 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreak Distillation: Renewable Safety Benchmarking
May 28, 2025Large language models (LLMs) are rapidly deployed in critical applications, raising urgent needs for robust safety benchmarking. We propose Jailbreak Distillation (JBDistill), a novel benchmark construction framework that "distills" jailbreak attacks into high-quality and easily-updatable safety benchmarks. JBDistill utilizes a small set of development models and existing jailbreak attack algorithms to create a candidate prompt pool, then employs prompt selection algorithms to identify an effective subset of prompts as safety benchmarks. JBDistill addresses challenges in existing safety evaluation: the use of consistent evaluation prompts across models ensures fair comparisons and reproducibility. It requires minimal human effort to rerun the JBDistill pipeline and produce updated benchmarks, alleviating concerns on saturation and contamination. Extensive experiments demonstrate our benchmarks generalize robustly to 13 diverse evaluation models held out from benchmark construction, including proprietary, specialized, and newer-generation LLMs, significantly outperforming existing safety benchmarks in effectiveness while maintaining high separability and diversity. Our framework thus provides an effective, sustainable, and adaptable solution for streamlining safety evaluation.
Controllable Safety Alignment: Inference-Time Adaptation to Diverse Safety Requirements
Oct 11, 2024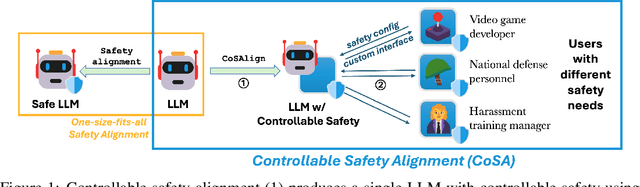
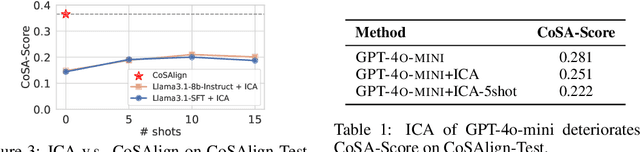
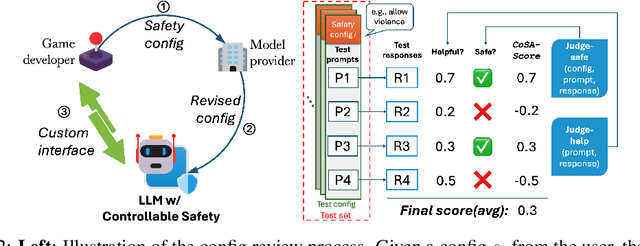
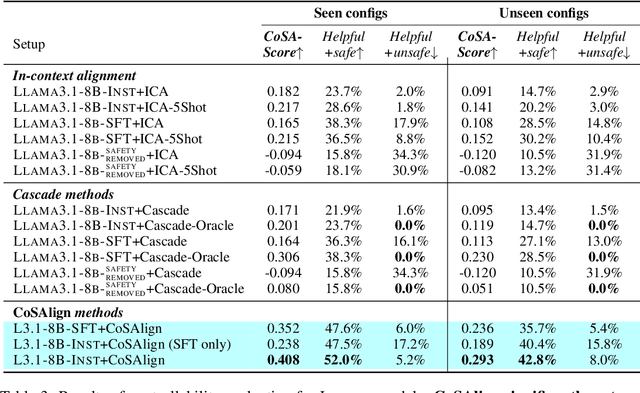
The current paradigm for safety alignment of large language models (LLMs) follows a one-size-fits-all approach: the model refuses to interact with any content deemed unsafe by the model provider. This approach lacks flexibility in the face of varying social norms across cultures and regions. In addition, users may have diverse safety needs, making a model with static safety standards too restrictive to be useful, as well as too costly to be re-aligned. We propose Controllable Safety Alignment (CoSA), a framework designed to adapt models to diverse safety requirements without re-training. Instead of aligning a fixed model, we align models to follow safety configs -- free-form natural language descriptions of the desired safety behaviors -- that are provided as part of the system prompt. To adjust model safety behavior, authorized users only need to modify such safety configs at inference time. To enable that, we propose CoSAlign, a data-centric method for aligning LLMs to easily adapt to diverse safety configs. Furthermore, we devise a novel controllability evaluation protocol that considers both helpfulness and configured safety, summarizing them into CoSA-Score, and construct CoSApien, a human-authored benchmark that consists of real-world LLM use cases with diverse safety requirements and corresponding evaluation prompts. We show that CoSAlign leads to substantial gains of controllability over strong baselines including in-context alignment. Our framework encourages better representation and adaptation to pluralistic human values in LLMs, and thereby increasing their practicality.
Persuasiveness of Generated Free-Text Rationales in Subjective Decisions: A Case Study on Pairwise Argument Ranking
Jun 20, 2024Generating free-text rationales is among the emergent capabilities of Large Language Models (LLMs). These rationales have been found to enhance LLM performance across various NLP tasks. Recently, there has been growing interest in using these rationales to provide insights for various important downstream tasks. In this paper, we analyze generated free-text rationales in tasks with subjective answers, emphasizing the importance of rationalization in such scenarios. We focus on pairwise argument ranking, a highly subjective task with significant potential for real-world applications, such as debate assistance. We evaluate the persuasiveness of rationales generated by nine LLMs to support their subjective choices. Our findings suggest that open-source LLMs, particularly Llama2-70B-chat, are capable of providing highly persuasive rationalizations, surpassing even GPT models. Additionally, our experiments show that rationale persuasiveness can be improved by controlling its parameters through prompting or through self-refinement.
LoSA: Long-Short-range Adapter for Scaling End-to-End Temporal Action Localization
Apr 01, 2024



Temporal Action Localization (TAL) involves localizing and classifying action snippets in an untrimmed video. The emergence of large video foundation models has led RGB-only video backbones to outperform previous methods needing both RGB and optical flow modalities. Leveraging these large models is often limited to training only the TAL head due to the prohibitively large GPU memory required to adapt the video backbone for TAL. To overcome this limitation, we introduce LoSA, the first memory-and-parameter-efficient backbone adapter designed specifically for TAL to handle untrimmed videos. LoSA specializes for TAL by introducing Long-Short-range Adapters that adapt the intermediate layers of the video backbone over different temporal ranges. These adapters run parallel to the video backbone to significantly reduce memory footprint. LoSA also includes Long-Short-range Fusion that strategically combines the output of these adapters from the video backbone layers to enhance the video features provided to the TAL head. Experiments show that LoSA significantly outperforms all existing methods on standard TAL benchmarks, THUMOS-14 and ActivityNet-v1.3, by scaling end-to-end backbone adaptation to billion-parameter-plus models like VideoMAEv2~(ViT-g) and leveraging them beyond head-only transfer learning.
A Framework for Automated Measurement of Responsible AI Harms in Generative AI Applications
Oct 26, 2023



We present a framework for the automated measurement of responsible AI (RAI) metrics for large language models (LLMs) and associated products and services. Our framework for automatically measuring harms from LLMs builds on existing technical and sociotechnical expertise and leverages the capabilities of state-of-the-art LLMs, such as GPT-4. We use this framework to run through several case studies investigating how different LLMs may violate a range of RAI-related principles. The framework may be employed alongside domain-specific sociotechnical expertise to create measurements for new harm areas in the future. By implementing this framework, we aim to enable more advanced harm measurement efforts and further the responsible use of LLMs.
Mitigating Data Scarceness through Data Synthesis, Augmentation and Curriculum for Abstractive Summarization
Sep 17, 2021
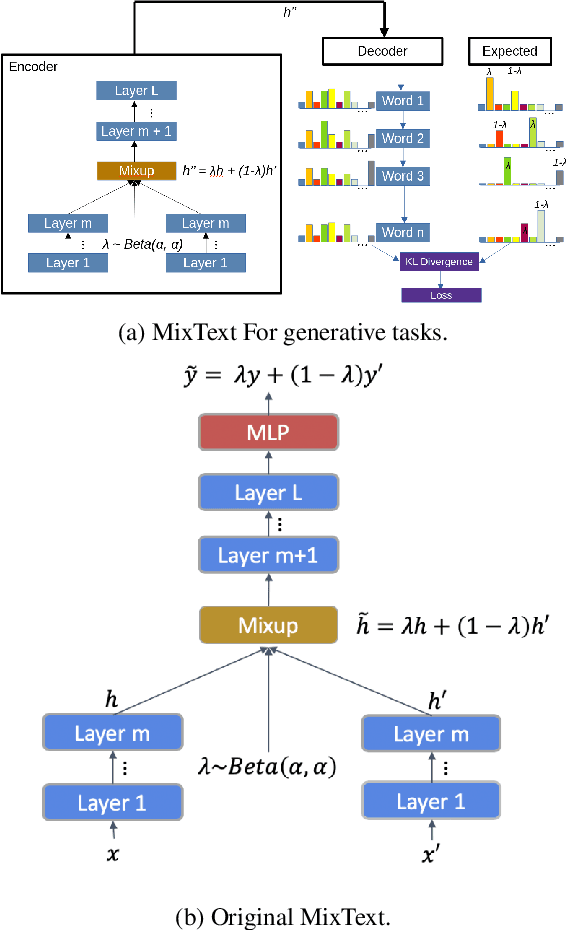
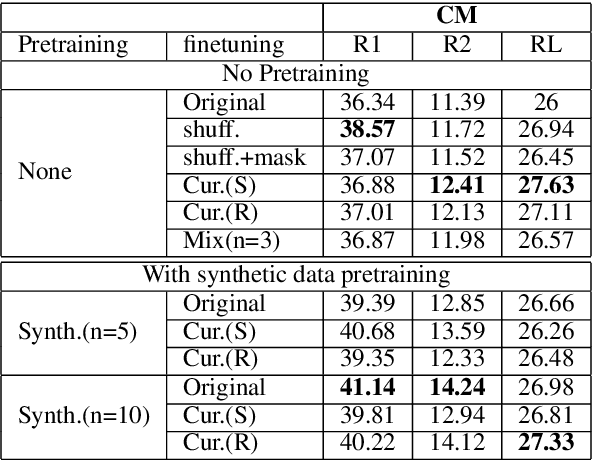
This paper explores three simple data manipulation techniques (synthesis, augmentation, curriculum) for improving abstractive summarization models without the need for any additional data. We introduce a method of data synthesis with paraphrasing, a data augmentation technique with sample mixing, and curriculum learning with two new difficulty metrics based on specificity and abstractiveness. We conduct experiments to show that these three techniques can help improve abstractive summarization across two summarization models and two different small datasets. Furthermore, we show that these techniques can improve performance when applied in isolation and when combined.
Exploring Multitask Learning for Low-Resource AbstractiveSummarization
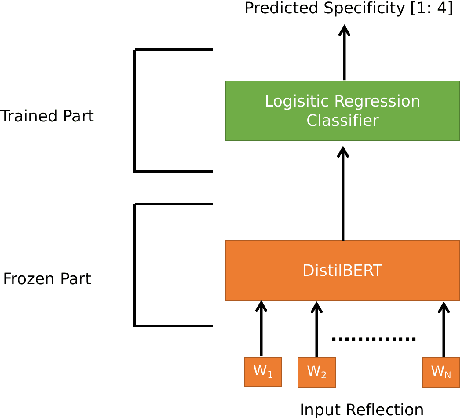
Sep 17, 2021
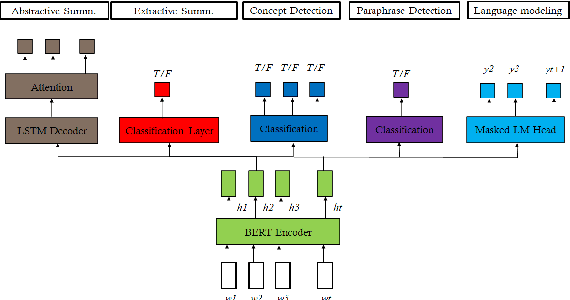


This paper explores the effect of using multitask learning for abstractive summarization in the context of small training corpora. In particular, we incorporate four different tasks (extractive summarization, language modeling, concept detection, and paraphrase detection) both individually and in combination, with the goal of enhancing the target task of abstractive summarization via multitask learning. We show that for many task combinations, a model trained in a multitask setting outperforms a model trained only for abstractive summarization, with no additional summarization data introduced. Additionally, we do a comprehensive search and find that certain tasks (e.g. paraphrase detection) consistently benefit abstractive summarization, not only when combined with other tasks but also when using different architectures and training corpora.
Abstractive Summarization for Low Resource Data using Domain Transfer and Data Synthesis
Feb 09, 2020
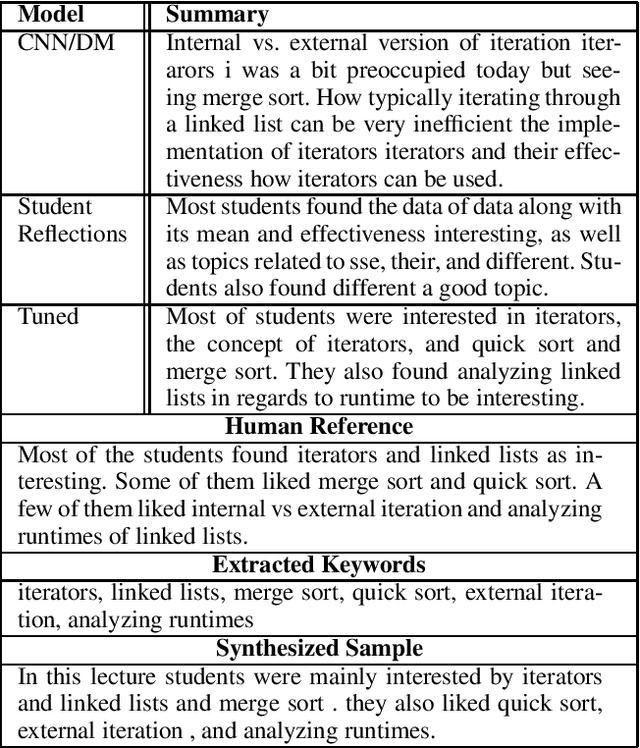
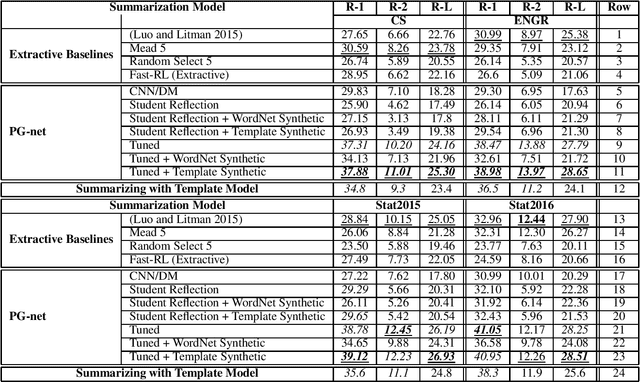
Training abstractive summarization models typically requires large amounts of data, which can be a limitation for many domains. In this paper we explore using domain transfer and data synthesis to improve the performance of recent abstractive summarization methods when applied to small corpora of student reflections. First, we explored whether tuning state of the art model trained on newspaper data could boost performance on student reflection data. Evaluations demonstrated that summaries produced by the tuned model achieved higher ROUGE scores compared to model trained on just student reflection data or just newspaper data. The tuned model also achieved higher scores compared to extractive summarization baselines, and additionally was judged to produce more coherent and readable summaries in human evaluations. Second, we explored whether synthesizing summaries of student data could additionally boost performance. We proposed a template-based model to synthesize new data, which when incorporated into training further increased ROUGE scores. Finally, we showed that combining data synthesis with domain transfer achieved higher ROUGE scores compared to only using one of the two approaches.
Attend to the beginning: A study on using bidirectional attention for extractive summarization
Feb 09, 2020
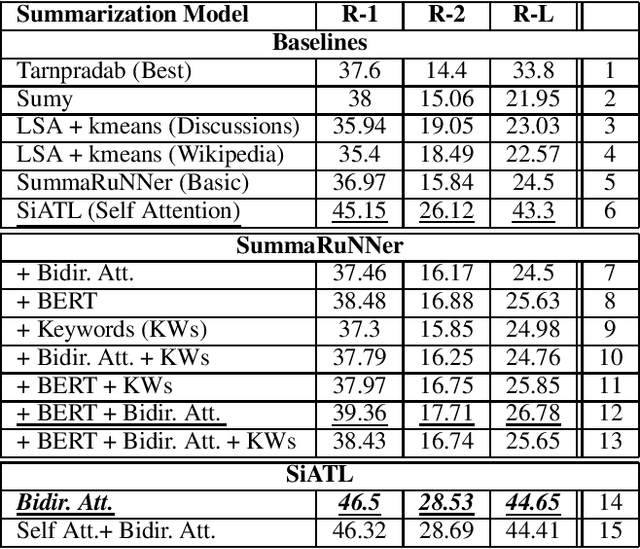


Forum discussion data differ in both structure and properties from generic form of textual data such as news. Henceforth, summarization techniques should, in turn, make use of such differences, and craft models that can benefit from the structural nature of discussion data. In this work, we propose attending to the beginning of a document, to improve the performance of extractive summarization models when applied to forum discussion data. Evaluations demonstrated that with the help of bidirectional attention mechanism, attending to the beginning of a document (initial comment/post) in a discussion thread, can introduce a consistent boost in ROUGE scores, as well as introducing a new State Of The Art (SOTA) ROUGE scores on the forum discussions dataset. Additionally, we explored whether this hypothesis is extendable to other generic forms of textual data. We make use of the tendency of introducing important information early in the text, by attending to the first few sentences in generic textual data. Evaluations demonstrated that attending to introductory sentences using bidirectional attention, improves the performance of extractive summarization models when even applied to more generic form of textual data.
eRevise: Using Natural Language Processing to Provide Formative Feedback on Text Evidence Usage in Student Writing
Aug 06, 2019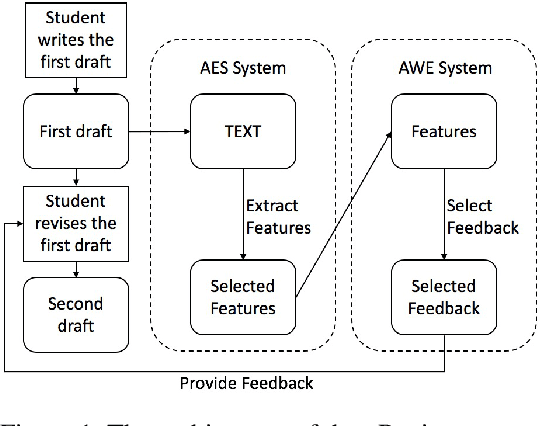

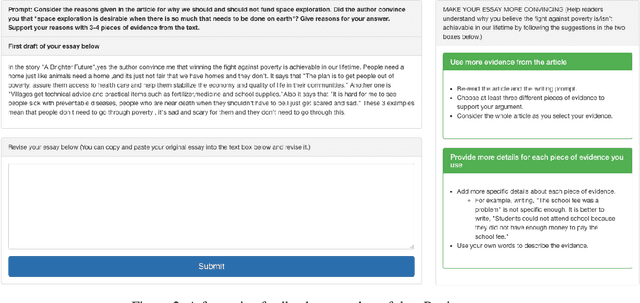
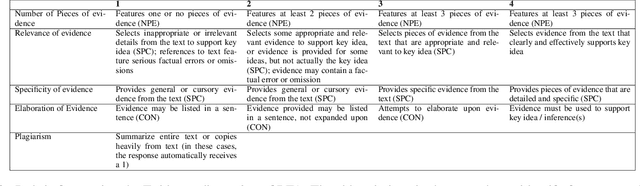
Writing a good essay typically involves students revising an initial paper draft after receiving feedback. We present eRevise, a web-based writing and revising environment that uses natural language processing features generated for rubric-based essay scoring to trigger formative feedback messages regarding students' use of evidence in response-to-text writing. By helping students understand the criteria for using text evidence during writing, eRevise empowers students to better revise their paper drafts. In a pilot deployment of eRevise in 7 classrooms spanning grades 5 and 6, the quality of text evidence usage in writing improved after students received formative feedback then engaged in paper revision.
* Published in IAAI 19