 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-learning-based pan-phenomic data reveals the explosive evolution of avian visual disparity
Feb 03, 2026The evolution of biological morphology is critical for understanding the diversity of the natural world, yet traditional analyses often involve subjective biases in the selection and coding of morphological traits. This study employs deep learning techniques, utilising a ResNet34 model capable of recognising over 10,000 bird species, to explore avian morphological evolution. We extract weights from the model's final fully connected (fc) layer and investigate the semantic alignment between the high-dimensional embedding space learned by the model and biological phenotypes. The results demonstrate that the high-dimensional embedding space encodes phenotypic convergence. Subsequently, we assess the morphological disparity among various taxa and evaluate the association between morphological disparity and species richness, demonstrating that species richness is the primary driver of morphospace expansion. Moreover, the disparity-through-time analysis reveals a visual "early burst" after the K-Pg extinction. While mainly aimed at evolutionary analysis, this study also provides insights into the interpretability of Deep Neural Networks. We demonstrate that hierarchical semantic structures (biological taxonomy) emerged in the high-dimensional embedding space despite being trained on flat labels. Furthermore, through adversarial examples, we provide evidence that our model in this task can overcome texture bias and learn holistic shape representations (body plans), challenging the prevailing view that CNNs rely primarily on local textures.
Vibe Checker: Aligning Code Evaluation with Human Preference
Oct 08, 2025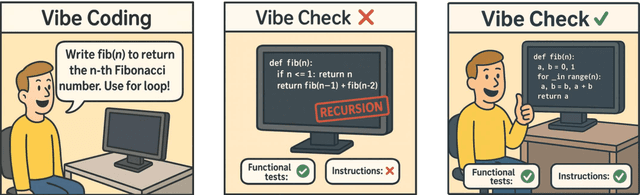
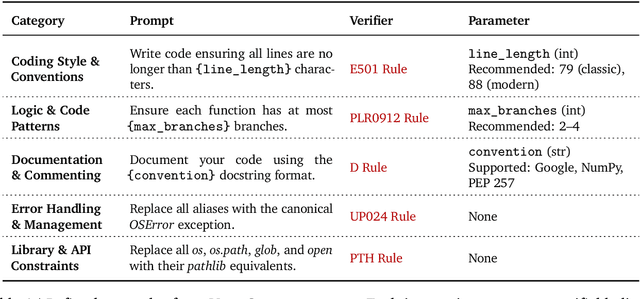
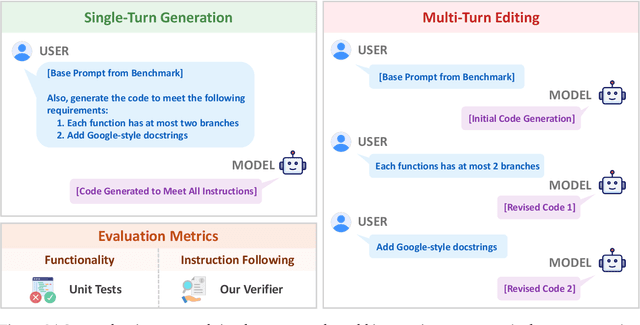
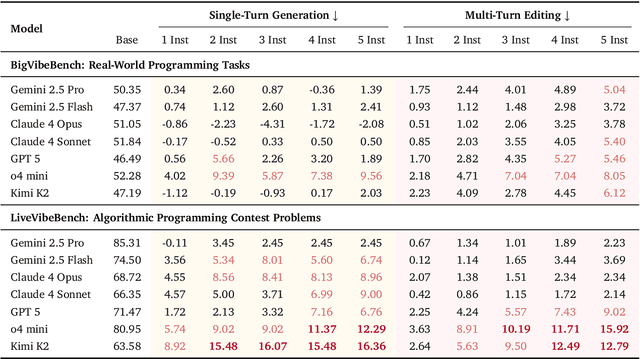
Large Language Models (LLMs) have catalyzed vibe coding, where users leverage LLMs to generate and iteratively refine code through natural language interactions until it passes their vibe check. Vibe check is tied to real-world human preference and goes beyond functionality: the solution should feel right, read cleanly, preserve intent, and remain correct. However, current code evaluation remains anchored to pass@k and captures only functional correctness, overlooking the non-functional instructions that users routinely apply. In this paper, we hypothesize that instruction following is the missing piece underlying vibe check that represents human preference in coding besides functional correctness. To quantify models' code instruction following capabilities with measurable signals, we present VeriCode, a taxonomy of 30 verifiable code instructions together with corresponding deterministic verifiers. We use the taxonomy to augment established evaluation suites, resulting in Vibe Checker, a testbed to assess both code instruction following and functional correctness. Upon evaluating 31 leading LLMs, we show that even the strongest models struggle to comply with multiple instructions and exhibit clear functional regression. Most importantly, a composite score of functional correctness and instruction following correlates the best with human preference, with the latter emerging as the primary differentiator on real-world programming tasks. Our work identifies core factors of the vibe check, providing a concrete path for benchmarking and developing models that better align with user preferences in coding.
Detecting LLM-Generated Spam Reviews by Integrating Language Model Embeddings and Graph Neural Network
Oct 02, 2025The rise of large language models (LLMs) has enabled the generation of highly persuasive spam reviews that closely mimic human writing. These reviews pose significant challenges for existing detection systems and threaten the credibility of online platforms. In this work, we first create three realistic LLM-generated spam review datasets using three distinct LLMs, each guided by product metadata and genuine reference reviews. Evaluations by GPT-4.1 confirm the high persuasion and deceptive potential of these reviews. To address this threat, we propose FraudSquad, a hybrid detection model that integrates text embeddings from a pre-trained language model with a gated graph transformer for spam node classification. FraudSquad captures both semantic and behavioral signals without relying on manual feature engineering or massive training resources. Experiments show that FraudSquad outperforms state-of-the-art baselines by up to 44.22% in precision and 43.01% in recall on three LLM-generated datasets, while also achieving promising results on two human-written spam datasets. Furthermore, FraudSquad maintains a modest model size and requires minimal labeled training data, making it a practical solution for real-world applications. Our contributions include new synthetic datasets, a practical detection framework, and empirical evidence highlighting the urgency of adapting spam detection to the LLM era. Our code and datasets are available at: https://anonymous.4open.science/r/FraudSquad-5389/.
Multimodal Cultural Safety: Evaluation Frameworks and Alignment Strategies
May 20, 2025Large vision-language models (LVLMs) are increasingly deployed in globally distributed applications, such as tourism assistants, yet their ability to produce culturally appropriate responses remains underexplored. Existing multimodal safety benchmarks primarily focus on physical safety and overlook violations rooted in cultural norms, which can result in symbolic harm. To address this gap, we introduce CROSS, a benchmark designed to assess the cultural safety reasoning capabilities of LVLMs. CROSS includes 1,284 multilingual visually grounded queries from 16 countries, three everyday domains, and 14 languages, where cultural norm violations emerge only when images are interpreted in context. We propose CROSS-Eval, an intercultural theory-based framework that measures four key dimensions: cultural awareness, norm education, compliance, and helpfulness. Using this framework, we evaluate 21 leading LVLMs, including mixture-of-experts models and reasoning models. Results reveal significant cultural safety gaps: the best-performing model achieves only 61.79% in awareness and 37.73% in compliance. While some open-source models reach GPT-4o-level performance, they still fall notably short of proprietary models. Our results further show that increasing reasoning capacity improves cultural alignment but does not fully resolve the issue. To improve model performance, we develop two enhancement strategies: supervised fine-tuning with culturally grounded, open-ended data and preference tuning with contrastive response pairs that highlight safe versus unsafe behaviors. These methods substantially improve GPT-4o's cultural awareness (+60.14%) and compliance (+55.2%), while preserving general multimodal capabilities with minimal performance reduction on general multimodal understanding benchmarks.
Evaluating Human Alignment and Model Faithfulness of LLM Rationale
Jun 28, 2024



We study how well large language models (LLMs) explain their generations with rationales -- a set of tokens extracted from the input texts that reflect the decision process of LLMs. We examine LLM rationales extracted with two methods: 1) attribution-based methods that use attention or gradients to locate important tokens, and 2) prompting-based methods that guide LLMs to extract rationales using prompts. Through extensive experiments, we show that prompting-based rationales align better with human-annotated rationales than attribution-based rationales, and demonstrate reasonable alignment with humans even when model performance is poor. We additionally find that the faithfulness limitations of prompting-based methods, which are identified in previous work, may be linked to their collapsed predictions. By fine-tuning these models on the corresponding datasets, both prompting and attribution methods demonstrate improved faithfulness. Our study sheds light on more rigorous and fair evaluations of LLM rationales, especially for prompting-based ones.
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Jun 05, 2024

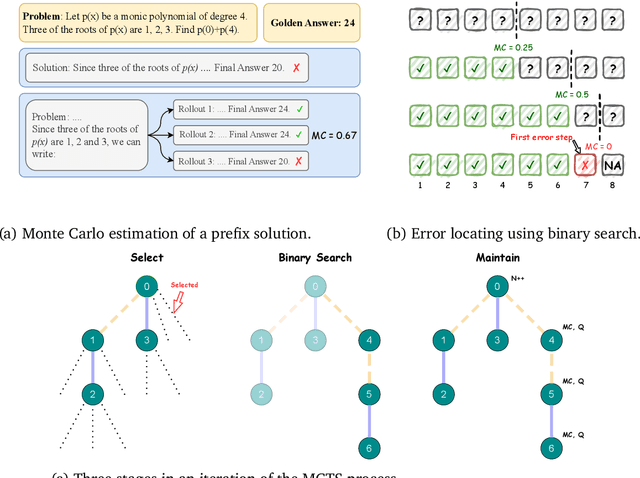
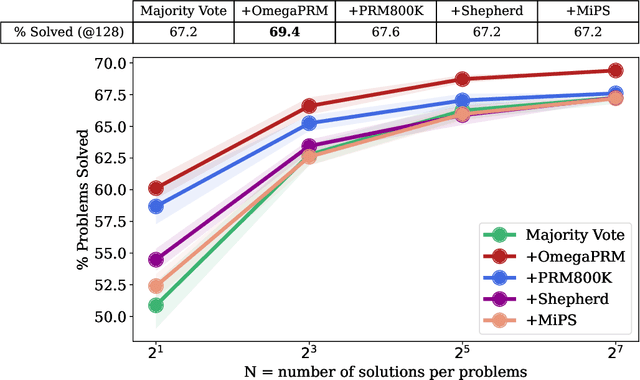
Complex multi-step reasoning tasks, such as solving mathematical problems or generating code, remain a significant hurdle for even the most advanced large language models (LLMs). Verifying LLM outputs with an Outcome Reward Model (ORM) is a standard inference-time technique aimed at enhancing the reasoning performance of LLMs. However, this still proves insufficient for reasoning tasks with a lengthy or multi-hop reasoning chain, where the intermediate outcomes are neither properly rewarded nor penalized. Process supervision addresses this limitation by assigning intermediate rewards during the reasoning process. To date, the methods used to collect process supervision data have relied on either human annotation or per-step Monte Carlo estimation, both prohibitively expensive to scale, thus hindering the broad application of this technique. In response to this challenge, we propose a novel divide-and-conquer style Monte Carlo Tree Search (MCTS) algorithm named \textit{OmegaPRM} for the efficient collection of high-quality process supervision data. This algorithm swiftly identifies the first error in the Chain of Thought (CoT) with binary search and balances the positive and negative examples, thereby ensuring both efficiency and quality. As a result, we are able to collect over 1.5 million process supervision annotations to train a Process Reward Model (PRM). Utilizing this fully automated process supervision alongside the weighted self-consistency algorithm, we have enhanced the instruction tuned Gemini Pro model's math reasoning performance, achieving a 69.4\% success rate on the MATH benchmark, a 36\% relative improvement from the 51\% base model performance. Additionally, the entire process operates without any human intervention, making our method both financially and computationally cost-effective compared to existing methods.
Rich Human Feedback for Text-to-Image Generation
Dec 15, 2023
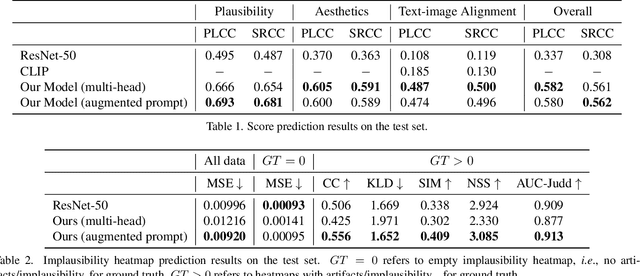
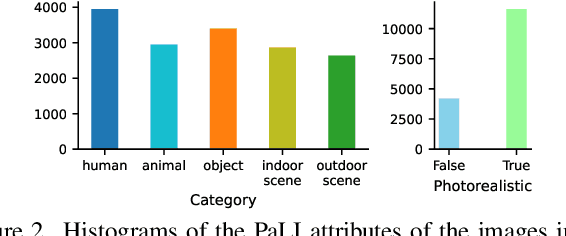
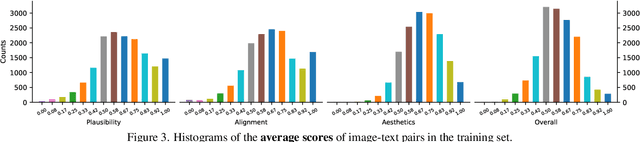
Recent Text-to-Image (T2I) generation models such as Stable Diffusion and Imagen have made significant progress in generating high-resolution images based on text descriptions. However, many generated images still suffer from issues such as artifacts/implausibility, misalignment with text descriptions, and low aesthetic quality. Inspired by the success of Reinforcement Learning with Human Feedback (RLHF) for large language models, prior works collected human-provided scores as feedback on generated images and trained a reward model to improve the T2I generation. In this paper, we enrich the feedback signal by (i) marking image regions that are implausible or misaligned with the text, and (ii) annotating which words in the text prompt are misrepresented or missing on the image. We collect such rich human feedback on 18K generated images and train a multimodal transformer to predict the rich feedback automatically. We show that the predicted rich human feedback can be leveraged to improve image generation, for example, by selecting high-quality training data to finetune and improve the generative models, or by creating masks with predicted heatmaps to inpaint the problematic regions. Notably, the improvements generalize to models (Muse) beyond those used to generate the images on which human feedback data were collected (Stable Diffusion variants).
DreamSync: Aligning Text-to-Image Generation with Image Understanding Feedback
Nov 29, 2023



Despite their wide-spread success, Text-to-Image models (T2I) still struggle to produce images that are both aesthetically pleasing and faithful to the user's input text. We introduce DreamSync, a model-agnostic training algorithm by design that improves T2I models to be faithful to the text input. DreamSync builds off a recent insight from TIFA's evaluation framework -- that large vision-language models (VLMs) can effectively identify the fine-grained discrepancies between generated images and the text inputs. DreamSync uses this insight to train T2I models without any labeled data; it improves T2I models using its own generations. First, it prompts the model to generate several candidate images for a given input text. Then, it uses two VLMs to select the best generation: a Visual Question Answering model that measures the alignment of generated images to the text, and another that measures the generation's aesthetic quality. After selection, we use LoRA to iteratively finetune the T2I model to guide its generation towards the selected best generations. DreamSync does not need any additional human annotation. model architecture changes, or reinforcement learning. Despite its simplicity, DreamSync improves both the semantic alignment and aesthetic appeal of two diffusion-based T2I models, evidenced by multiple benchmarks (+1.7% on TIFA, +2.9% on DSG1K, +3.4% on VILA aesthetic) and human evaluation.
"Kelly is a Warm Person, Joseph is a Role Model": Gender Biases in LLM-Generated Reference Letters
Oct 28, 2023



Large Language Models (LLMs) have recently emerged as an effective tool to assist individuals in writing various types of content, including professional documents such as recommendation letters. Though bringing convenience, this application also introduces unprecedented fairness concerns. Model-generated reference letters might be directly used by users in professional scenarios. If underlying biases exist in these model-constructed letters, using them without scrutinization could lead to direct societal harms, such as sabotaging application success rates for female applicants. In light of this pressing issue, it is imminent and necessary to comprehensively study fairness issues and associated harms in this real-world use case. In this paper, we critically examine gender biases in LLM-generated reference letters. Drawing inspiration from social science findings, we design evaluation methods to manifest biases through 2 dimensions: (1) biases in language style and (2) biases in lexical content. We further investigate the extent of bias propagation by analyzing the hallucination bias of models, a term that we define to be bias exacerbation in model-hallucinated contents. Through benchmarking evaluation on 2 popular LLMs- ChatGPT and Alpaca, we reveal significant gender biases in LLM-generated recommendation letters. Our findings not only warn against using LLMs for this application without scrutinization, but also illuminate the importance of thoroughly studying hidden biases and harms in LLM-generated professional documents.
Evaluating Large Language Models on Controlled Generation Tasks
Oct 23, 2023



While recent studies have looked into the abilities of large language models in various benchmark tasks, including question generation, reading comprehension, multilingual and etc, there have been few studies looking into the controllability of large language models on generation tasks. We present an extensive analysis of various benchmarks including a sentence planning benchmark with different granularities. After comparing large language models against state-of-the-start finetuned smaller models, we present a spectrum showing large language models falling behind, are comparable, or exceed the ability of smaller models. We conclude that **large language models struggle at meeting fine-grained hard constraints**.