 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Interests to Insights: An LLM Approach to Course Recommendations Using Natural Language Queries
Dec 30, 2024



Most universities in the United States encourage their students to explore academic areas before declaring a major and to acquire academic breadth by satisfying a variety of requirements. Each term, students must choose among many thousands of offerings, spanning dozens of subject areas, a handful of courses to take. The curricular environment is also dynamic, and poor communication and search functions on campus can limit a student's ability to discover new courses of interest. To support both students and their advisers in such a setting, we explore a novel Large Language Model (LLM) course recommendation system that applies a Retrieval Augmented Generation (RAG) method to the corpus of course descriptions. The system first generates an 'ideal' course description based on the user's query. This description is converted into a search vector using embeddings, which is then used to find actual courses with similar content by comparing embedding similarities. We describe the method and assess the quality and fairness of some example prompts. Steps to deploy a pilot system on campus are discussed.
From Interets to Insights: An LLM Approach to Course Recommendations Using Natural Language Queries
Dec 26, 2024Most universities in the United States encourage their students to explore academic areas before declaring a major and to acquire academic breadth by satisfying a variety of requirements. Each term, students must choose among many thousands of offerings, spanning dozens of subject areas, a handful of courses to take. The curricular environment is also dynamic, and poor communication and search functions on campus can limit a student's ability to discover new courses of interest. To support both students and their advisers in such a setting, we explore a novel Large Language Model (LLM) course recommendation system that applies a Retrieval Augmented Generation (RAG) method to the corpus of course descriptions. The system first generates an 'ideal' course description based on the user's query. This description is converted into a search vector using embeddings, which is then used to find actual courses with similar content by comparing embedding similarities. We describe the method and assess the quality and fairness of some example prompts. Steps to deploy a pilot system on campus are discussed.
A GMBCG Galaxy Cluster Catalog of 55,424 Rich Clusters from SDSS DR7
Dec 22, 2010
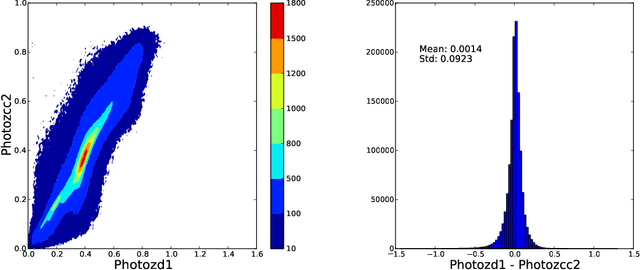
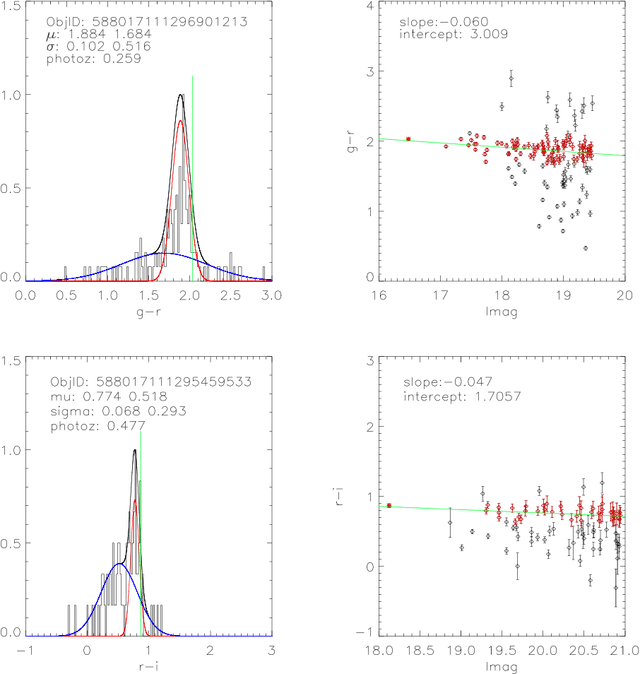
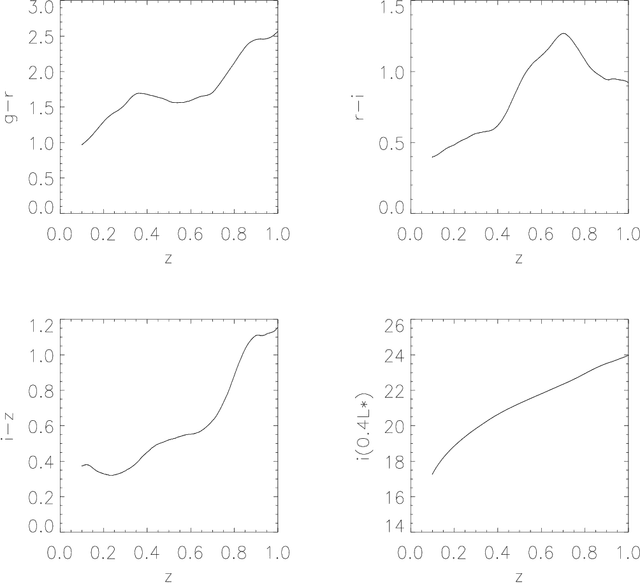
We present a large catalog of optically selected galaxy clusters from the application of a new Gaussian Mixture Brightest Cluster Galaxy (GMBCG) algorithm to SDSS Data Release 7 data. The algorithm detects clusters by identifying the red sequence plus Brightest Cluster Galaxy (BCG) feature, which is unique for galaxy clusters and does not exist among field galaxies. Red sequence clustering in color space is detected using an Error Corrected Gaussian Mixture Model. We run GMBCG on 8240 square degrees of photometric data from SDSS DR7 to assemble the largest ever optical galaxy cluster catalog, consisting of over 55,000 rich clusters across the redshift range from 0.1 < z < 0.55. We present Monte Carlo tests of completeness and purity and perform cross-matching with X-ray clusters and with the maxBCG sample at low redshift. These tests indicate high completeness and purity across the full redshift range for clusters with 15 or more members.
* Updated to match the published version. The catalog can be accessed from: http://home.fnal.gov/~jghao/gmbcg_sdss_catalog.html