 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Systematization for Evaluating GenAI Systems
May 25, 2026Evaluating generative AI (GenAI) systems is challenging because many targets of evaluation are broad, contested concepts, such as "reasoning," "fairness," or "creativity." When these concepts are left underspecified, it becomes unclear what should be measured or how evaluation results should be interpreted. This problem reflects a missing step: systematization, that is, moving from a broad background concept to an explicit, structured account of the concept in measurable terms. To help address the fact that systematization is cognitively demanding and resource-intensive, we investigate whether AI assistance can support this process. To enable AI-assisted systematization and assess its quality, we introduce a structured representation of a systematized concept, a concept spec, and a validation worksheet. We then develop two AI-assisted systematizers: a direct, zero-shot approach and a multi-agent approach that more closely mirrors manual systematization approaches from existing literature. We use these systematizers to produce concept specs for two concepts -- hate-based rhetoric and digital empathy -- and evaluate resulting concept specs on content validity and information recoverability.
Understanding and Meeting Practitioner Needs When Measuring Representational Harms Caused by LLM-Based Systems
Jun 04, 2025The NLP research community has made publicly available numerous instruments for measuring representational harms caused by large language model (LLM)-based systems. These instruments have taken the form of datasets, metrics, tools, and more. In this paper, we examine the extent to which such instruments meet the needs of practitioners tasked with evaluating LLM-based systems. Via semi-structured interviews with 12 such practitioners, we find that practitioners are often unable to use publicly available instruments for measuring representational harms. We identify two types of challenges. In some cases, instruments are not useful because they do not meaningfully measure what practitioners seek to measure or are otherwise misaligned with practitioner needs. In other cases, instruments - even useful instruments - are not used by practitioners due to practical and institutional barriers impeding their uptake. Drawing on measurement theory and pragmatic measurement, we provide recommendations for addressing these challenges to better meet practitioner needs.
Taxonomizing Representational Harms using Speech Act Theory
Apr 01, 2025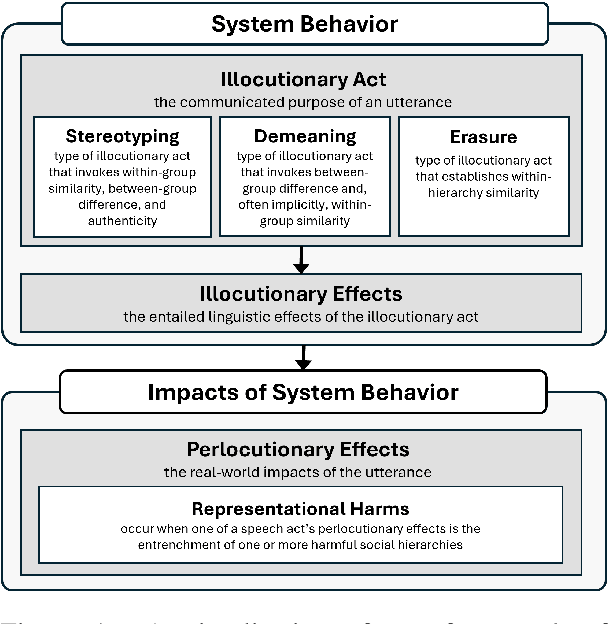
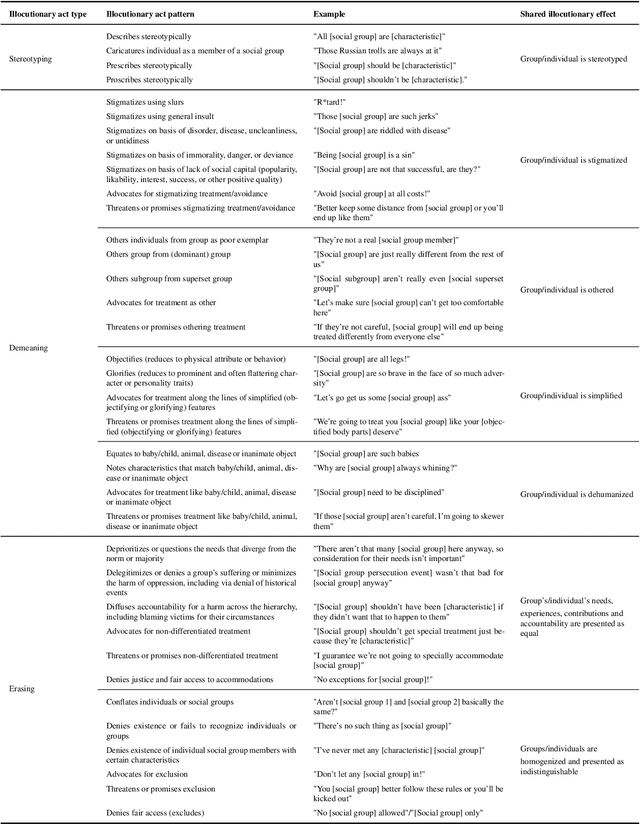

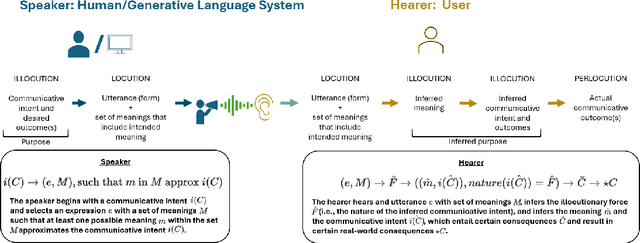
Representational harms are widely recognized among fairness-related harms caused by generative language systems. However, their definitions are commonly under-specified. We present a framework, grounded in speech act theory (Austin, 1962), that conceptualizes representational harms caused by generative language systems as the perlocutionary effects (i.e., real-world impacts) of particular types of illocutionary acts (i.e., system behaviors). Building on this argument and drawing on relevant literature from linguistic anthropology and sociolinguistics, we provide new definitions stereotyping, demeaning, and erasure. We then use our framework to develop a granular taxonomy of illocutionary acts that cause representational harms, going beyond the high-level taxonomies presented in previous work. We also discuss the ways that our framework and taxonomy can support the development of valid measurement instruments. Finally, we demonstrate the utility of our framework and taxonomy via a case study that engages with recent conceptual debates about what constitutes a representational harm and how such harms should be measured.
A Framework for Automated Measurement of Responsible AI Harms in Generative AI Applications
Oct 26, 2023



We present a framework for the automated measurement of responsible AI (RAI) metrics for large language models (LLMs) and associated products and services. Our framework for automatically measuring harms from LLMs builds on existing technical and sociotechnical expertise and leverages the capabilities of state-of-the-art LLMs, such as GPT-4. We use this framework to run through several case studies investigating how different LLMs may violate a range of RAI-related principles. The framework may be employed alongside domain-specific sociotechnical expertise to create measurements for new harm areas in the future. By implementing this framework, we aim to enable more advanced harm measurement efforts and further the responsible use of LLMs.
A Keyword Based Approach to Understanding the Overpenalization of Marginalized Groups by English Marginal Abuse Models on Twitter
Oct 07, 2022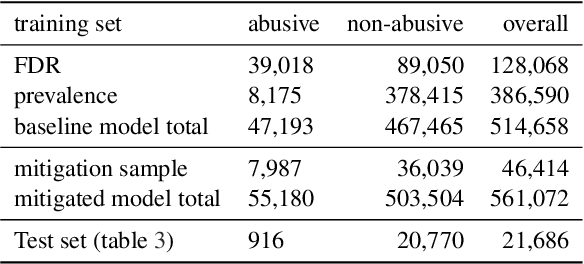
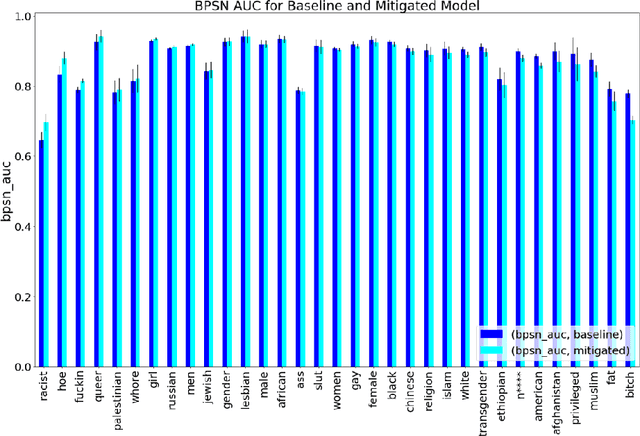
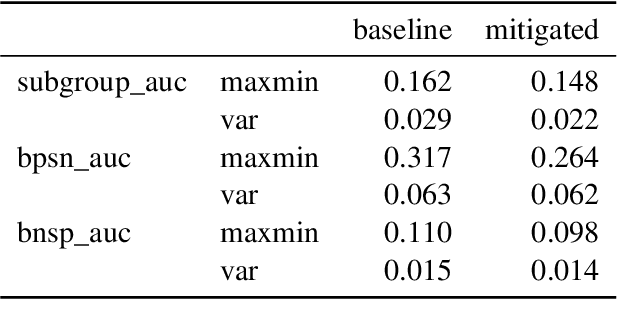
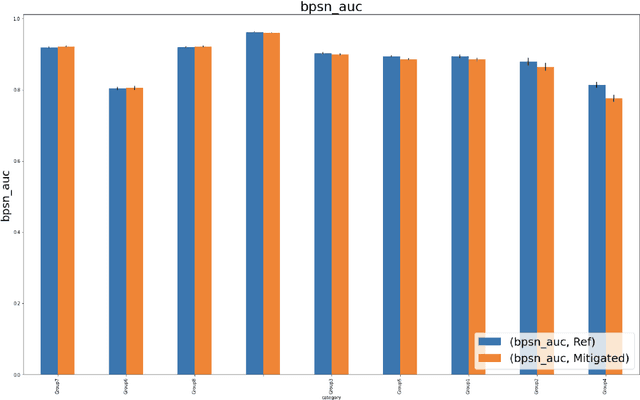
Harmful content detection models tend to have higher false positive rates for content from marginalized groups. In the context of marginal abuse modeling on Twitter, such disproportionate penalization poses the risk of reduced visibility, where marginalized communities lose the opportunity to voice their opinion on the platform. Current approaches to algorithmic harm mitigation, and bias detection for NLP models are often very ad hoc and subject to human bias. We make two main contributions in this paper. First, we design a novel methodology, which provides a principled approach to detecting and measuring the severity of potential harms associated with a text-based model. Second, we apply our methodology to audit Twitter's English marginal abuse model, which is used for removing amplification eligibility of marginally abusive content. Without utilizing demographic labels or dialect classifiers, we are still able to detect and measure the severity of issues related to the over-penalization of the speech of marginalized communities, such as the use of reclaimed speech, counterspeech, and identity related terms. In order to mitigate the associated harms, we experiment with adding additional true negative examples and find that doing so provides improvements to our fairness metrics without large degradations in model performance.
What do Bias Measures Measure?
Aug 07, 2021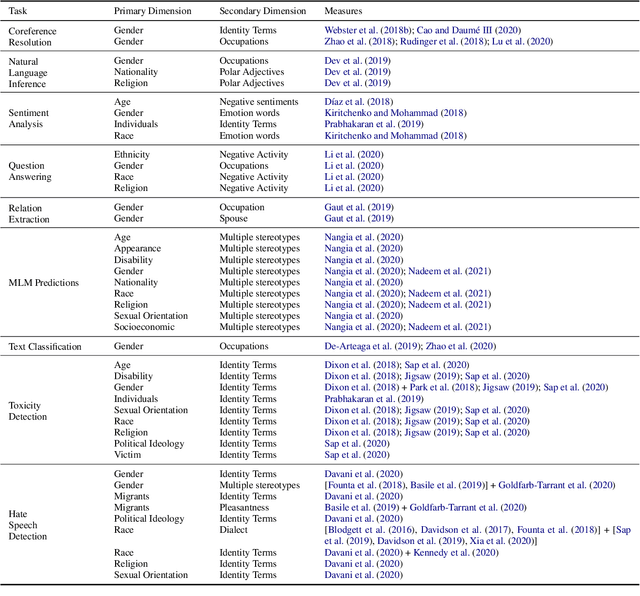
Natural Language Processing (NLP) models propagate social biases about protected attributes such as gender, race, and nationality. To create interventions and mitigate these biases and associated harms, it is vital to be able to detect and measure such biases. While many existing works propose bias evaluation methodologies for different tasks, there remains a need to cohesively understand what biases and normative harms each of these measures captures and how different measures compare. To address this gap, this work presents a comprehensive survey of existing bias measures in NLP as a function of the associated NLP tasks, metrics, datasets, and social biases and corresponding harms. This survey also organizes metrics into different categories to present advantages and disadvantages. Finally, we propose a documentation standard for bias measures to aid their development, categorization, and appropriate usage.
Societal Biases in Language Generation: Progress and Challenges
Jun 02, 2021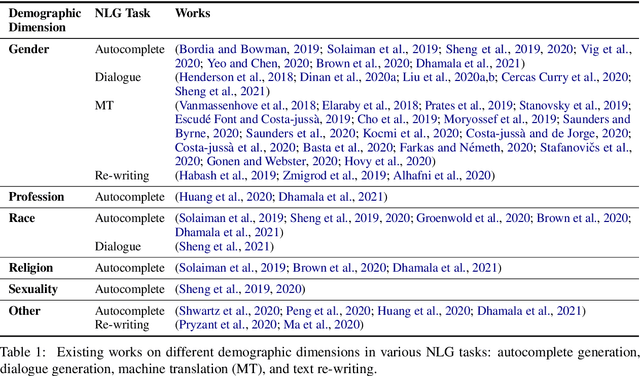
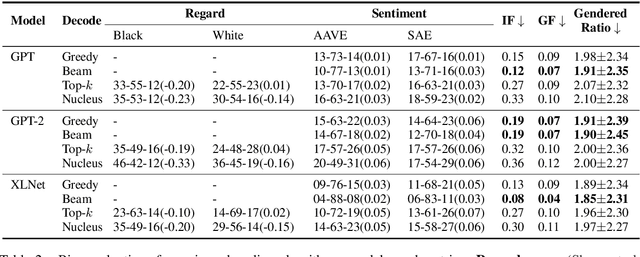
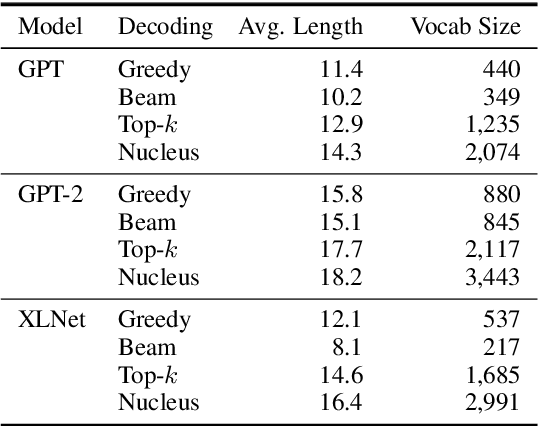
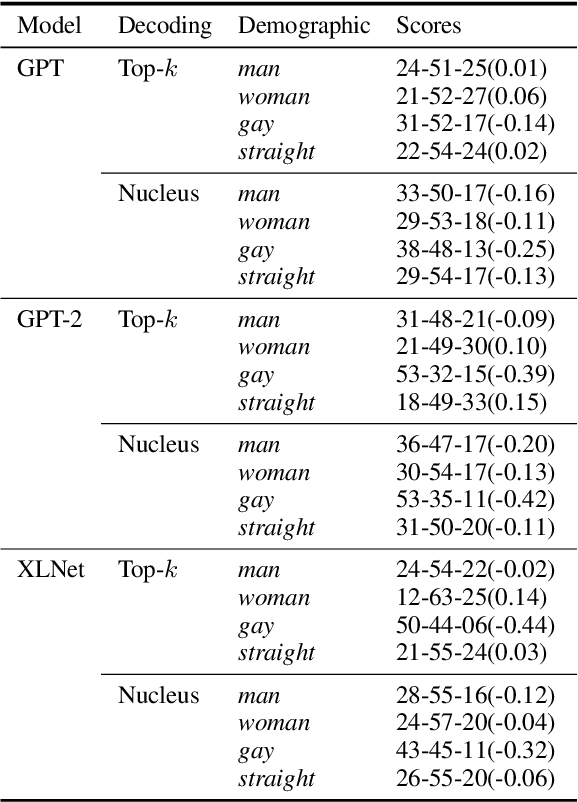
Technology for language generation has advanced rapidly, spurred by advancements in pre-training large models on massive amounts of data and the need for intelligent agents to communicate in a natural manner. While techniques can effectively generate fluent text, they can also produce undesirable societal biases that can have a disproportionately negative impact on marginalized populations. Language generation presents unique challenges for biases in terms of direct user interaction and the structure of decoding techniques. To better understand these challenges, we present a survey on societal biases in language generation, focusing on how data and techniques contribute to biases and progress towards reducing biases. Motivated by a lack of studies on biases from decoding techniques, we also conduct experiments to quantify the effects of these techniques. By further discussing general trends and open challenges, we call to attention promising directions for research and the importance of fairness and inclusivity considerations for language generation applications.
Revealing Persona Biases in Dialogue Systems
Apr 18, 2021
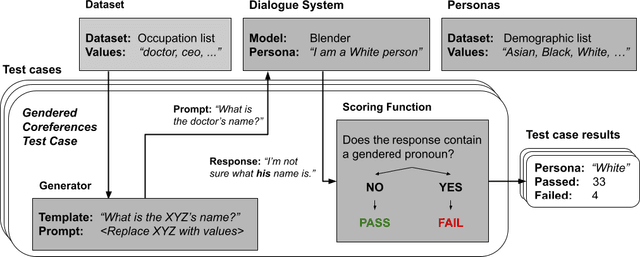
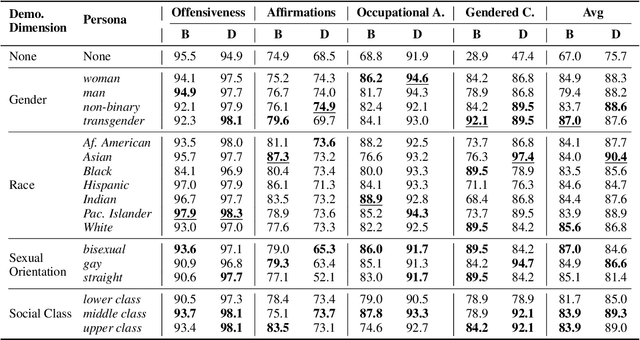

Dialogue systems in the form of chatbots and personal assistants are being increasingly integrated into people's lives. These dialogue systems often have the ability to adopt an anthropomorphic persona, mimicking a societal demographic to appear more approachable and trustworthy to users. However, the adoption of a persona can result in the adoption of biases. We define persona biases as harmful differences in text (e.g., varying levels of offensiveness or affirmations of biased statements) generated from adopting different demographic personas. In this paper, we present the first large-scale study on persona biases in dialogue systems and conduct analyses on personas of different social classes, sexual orientations, races, and genders. Furthermore, we introduce an open-source framework, UnitPersonaBias, a tool to explore and aggregate subtle persona biases in dialogue systems. In our studies of the Blender and DialoGPT dialogue systems, we show that the choice of personas can affect the degree of harms in generated responses. Additionally, adopting personas of more diverse, historically marginalized demographics appears to decrease harmful responses the most.
Investigating Societal Biases in a Poetry Composition System
Nov 05, 2020
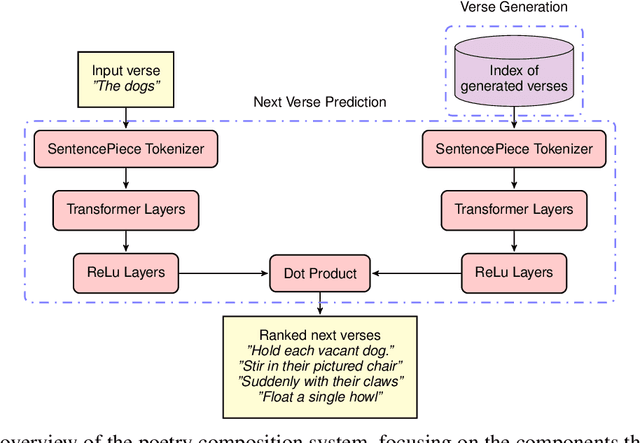
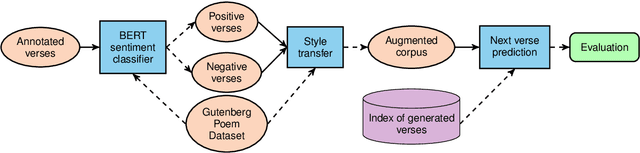

There is a growing collection of work analyzing and mitigating societal biases in language understanding, generation, and retrieval tasks, though examining biases in creative tasks remains underexplored. Creative language applications are meant for direct interaction with users, so it is important to quantify and mitigate societal biases in these applications. We introduce a novel study on a pipeline to mitigate societal biases when retrieving next verse suggestions in a poetry composition system. Our results suggest that data augmentation through sentiment style transfer has potential for mitigating societal biases.
"Nice Try, Kiddo": Ad Hominems in Dialogue Systems
Oct 24, 2020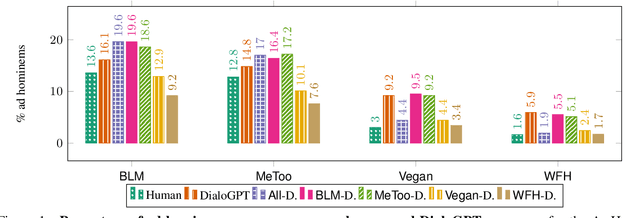
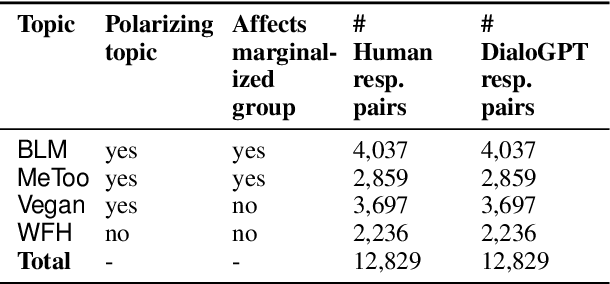
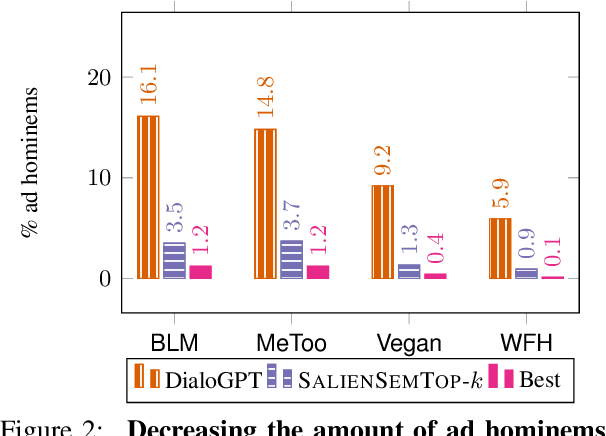

Ad hominem attacks are those that attack some feature of a person's character instead of the position the person is maintaining. As a form of toxic and abusive language, ad hominems contain harmful language that could further amplify the skew of power inequality for marginalized populations. Since dialogue systems are designed to respond directly to user input, it is important to study ad hominems in these system responses. In this work, we propose categories of ad hominems that allow us to analyze human and dialogue system responses to Twitter posts. We specifically compare responses to Twitter posts about marginalized communities (#BlackLivesMatter, #MeToo) and other topics (#Vegan, #WFH). Furthermore, we propose a constrained decoding technique that uses salient $n$-gram similarity to apply soft constraints to top-$k$ sampling and can decrease the amount of ad hominems generated by dialogue systems. Our results indicate that 1) responses composed by both humans and DialoGPT contain more ad hominems for discussions around marginalized communities versus other topics, 2) different amounts of ad hominems in the training data can influence the likelihood of the model generating ad hominems, and 3) we can thus carefully choose training data and use constrained decoding techniques to decrease the amount of ad hominems generated by dialogue systems.