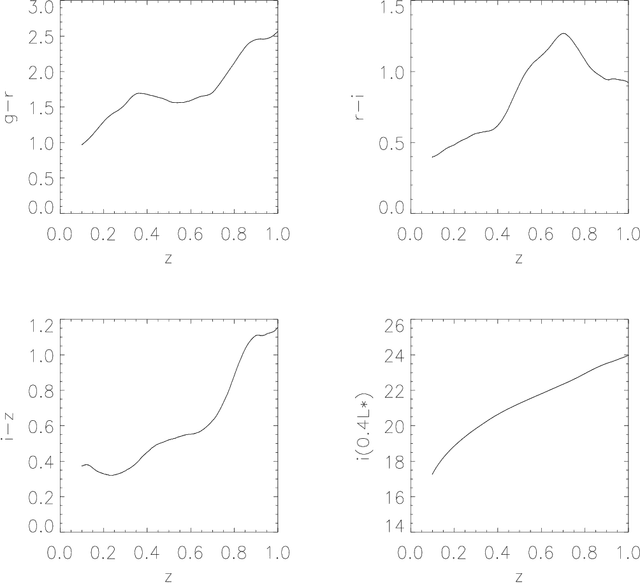
We present a large catalog of optically selected galaxy clusters from the application of a new Gaussian Mixture Brightest Cluster Galaxy (GMBCG) algorithm to SDSS Data Release 7 data. The algorithm detects clusters by identifying the red sequence plus Brightest Cluster Galaxy (BCG) feature, which is unique for galaxy clusters and does not exist among field galaxies. Red sequence clustering in color space is detected using an Error Corrected Gaussian Mixture Model. We run GMBCG on 8240 square degrees of photometric data from SDSS DR7 to assemble the largest ever optical galaxy cluster catalog, consisting of over 55,000 rich clusters across the redshift range from 0.1 < z < 0.55. We present Monte Carlo tests of completeness and purity and perform cross-matching with X-ray clusters and with the maxBCG sample at low redshift. These tests indicate high completeness and purity across the full redshift range for clusters with 15 or more members.
* Updated to match the published version. The catalog can be accessed from: http://home.fnal.gov/~jghao/gmbcg_sdss_catalog.html