 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-X: Full Pipeline Acceleration of On-device AI Agents
May 11, 2026LLM-based agents deliver state-of-the-art performance across tasks but incur high end-to-end latency on edge devices. We introduce Agent-X, a software-only, accuracy-preserving framework that accelerates both the prefill and decode stages of on-device agent workloads. Agent-X's two key components rewrite prompts to leverage prefix caching tailored to agent-specific input-token patterns and enable LLM-free speculative decoding for fast token generation with minimal overhead. On representative agentic workloads, Agent-X achieves a 1.61x end-to-end speedup in real systems with no accuracy loss and can be seamlessly integrated into existing on-device AI agents. To the best of our knowledge, ours is the first to systematically characterize and eliminate latency bottlenecks in on-device agents.
The Cost of Dynamic Reasoning: Demystifying AI Agents and Test-Time Scaling from an AI Infrastructure Perspective
Jun 04, 2025



Large-language-model (LLM)-based AI agents have recently showcased impressive versatility by employing dynamic reasoning, an adaptive, multi-step process that coordinates with external tools. This shift from static, single-turn inference to agentic, multi-turn workflows broadens task generalization and behavioral flexibility, but it also introduces serious concerns about system-level cost, efficiency, and sustainability. This paper presents the first comprehensive system-level analysis of AI agents, quantifying their resource usage, latency behavior, energy consumption, and datacenter-wide power consumption demands across diverse agent designs and test-time scaling strategies. We further characterize how AI agent design choices, such as few-shot prompting, reflection depth, and parallel reasoning, impact accuracy-cost tradeoffs. Our findings reveal that while agents improve accuracy with increased compute, they suffer from rapidly diminishing returns, widening latency variance, and unsustainable infrastructure costs. Through detailed evaluation of representative agents, we highlight the profound computational demands introduced by AI agent workflows, uncovering a looming sustainability crisis. These results call for a paradigm shift in agent design toward compute-efficient reasoning, balancing performance with deployability under real-world constraints.
PREBA: A Hardware/Software Co-Design for Multi-Instance GPU based AI Inference Servers
Nov 28, 2024NVIDIA's Multi-Instance GPU (MIG) is a feature that enables system designers to reconfigure one large GPU into multiple smaller GPU slices. This work characterizes this emerging GPU and evaluates its effectiveness in designing high-performance AI inference servers. Our study reveals that the data preprocessing stage of AI inference causes significant performance bottlenecks to MIG. To this end, we present PREBA, which is a hardware/software co-design targeting MIG inference servers. Our first proposition is an FPGA-based data preprocessing accelerator that unlocks the full potential of MIG with domain-specific acceleration of data preprocessing. The MIG inference server unleashed from preprocessing overheads is then augmented with our dynamic batching system that enables high-performance inference. PREBA is implemented end-to-end in real systems, providing a 3.7x improvement in throughput, 3.4x reduction in tail latency, 3.5x improvement in energy-efficiency, and 3.0x improvement in cost-efficiency.
ElasticRec: A Microservice-based Model Serving Architecture Enabling Elastic Resource Scaling for Recommendation Models
Jun 11, 2024With the increasing popularity of recommendation systems (RecSys), the demand for compute resources in datacenters has surged. However, the model-wise resource allocation employed in current RecSys model serving architectures falls short in effectively utilizing resources, leading to sub-optimal total cost of ownership. We propose ElasticRec, a model serving architecture for RecSys providing resource elasticity and high memory efficiency. ElasticRec is based on a microservice-based software architecture for fine-grained resource allocation, tailored to the heterogeneous resource demands of RecSys. Additionally, ElasticRec achieves high memory efficiency via our utility-based resource allocation. Overall, ElasticRec achieves an average 3.3x reduction in memory allocation size and 8.1x increase in memory utility, resulting in an average 1.6x reduction in deployment cost compared to state-of-the-art RecSys inference serving system.
Helpfulness and Fairness of Task-Oriented Dialogue Systems
May 25, 2022
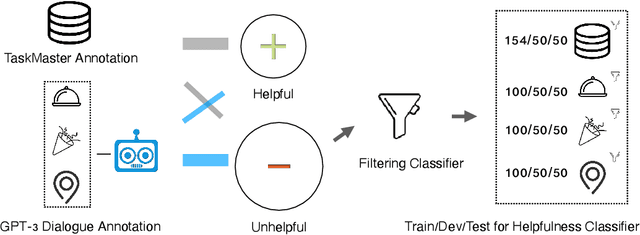

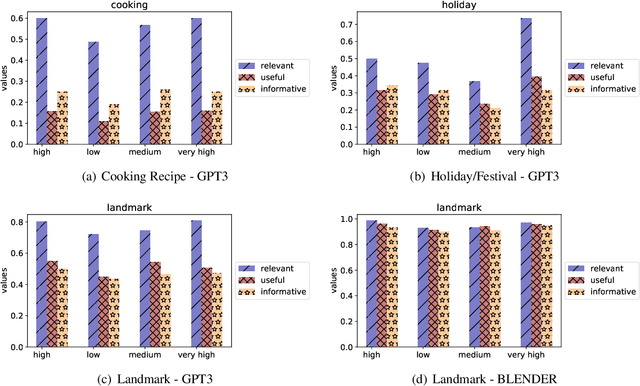
Task-oriented dialogue systems aim to answer questions from users and provide immediate help. Therefore, how humans perceive their helpfulness is important. However, neither the human-perceived helpfulness of task-oriented dialogue systems nor its fairness implication has been studied yet. In this paper, we define a dialogue response as helpful if it is relevant & coherent, useful, and informative to a query and study computational measurements of helpfulness. Then, we propose utilizing the helpfulness level of different groups to gauge the fairness of a dialogue system. To study this, we collect human annotations for the helpfulness of dialogue responses and build a classifier that can automatically determine the helpfulness of a response. We design experiments under 3 information-seeking scenarios and collect instances for each from Wikipedia. With collected instances, we use carefully-constructed questions to query the state-of-the-art dialogue systems. Through analysis, we find that dialogue systems tend to be more helpful for highly-developed countries than less-developed countries, uncovering a fairness issue underlying these dialogue systems.
What do Bias Measures Measure?
Aug 07, 2021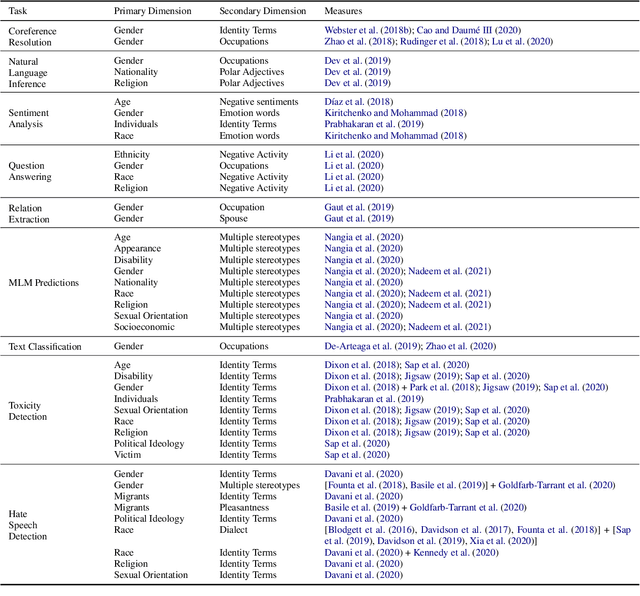
Natural Language Processing (NLP) models propagate social biases about protected attributes such as gender, race, and nationality. To create interventions and mitigate these biases and associated harms, it is vital to be able to detect and measure such biases. While many existing works propose bias evaluation methodologies for different tasks, there remains a need to cohesively understand what biases and normative harms each of these measures captures and how different measures compare. To address this gap, this work presents a comprehensive survey of existing bias measures in NLP as a function of the associated NLP tasks, metrics, datasets, and social biases and corresponding harms. This survey also organizes metrics into different categories to present advantages and disadvantages. Finally, we propose a documentation standard for bias measures to aid their development, categorization, and appropriate usage.