 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocietal Biases in Language Generation: Progress and Challenges
Paper and Code
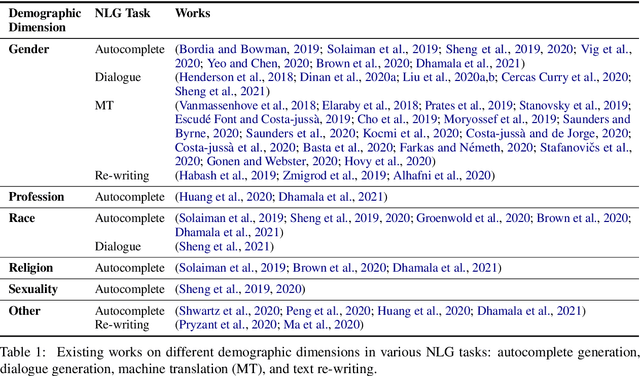
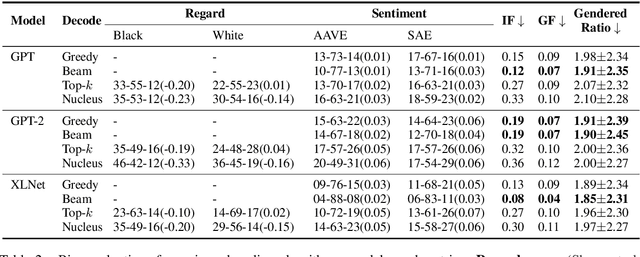
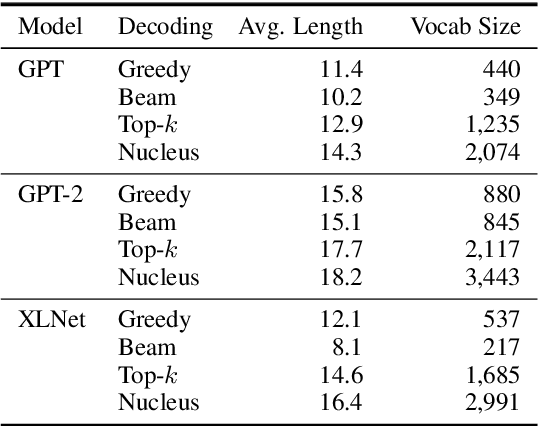
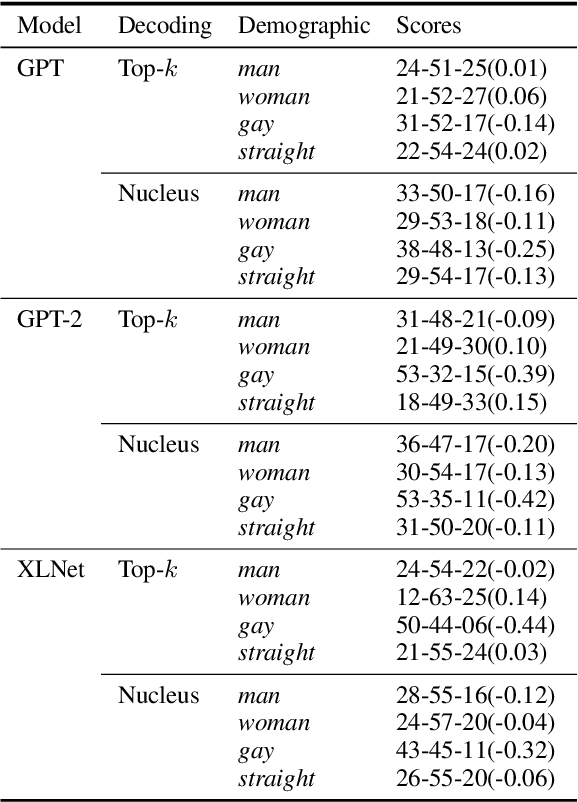
Technology for language generation has advanced rapidly, spurred by advancements in pre-training large models on massive amounts of data and the need for intelligent agents to communicate in a natural manner. While techniques can effectively generate fluent text, they can also produce undesirable societal biases that can have a disproportionately negative impact on marginalized populations. Language generation presents unique challenges for biases in terms of direct user interaction and the structure of decoding techniques. To better understand these challenges, we present a survey on societal biases in language generation, focusing on how data and techniques contribute to biases and progress towards reducing biases. Motivated by a lack of studies on biases from decoding techniques, we also conduct experiments to quantify the effects of these techniques. By further discussing general trends and open challenges, we call to attention promising directions for research and the importance of fairness and inclusivity considerations for language generation applications.