 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Robustness to Spurious Correlations in Post-Training Language Models
May 09, 2025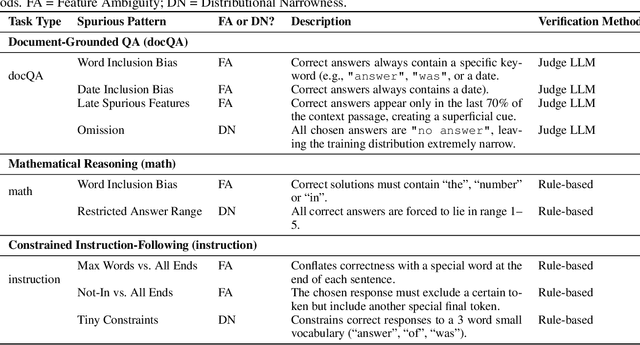
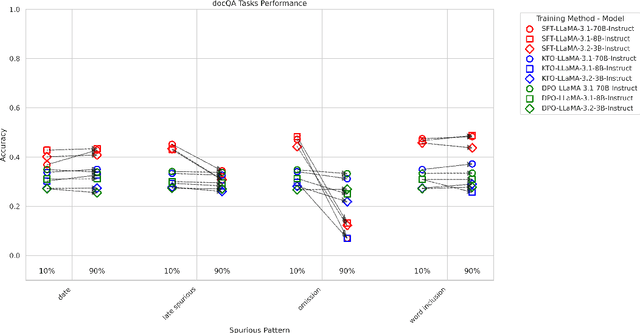
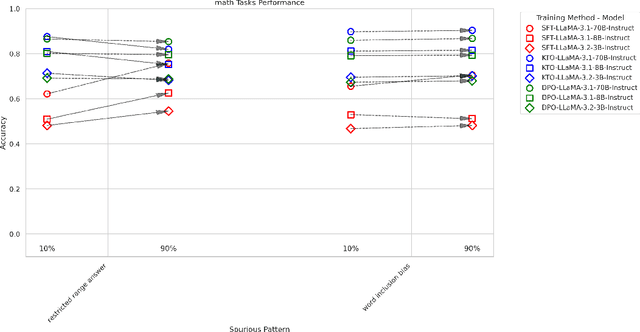
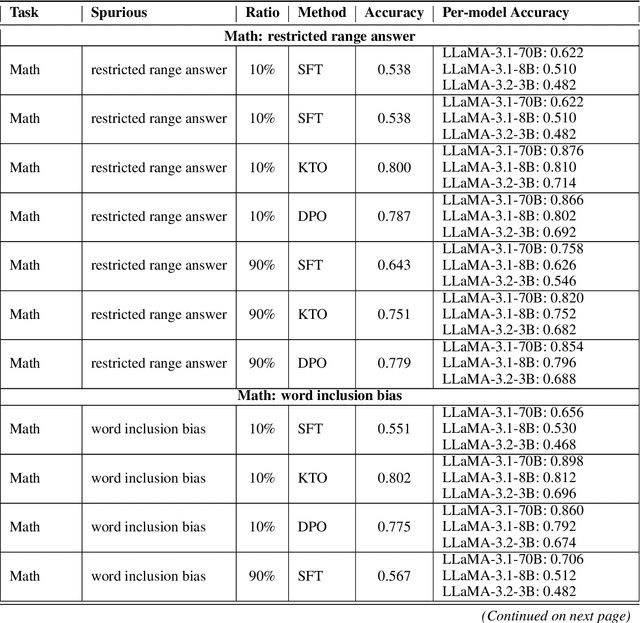
Supervised and preference-based fine-tuning techniques have become popular for aligning large language models (LLMs) with user intent and correctness criteria. However, real-world training data often exhibits spurious correlations -- arising from biases, dataset artifacts, or other "shortcut" features -- that can compromise a model's performance or generalization. In this paper, we systematically evaluate three post-training algorithms -- Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and KTO (Kahneman-Tversky Optimization) -- across a diverse set of synthetic tasks and spuriousness conditions. Our tasks span mathematical reasoning, constrained instruction-following, and document-grounded question answering. We vary the degree of spurious correlation (10% vs. 90%) and investigate two forms of artifacts: "Feature Ambiguity" and "Distributional Narrowness." Our results show that the models often but not always degrade under higher spuriousness. The preference-based methods (DPO/KTO) can demonstrate relative robustness in mathematical reasoning tasks. By contrast, SFT maintains stronger performance in complex, context-intensive tasks. These findings highlight that no single post-training strategy universally outperforms in all scenarios; the best choice depends on the type of target task and the nature of spurious correlations.
Balancing Cost and Effectiveness of Synthetic Data Generation Strategies for LLMs
Sep 29, 2024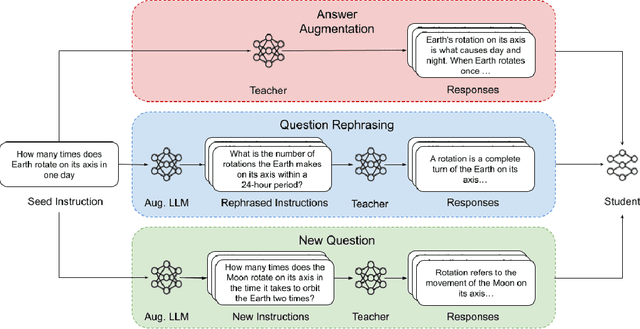

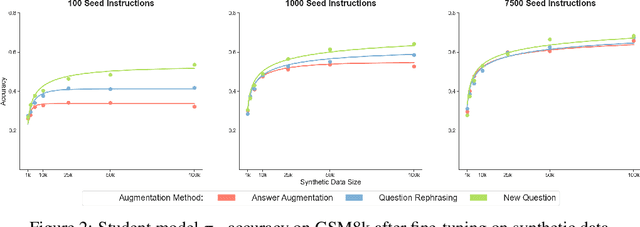
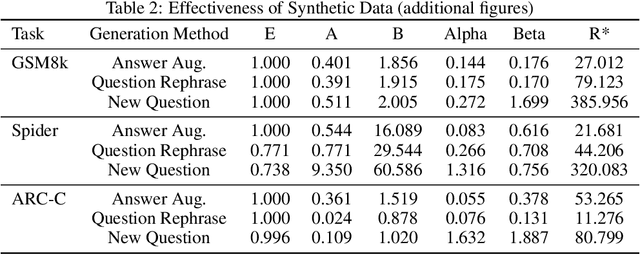
As large language models (LLMs) are applied to more use cases, creating high quality, task-specific datasets for fine-tuning becomes a bottleneck for model improvement. Using high quality human data has been the most common approach to unlock model performance, but is prohibitively expensive in many scenarios. Several alternative methods have also emerged, such as generating synthetic or hybrid data, but the effectiveness of these approaches remain unclear, especially in resource-constrained scenarios and tasks that are not easily verified. To investigate this, we group various synthetic data generation strategies into three representative categories -- Answer Augmentation, Question Rephrase and New Question -- and study the performance of student LLMs trained under various constraints, namely seed instruction set size and query budget. We demonstrate that these strategies are not equally effective across settings. Notably, the optimal data generation strategy depends strongly on the ratio between the available teacher query budget and the size of the seed instruction set. When this ratio is low, generating new answers to existing questions proves most effective, but as this ratio increases, generating new questions becomes optimal. Across all tasks, we find that choice of augmentation method and other design choices matter substantially more in low to mid data regimes than in high data regimes. We provide a practical framework for selecting the appropriate augmentation method across settings, taking into account additional factors such as the scalability of each method, the importance of verifying synthetic data, and the use of different LLMs for synthetic data generation.
"Kelly is a Warm Person, Joseph is a Role Model": Gender Biases in LLM-Generated Reference Letters
Oct 28, 2023



Large Language Models (LLMs) have recently emerged as an effective tool to assist individuals in writing various types of content, including professional documents such as recommendation letters. Though bringing convenience, this application also introduces unprecedented fairness concerns. Model-generated reference letters might be directly used by users in professional scenarios. If underlying biases exist in these model-constructed letters, using them without scrutinization could lead to direct societal harms, such as sabotaging application success rates for female applicants. In light of this pressing issue, it is imminent and necessary to comprehensively study fairness issues and associated harms in this real-world use case. In this paper, we critically examine gender biases in LLM-generated reference letters. Drawing inspiration from social science findings, we design evaluation methods to manifest biases through 2 dimensions: (1) biases in language style and (2) biases in lexical content. We further investigate the extent of bias propagation by analyzing the hallucination bias of models, a term that we define to be bias exacerbation in model-hallucinated contents. Through benchmarking evaluation on 2 popular LLMs- ChatGPT and Alpaca, we reveal significant gender biases in LLM-generated recommendation letters. Our findings not only warn against using LLMs for this application without scrutinization, but also illuminate the importance of thoroughly studying hidden biases and harms in LLM-generated professional documents.
Empirical Analysis of the Strengths and Weaknesses of PEFT Techniques for LLMs
Apr 28, 2023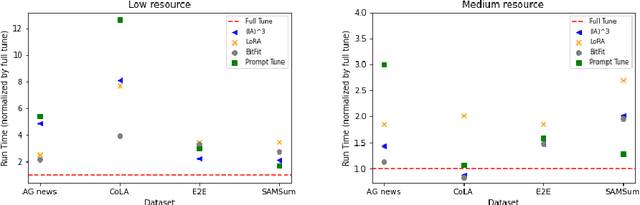
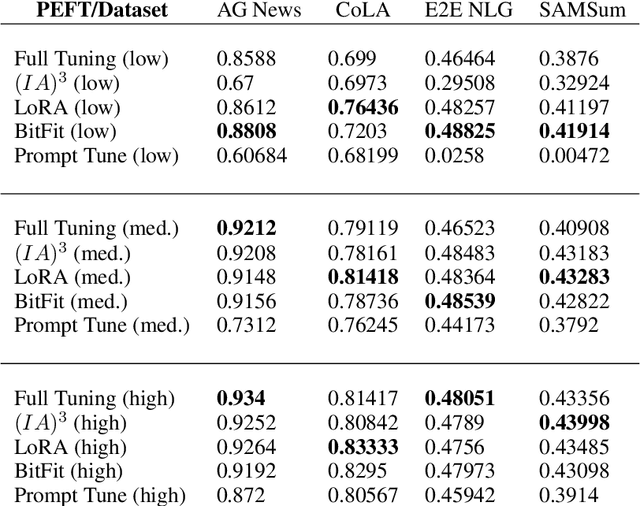
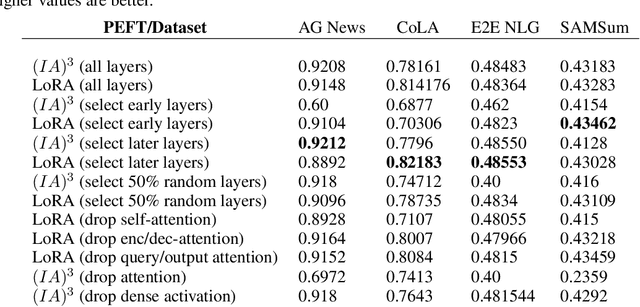
As foundation models continue to exponentially scale in size, efficient methods of adaptation become increasingly critical. Parameter-efficient fine-tuning (PEFT), a recent class of techniques that require only modifying a small percentage of the model parameters, is currently the most popular method for adapting large language models (LLMs). Several PEFT techniques have recently been proposed with varying tradeoffs. We provide a comprehensive and uniform benchmark of various PEFT techniques across a representative LLM, the FLAN-T5 model, and evaluate model performance across different data scales of classification and generation datasets. Based on this, we provide a framework for choosing the optimal fine-tuning techniques given the task type and data availability. Contrary to popular belief, we also empirically prove that PEFT techniques converge slower than full tuning in low data scenarios, and posit the amount of data required for PEFT methods to both perform well and converge efficiently. Lastly, we further optimize these PEFT techniques by selectively choosing which parts of the model to train, and find that these techniques can be applied with significantly fewer parameters while maintaining and even improving performance.
Server Averaging for Federated Learning
Mar 22, 2021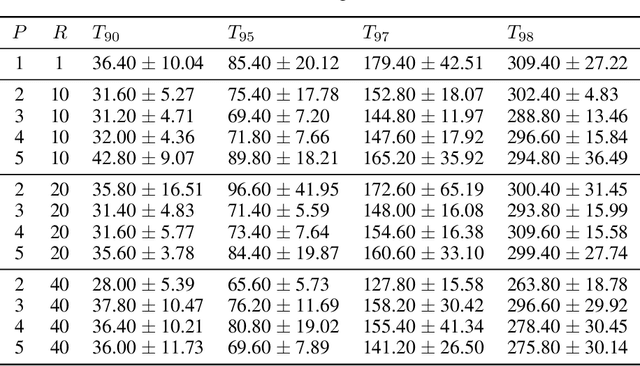
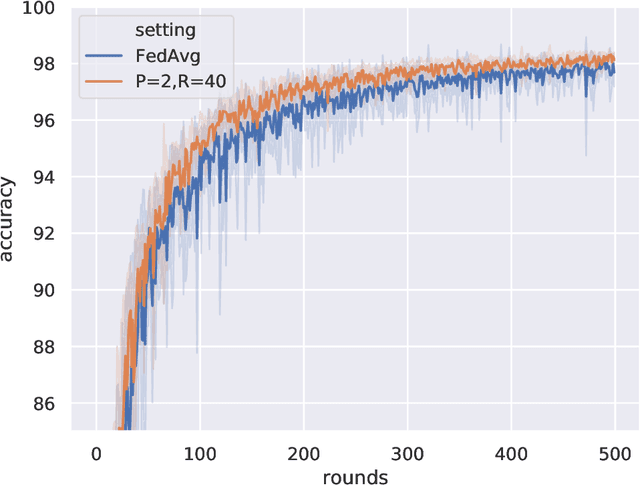
Federated learning allows distributed devices to collectively train a model without sharing or disclosing the local dataset with a central server. The global model is optimized by training and averaging the model parameters of all local participants. However, the improved privacy of federated learning also introduces challenges including higher computation and communication costs. In particular, federated learning converges slower than centralized training. We propose the server averaging algorithm to accelerate convergence. Sever averaging constructs the shared global model by periodically averaging a set of previous global models. Our experiments indicate that server averaging not only converges faster, to a target accuracy, than federated averaging (FedAvg), but also reduces the computation costs on the client-level through epoch decay.
Distilled One-Shot Federated Learning
Sep 17, 2020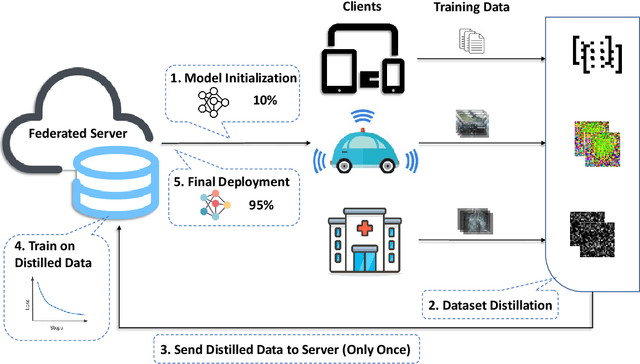
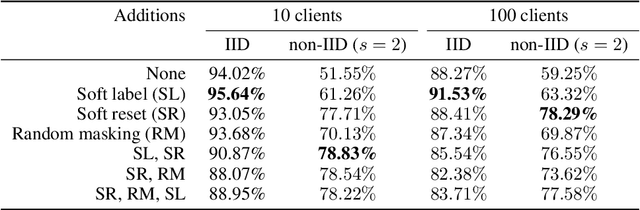
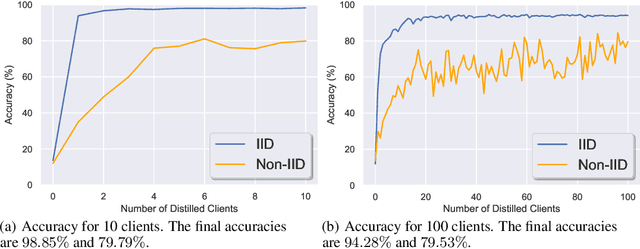
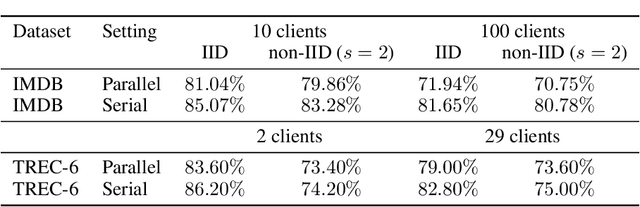
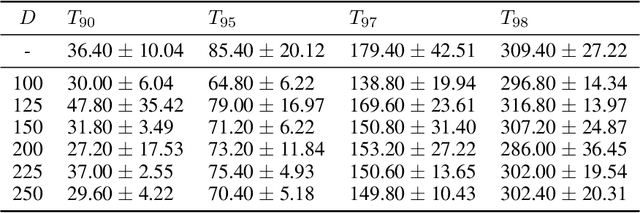
Current federated learning algorithms take tens of communication rounds transmitting unwieldy model weights under ideal circumstances and hundreds when data is poorly distributed. Inspired by recent work on dataset distillation and distributed one-shot learning, we propose Distilled One-Shot Federated Learning, which reduces the number of communication rounds required to train a performant model to only one. Each client distills their private dataset and sends the synthetic data (e.g. images or sentences) to the server. The distilled data look like noise and become useless after model fitting. We empirically show that, in only one round of communication, our method can achieve 96% test accuracy on federated MNIST with LeNet (centralized 99%), 81% on federated IMDB with a customized CNN (centralized 86%), and 84% on federated TREC-6 with a Bi-LSTM (centralized 89%). Using only a few rounds, DOSFL can match the centralized baseline on all three tasks. By evading the need for model-wise updates (i.e., weights, gradients, loss, etc.), the total communication cost of DOSFL is reduced by over an order of magnitude. We believe that DOSFL represents a new direction orthogonal to previous work, towards weight-less and gradient-less federated learning.
Adaptive Leader-Follower Formation Control and Obstacle Avoidance via Deep Reinforcement Learning
Nov 15, 2019
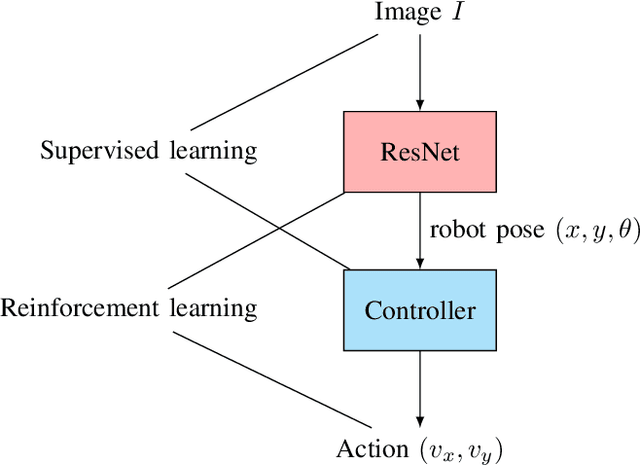
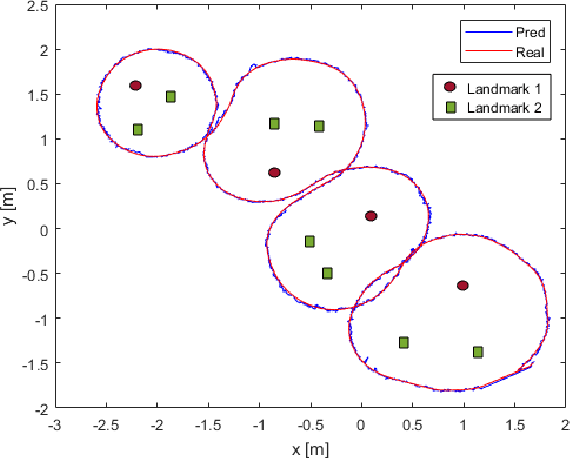
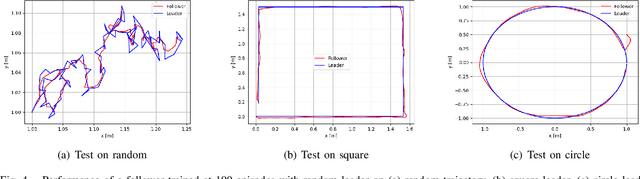
We propose a deep reinforcement learning (DRL) methodology for the tracking, obstacle avoidance, and formation control of nonholonomic robots. By separating vision-based control into a perception module and a controller module, we can train a DRL agent without sophisticated physics or 3D modeling. In addition, the modular framework averts daunting retrains of an image-to-action end-to-end neural network, and provides flexibility in transferring the controller to different robots. First, we train a convolutional neural network (CNN) to accurately localize in an indoor setting with dynamic foreground/background. Then, we design a new DRL algorithm named Momentum Policy Gradient (MPG) for continuous control tasks and prove its convergence. We also show that MPG is robust at tracking varying leader movements and can naturally be extended to problems of formation control. Leveraging reward shaping, features such as collision and obstacle avoidance can be easily integrated into a DRL controller.
* Accepted IROS 2019 paper with minor revisions