 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynClaimEval: A Framework for Evaluating the Utility of Synthetic Data in Long-Context Claim Verification
Nov 12, 2025



Large Language Models (LLMs) with extended context windows promise direct reasoning over long documents, reducing the need for chunking or retrieval. Constructing annotated resources for training and evaluation, however, remains costly. Synthetic data offers a scalable alternative, and we introduce SynClaimEval, a framework for evaluating synthetic data utility in long-context claim verification -- a task central to hallucination detection and fact-checking. Our framework examines three dimensions: (i) input characteristics, by varying context length and testing generalization to out-of-domain benchmarks; (ii) synthesis logic, by controlling claim complexity and error type variation; and (iii) explanation quality, measuring the degree to which model explanations provide evidence consistent with predictions. Experiments across benchmarks show that long-context synthesis can improve verification in base instruction-tuned models, particularly when augmenting existing human-written datasets. Moreover, synthesis enhances explanation quality, even when verification scores do not improve, underscoring its potential to strengthen both performance and explainability.
ARC: Argument Representation and Coverage Analysis for Zero-Shot Long Document Summarization with Instruction Following LLMs
May 29, 2025Integrating structured information has long improved the quality of abstractive summarization, particularly in retaining salient content. In this work, we focus on a specific form of structure: argument roles, which are crucial for summarizing documents in high-stakes domains such as law. We investigate whether instruction-tuned large language models (LLMs) adequately preserve this information. To this end, we introduce Argument Representation Coverage (ARC), a framework for measuring how well LLM-generated summaries capture salient arguments. Using ARC, we analyze summaries produced by three open-weight LLMs in two domains where argument roles are central: long legal opinions and scientific articles. Our results show that while LLMs cover salient argument roles to some extent, critical information is often omitted in generated summaries, particularly when arguments are sparsely distributed throughout the input. Further, we use ARC to uncover behavioral patterns -- specifically, how the positional bias of LLM context windows and role-specific preferences impact the coverage of key arguments in generated summaries, emphasizing the need for more argument-aware summarization strategies.
Persuasiveness of Generated Free-Text Rationales in Subjective Decisions: A Case Study on Pairwise Argument Ranking
Jun 20, 2024Generating free-text rationales is among the emergent capabilities of Large Language Models (LLMs). These rationales have been found to enhance LLM performance across various NLP tasks. Recently, there has been growing interest in using these rationales to provide insights for various important downstream tasks. In this paper, we analyze generated free-text rationales in tasks with subjective answers, emphasizing the importance of rationalization in such scenarios. We focus on pairwise argument ranking, a highly subjective task with significant potential for real-world applications, such as debate assistance. We evaluate the persuasiveness of rationales generated by nine LLMs to support their subjective choices. Our findings suggest that open-source LLMs, particularly Llama2-70B-chat, are capable of providing highly persuasive rationalizations, surpassing even GPT models. Additionally, our experiments show that rationale persuasiveness can be improved by controlling its parameters through prompting or through self-refinement.
ReflectSumm: A Benchmark for Course Reflection Summarization
Mar 27, 2024



This paper introduces ReflectSumm, a novel summarization dataset specifically designed for summarizing students' reflective writing. The goal of ReflectSumm is to facilitate developing and evaluating novel summarization techniques tailored to real-world scenarios with little training data, %practical tasks with potential implications in the opinion summarization domain in general and the educational domain in particular. The dataset encompasses a diverse range of summarization tasks and includes comprehensive metadata, enabling the exploration of various research questions and supporting different applications. To showcase its utility, we conducted extensive evaluations using multiple state-of-the-art baselines. The results provide benchmarks for facilitating further research in this area.
Overview of ImageArg-2023: The First Shared Task in Multimodal Argument Mining
Oct 24, 2023This paper presents an overview of the ImageArg shared task, the first multimodal Argument Mining shared task co-located with the 10th Workshop on Argument Mining at EMNLP 2023. The shared task comprises two classification subtasks - (1) Subtask-A: Argument Stance Classification; (2) Subtask-B: Image Persuasiveness Classification. The former determines the stance of a tweet containing an image and a piece of text toward a controversial topic (e.g., gun control and abortion). The latter determines whether the image makes the tweet text more persuasive. The shared task received 31 submissions for Subtask-A and 21 submissions for Subtask-B from 9 different teams across 6 countries. The top submission in Subtask-A achieved an F1-score of 0.8647 while the best submission in Subtask-B achieved an F1-score of 0.5561.
Halo: Estimation and Reduction of Hallucinations in Open-Source Weak Large Language Models
Sep 13, 2023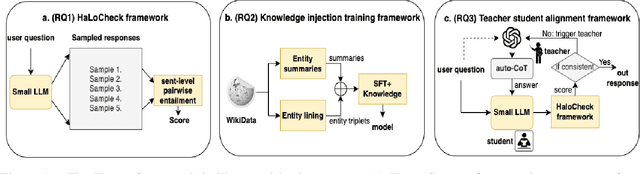
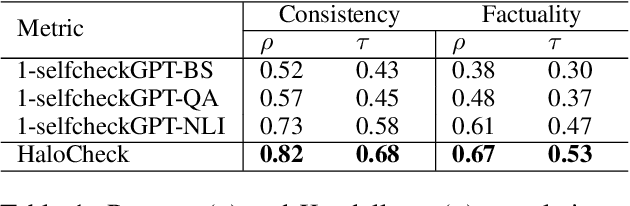
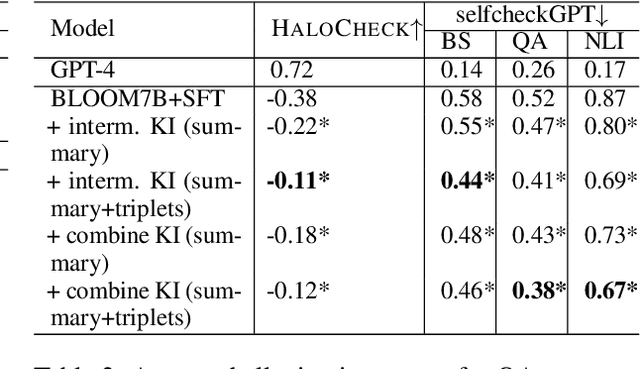
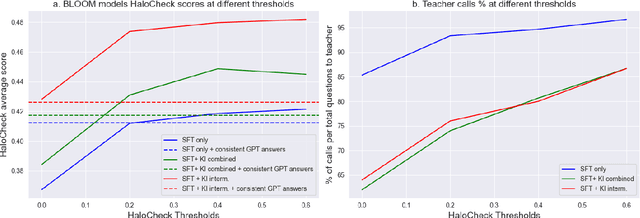
Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP). Although convenient for research and practical applications, open-source LLMs with fewer parameters often suffer from severe hallucinations compared to their larger counterparts. This paper focuses on measuring and reducing hallucinations in BLOOM 7B, a representative of such weaker open-source LLMs that are publicly available for research and commercial applications. We introduce HaloCheck, a lightweight BlackBox knowledge-free framework designed to quantify the severity of hallucinations in LLMs. Additionally, we explore techniques like knowledge injection and teacher-student approaches to alleviate hallucinations in low-parameter LLMs. Our experiments effectively demonstrate the reduction of hallucinations in challenging domains for these LLMs.
Towards Argument-Aware Abstractive Summarization of Long Legal Opinions with Summary Reranking
Jun 01, 2023We propose a simple approach for the abstractive summarization of long legal opinions that considers the argument structure of the document. Legal opinions often contain complex and nuanced argumentation, making it challenging to generate a concise summary that accurately captures the main points of the legal opinion. Our approach involves using argument role information to generate multiple candidate summaries, then reranking these candidates based on alignment with the document's argument structure. We demonstrate the effectiveness of our approach on a dataset of long legal opinions and show that it outperforms several strong baselines.
ArgLegalSumm: Improving Abstractive Summarization of Legal Documents with Argument Mining
Sep 20, 2022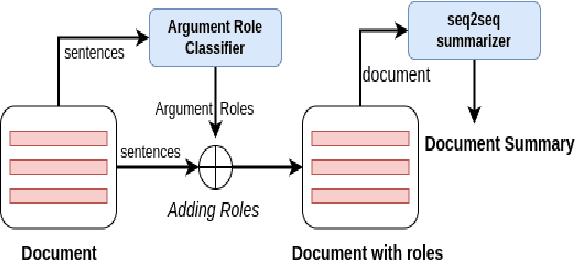

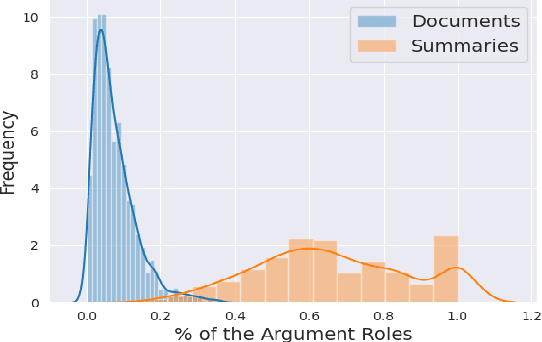

A challenging task when generating summaries of legal documents is the ability to address their argumentative nature. We introduce a simple technique to capture the argumentative structure of legal documents by integrating argument role labeling into the summarization process. Experiments with pretrained language models show that our proposed approach improves performance over strong baselines
Exploring Multitask Learning for Low-Resource AbstractiveSummarization
Sep 17, 2021
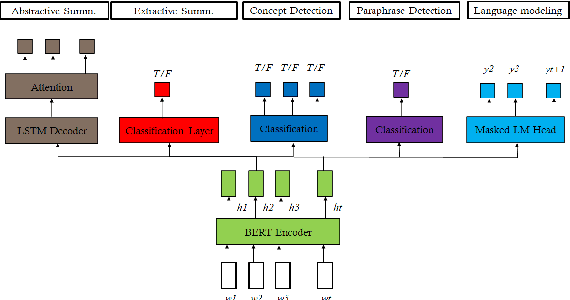


This paper explores the effect of using multitask learning for abstractive summarization in the context of small training corpora. In particular, we incorporate four different tasks (extractive summarization, language modeling, concept detection, and paraphrase detection) both individually and in combination, with the goal of enhancing the target task of abstractive summarization via multitask learning. We show that for many task combinations, a model trained in a multitask setting outperforms a model trained only for abstractive summarization, with no additional summarization data introduced. Additionally, we do a comprehensive search and find that certain tasks (e.g. paraphrase detection) consistently benefit abstractive summarization, not only when combined with other tasks but also when using different architectures and training corpora.