 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAS-Bridge: A Bidirectional Generative Framework Bridging Next-Generation Astronomical Surveys
Mar 12, 2026The upcoming decade of observational cosmology will be shaped by large sky surveys, such as the ground-based LSST at the Vera C. Rubin Observatory and the space-based Euclid mission. While they promise an unprecedented view of the Universe across depth, resolution, and wavelength, their differences in observational modality, sky coverage, point-spread function, and scanning cadence make joint analysis beneficial, but also challenging. To facilitate joint analysis, we introduce A(stronomical)S(urvey)-Bridge, a bidirectional generative model that translates between ground- and space-based observations. AS-Bridge learns a diffusion model that employs a stochastic Brownian Bridge process between the LSST and Euclid observations. The two surveys have overlapping sky regions, where we can explicitly model the conditional probabilistic distribution between them. We show that this formulation enables new scientific capabilities beyond single-survey analysis, including faithful probabilistic predictions of missing survey observations and inter-survey detection of rare events. These results establish the feasibility of inter-survey generative modeling. AS-Bridge is therefore well-positioned to serve as a complementary component of future LSST-Euclid joint data pipelines, enhancing the scientific return once data from both surveys become available. Data and code are available at \href{https://github.com/ZHANG7DC/AS-Bridge}{https://github.com/ZHANG7DC/AS-Bridge}.
Hierarchical Inference of the Lensing Convergence from Photometric Catalogs with Bayesian Graph Neural Networks
Nov 15, 2022We present a Bayesian graph neural network (BGNN) that can estimate the weak lensing convergence ($\kappa$) from photometric measurements of galaxies along a given line of sight. The method is of particular interest in strong gravitational time delay cosmography (TDC), where characterizing the "external convergence" ($\kappa_{\rm ext}$) from the lens environment and line of sight is necessary for precise inference of the Hubble constant ($H_0$). Starting from a large-scale simulation with a $\kappa$ resolution of $\sim$1$'$, we introduce fluctuations on galaxy-galaxy lensing scales of $\sim$1$''$ and extract random sightlines to train our BGNN. We then evaluate the model on test sets with varying degrees of overlap with the training distribution. For each test set of 1,000 sightlines, the BGNN infers the individual $\kappa$ posteriors, which we combine in a hierarchical Bayesian model to yield constraints on the hyperparameters governing the population. For a test field well sampled by the training set, the BGNN recovers the population mean of $\kappa$ precisely and without bias, resulting in a contribution to the $H_0$ error budget well under 1\%. In the tails of the training set with sparse samples, the BGNN, which can ingest all available information about each sightline, extracts more $\kappa$ signal compared to a simplified version of the traditional method based on matching galaxy number counts, which is limited by sample variance. Our hierarchical inference pipeline using BGNNs promises to improve the $\kappa_{\rm ext}$ characterization for precision TDC. The implementation of our pipeline is available as a public Python package, Node to Joy.
Large-Scale Gravitational Lens Modeling with Bayesian Neural Networks for Accurate and Precise Inference of the Hubble Constant
Nov 30, 2020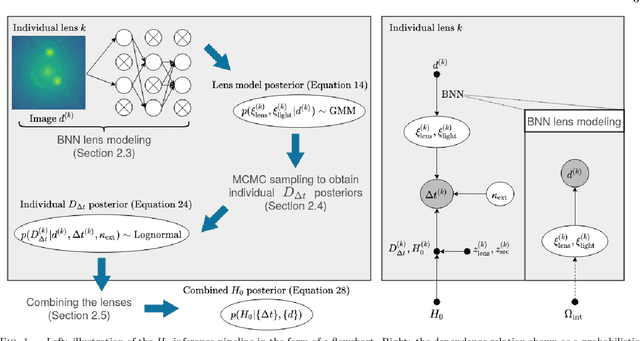
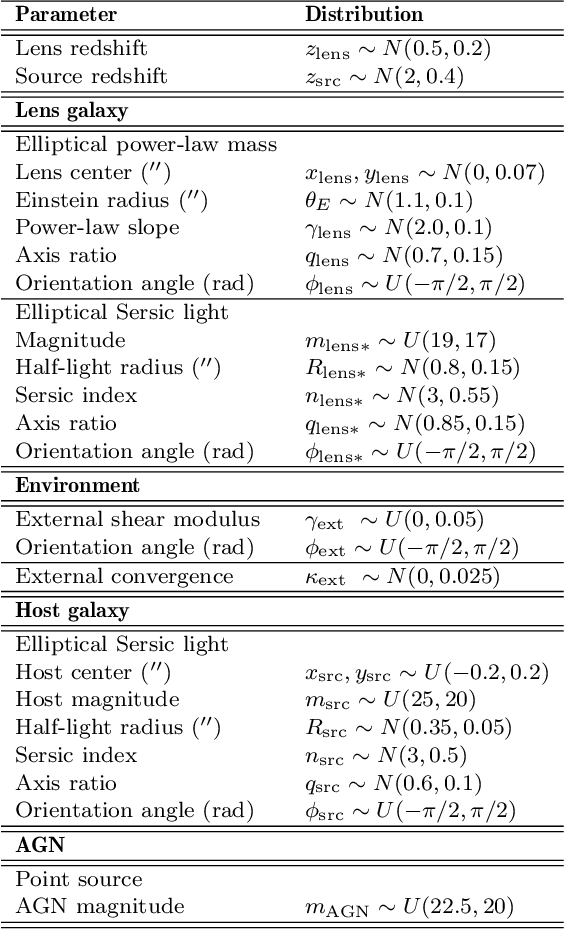
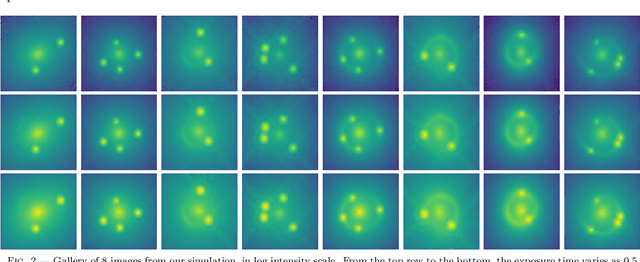
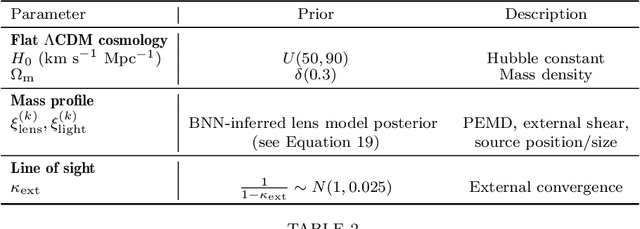
We investigate the use of approximate Bayesian neural networks (BNNs) in modeling hundreds of time-delay gravitational lenses for Hubble constant ($H_0$) determination. Our BNN was trained on synthetic HST-quality images of strongly lensed active galactic nuclei (AGN) with lens galaxy light included. The BNN can accurately characterize the posterior PDFs of model parameters governing the elliptical power-law mass profile in an external shear field. We then propagate the BNN-inferred posterior PDFs into ensemble $H_0$ inference, using simulated time delay measurements from a plausible dedicated monitoring campaign. Assuming well-measured time delays and a reasonable set of priors on the environment of the lens, we achieve a median precision of $9.3$\% per lens in the inferred $H_0$. A simple combination of 200 test-set lenses results in a precision of 0.5 $\textrm{km s}^{-1} \textrm{ Mpc}^{-1}$ ($0.7\%$), with no detectable bias in this $H_0$ recovery test. The computation time for the entire pipeline -- including the training set generation, BNN training, and $H_0$ inference -- translates to 9 minutes per lens on average for 200 lenses and converges to 6 minutes per lens as the sample size is increased. Being fully automated and efficient, our pipeline is a promising tool for exploring ensemble-level systematics in lens modeling for $H_0$ inference.
Hierarchical Inference With Bayesian Neural Networks: An Application to Strong Gravitational Lensing
Oct 28, 2020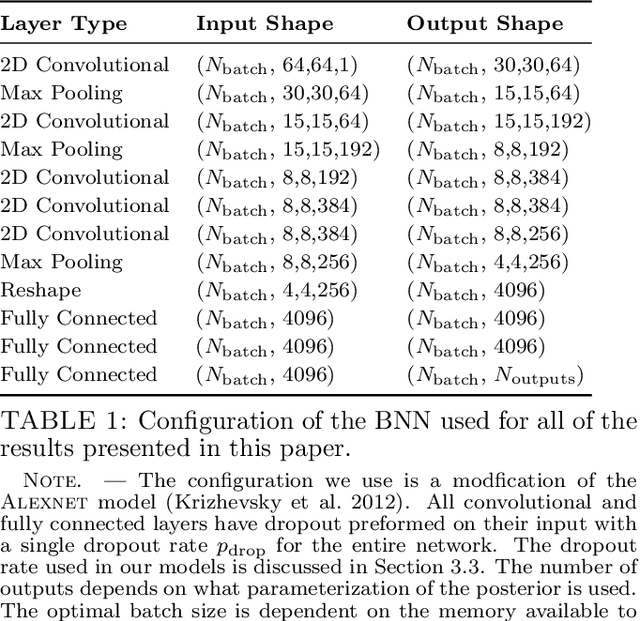
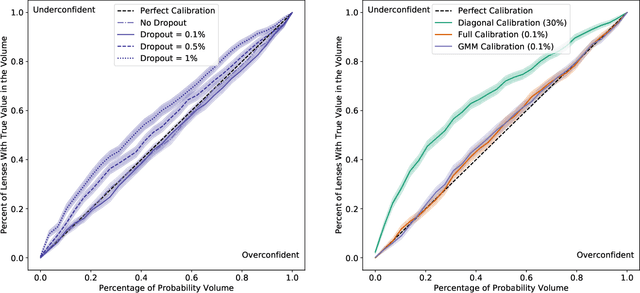
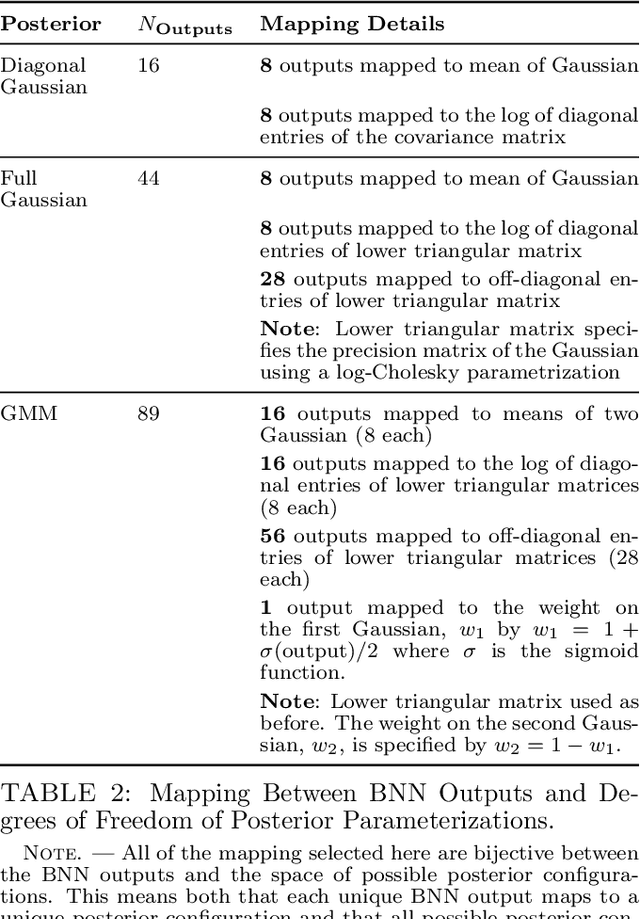
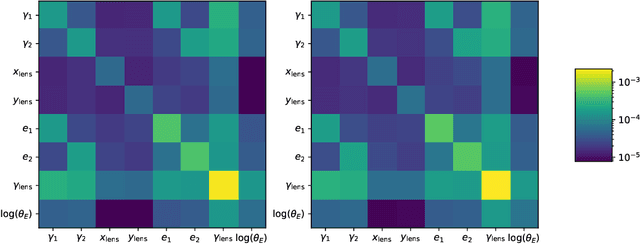
In the past few years, approximate Bayesian Neural Networks (BNNs) have demonstrated the ability to produce statistically consistent posteriors on a wide range of inference problems at unprecedented speed and scale. However, any disconnect between training sets and the distribution of real-world objects can introduce bias when BNNs are applied to data. This is a common challenge in astrophysics and cosmology, where the unknown distribution of objects in our Universe is often the science goal. In this work, we incorporate BNNs with flexible posterior parameterizations into a hierarchical inference framework that allows for the reconstruction of population hyperparameters and removes the bias introduced by the training distribution. We focus on the challenge of producing posterior PDFs for strong gravitational lens mass model parameters given Hubble Space Telescope (HST) quality single-filter, lens-subtracted, synthetic imaging data. We show that the posterior PDFs are sufficiently accurate (i.e., statistically consistent with the truth) across a wide variety of power-law elliptical lens mass distributions. We then apply our approach to test data sets whose lens parameters are drawn from distributions that are drastically different from the training set. We show that our hierarchical inference framework mitigates the bias introduced by an unrepresentative training set's interim prior. Simultaneously, given a sufficiently broad training set, we can precisely reconstruct the population hyperparameters governing our test distributions. Our full pipeline, from training to hierarchical inference on thousands of lenses, can be run in a day. The framework presented here will allow us to efficiently exploit the full constraining power of future ground- and space-based surveys.
Algorithms and Statistical Models for Scientific Discovery in the Petabyte Era
Nov 05, 2019The field of astronomy has arrived at a turning point in terms of size and complexity of both datasets and scientific collaboration. Commensurately, algorithms and statistical models have begun to adapt --- e.g., via the onset of artificial intelligence --- which itself presents new challenges and opportunities for growth. This white paper aims to offer guidance and ideas for how we can evolve our technical and collaborative frameworks to promote efficient algorithmic development and take advantage of opportunities for scientific discovery in the petabyte era. We discuss challenges for discovery in large and complex data sets; challenges and requirements for the next stage of development of statistical methodologies and algorithmic tool sets; how we might change our paradigms of collaboration and education; and the ethical implications of scientists' contributions to widely applicable algorithms and computational modeling. We start with six distinct recommendations that are supported by the commentary following them. This white paper is related to a larger corpus of effort that has taken place within and around the Petabytes to Science Workshops (https://petabytestoscience.github.io/).