 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Careful Examination of Large Language Model Performance on Grade School Arithmetic
May 02, 2024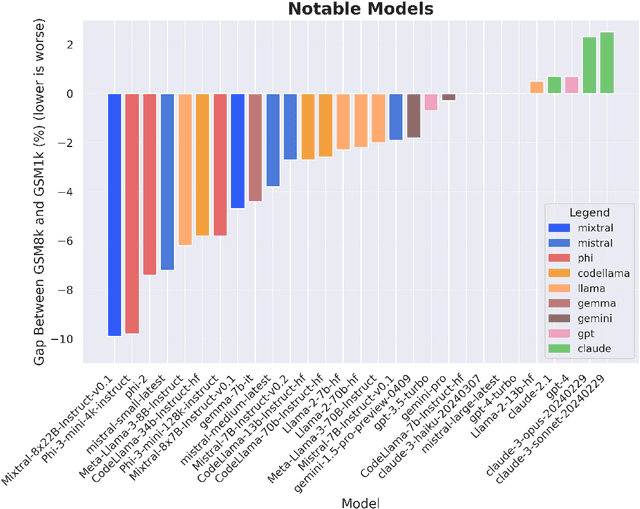

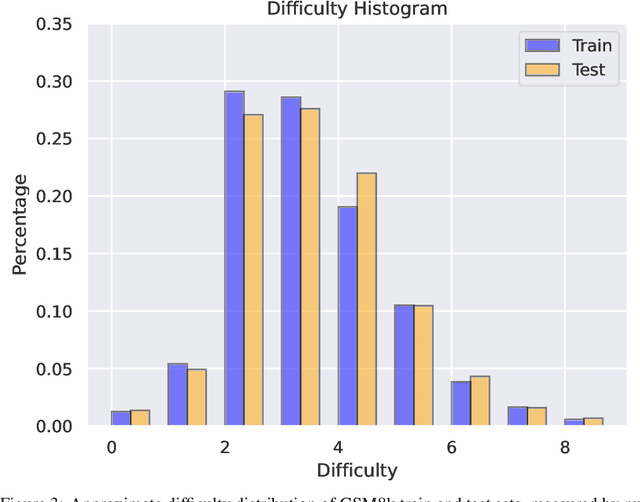
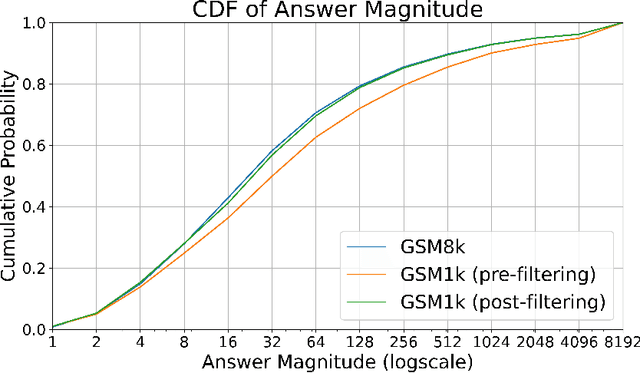
Large language models (LLMs) have achieved impressive success on many benchmarks for mathematical reasoning. However, there is growing concern that some of this performance actually reflects dataset contamination, where data closely resembling benchmark questions leaks into the training data, instead of true reasoning ability. To investigate this claim rigorously, we commission Grade School Math 1000 (GSM1k). GSM1k is designed to mirror the style and complexity of the established GSM8k benchmark, the gold standard for measuring elementary mathematical reasoning. We ensure that the two benchmarks are comparable across important metrics such as human solve rates, number of steps in solution, answer magnitude, and more. When evaluating leading open- and closed-source LLMs on GSM1k, we observe accuracy drops of up to 13%, with several families of models (e.g., Phi and Mistral) showing evidence of systematic overfitting across almost all model sizes. At the same time, many models, especially those on the frontier, (e.g., Gemini/GPT/Claude) show minimal signs of overfitting. Further analysis suggests a positive relationship (Spearman's r^2=0.32) between a model's probability of generating an example from GSM8k and its performance gap between GSM8k and GSM1k, suggesting that many models may have partially memorized GSM8k.
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Mar 06, 2024



The White House Executive Order on Artificial Intelligence highlights the risks of large language models (LLMs) empowering malicious actors in developing biological, cyber, and chemical weapons. To measure these risks of malicious use, government institutions and major AI labs are developing evaluations for hazardous capabilities in LLMs. However, current evaluations are private, preventing further research into mitigating risk. Furthermore, they focus on only a few, highly specific pathways for malicious use. To fill these gaps, we publicly release the Weapons of Mass Destruction Proxy (WMDP) benchmark, a dataset of 4,157 multiple-choice questions that serve as a proxy measurement of hazardous knowledge in biosecurity, cybersecurity, and chemical security. WMDP was developed by a consortium of academics and technical consultants, and was stringently filtered to eliminate sensitive information prior to public release. WMDP serves two roles: first, as an evaluation for hazardous knowledge in LLMs, and second, as a benchmark for unlearning methods to remove such hazardous knowledge. To guide progress on unlearning, we develop CUT, a state-of-the-art unlearning method based on controlling model representations. CUT reduces model performance on WMDP while maintaining general capabilities in areas such as biology and computer science, suggesting that unlearning may be a concrete path towards reducing malicious use from LLMs. We release our benchmark and code publicly at https://wmdp.ai
Empirical Analysis of the Strengths and Weaknesses of PEFT Techniques for LLMs
Apr 28, 2023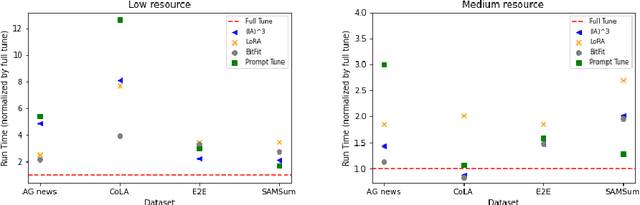
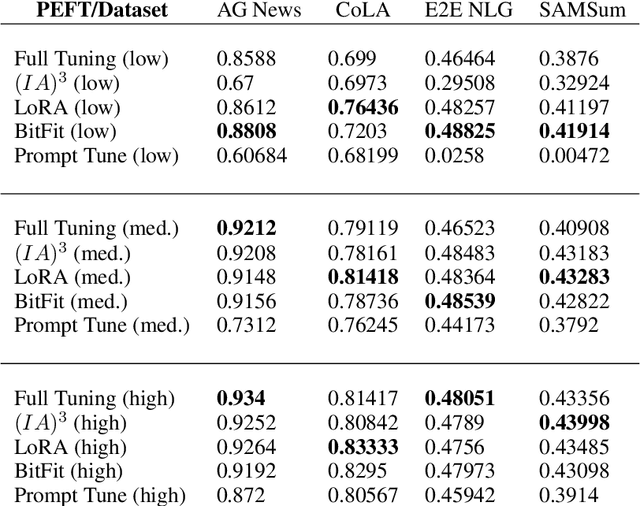
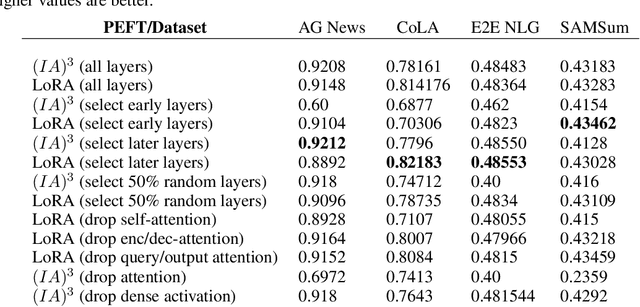
As foundation models continue to exponentially scale in size, efficient methods of adaptation become increasingly critical. Parameter-efficient fine-tuning (PEFT), a recent class of techniques that require only modifying a small percentage of the model parameters, is currently the most popular method for adapting large language models (LLMs). Several PEFT techniques have recently been proposed with varying tradeoffs. We provide a comprehensive and uniform benchmark of various PEFT techniques across a representative LLM, the FLAN-T5 model, and evaluate model performance across different data scales of classification and generation datasets. Based on this, we provide a framework for choosing the optimal fine-tuning techniques given the task type and data availability. Contrary to popular belief, we also empirically prove that PEFT techniques converge slower than full tuning in low data scenarios, and posit the amount of data required for PEFT methods to both perform well and converge efficiently. Lastly, we further optimize these PEFT techniques by selectively choosing which parts of the model to train, and find that these techniques can be applied with significantly fewer parameters while maintaining and even improving performance.
HiDDeN: Hiding Data With Deep Networks
Jul 26, 2018
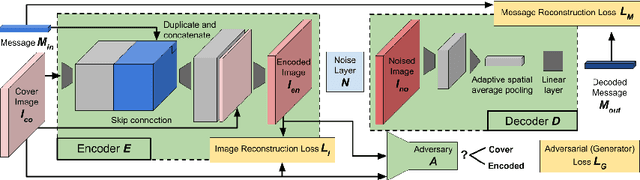

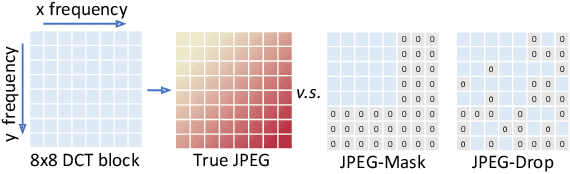
Recent work has shown that deep neural networks are highly sensitive to tiny perturbations of input images, giving rise to adversarial examples. Though this property is usually considered a weakness of learned models, we explore whether it can be beneficial. We find that neural networks can learn to use invisible perturbations to encode a rich amount of useful information. In fact, one can exploit this capability for the task of data hiding. We jointly train encoder and decoder networks, where given an input message and cover image, the encoder produces a visually indistinguishable encoded image, from which the decoder can recover the original message. We show that these encodings are competitive with existing data hiding algorithms, and further that they can be made robust to noise: our models learn to reconstruct hidden information in an encoded image despite the presence of Gaussian blurring, pixel-wise dropout, cropping, and JPEG compression. Even though JPEG is non-differentiable, we show that a robust model can be trained using differentiable approximations. Finally, we demonstrate that adversarial training improves the visual quality of encoded images.
Beating Atari with Natural Language Guided Reinforcement Learning
Apr 18, 2017

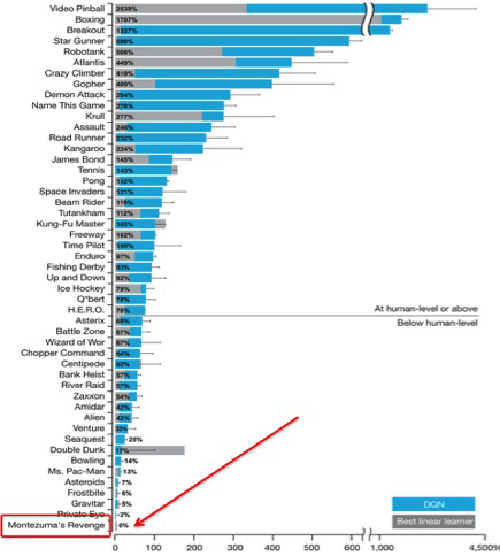

We introduce the first deep reinforcement learning agent that learns to beat Atari games with the aid of natural language instructions. The agent uses a multimodal embedding between environment observations and natural language to self-monitor progress through a list of English instructions, granting itself reward for completing instructions in addition to increasing the game score. Our agent significantly outperforms Deep Q-Networks (DQNs), Asynchronous Advantage Actor-Critic (A3C) agents, and the best agents posted to OpenAI Gym on what is often considered the hardest Atari 2600 environment: Montezuma's Revenge.