 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Network based Agent in Google Research Football
Apr 23, 2022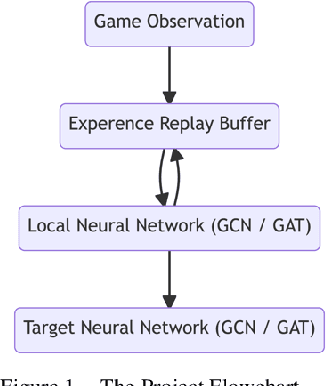
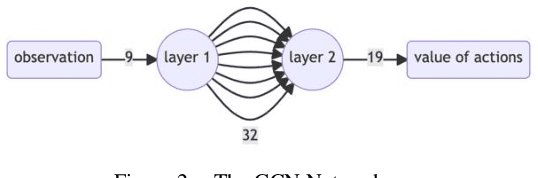

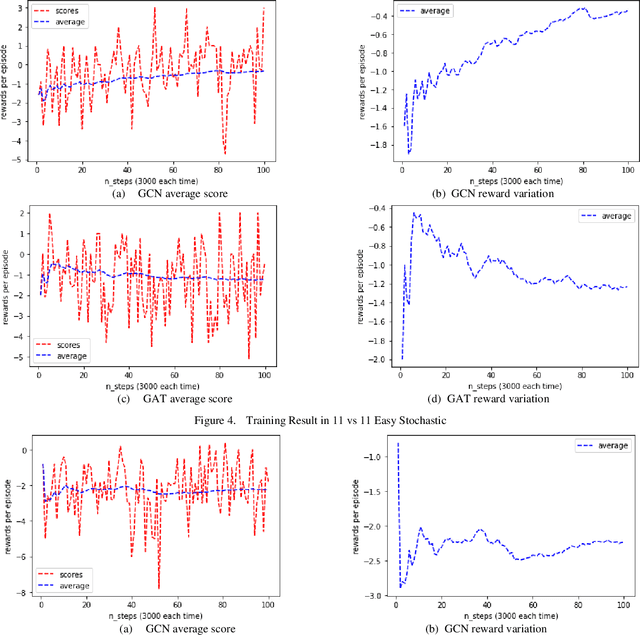
Deep neural networks (DNN) can approximate value functions or policies for reinforcement learning, which makes the reinforcement learning algorithms more powerful. However, some DNNs, such as convolutional neural networks (CNN), cannot extract enough information or take too long to obtain enough features from the inputs under specific circumstances of reinforcement learning. For example, the input data of Google Research Football, a reinforcement learning environment which trains agents to play football, is the small map of players' locations. The information is contained not only in the coordinates of players, but also in the relationships between different players. CNNs can neither extract enough information nor take too long to train. To address this issue, this paper proposes a deep q-learning network (DQN) with a graph neural network (GNN) as its model. The GNN transforms the input data into a graph which better represents the football players' locations so that it extracts more information of the interactions between different players. With two GNNs to approximate its local and target value functions, this DQN allows players to learn from their experience by using value functions to see the prospective value of each intended action. The proposed model demonstrated the power of GNN in the football game by outperforming other DRL models with significantly fewer steps.
SURREAL-System: Fully-Integrated Stack for Distributed Deep Reinforcement Learning
Oct 11, 2019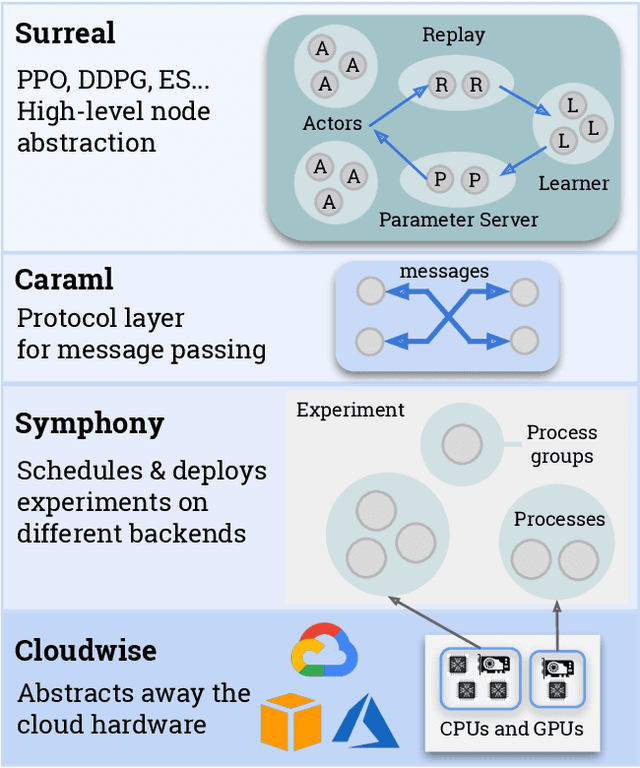

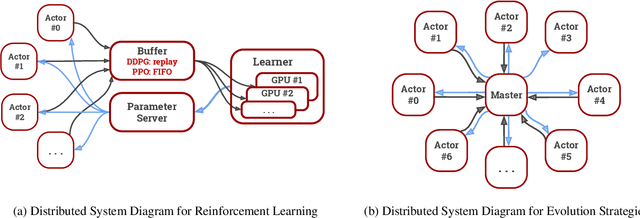
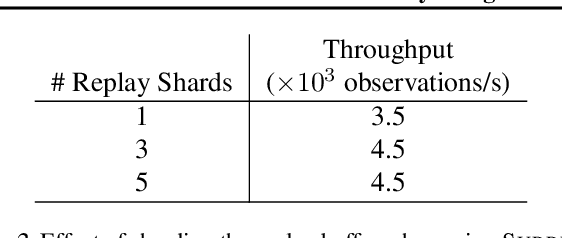
We present an overview of SURREAL-System, a reproducible, flexible, and scalable framework for distributed reinforcement learning (RL). The framework consists of a stack of four layers: Provisioner, Orchestrator, Protocol, and Algorithms. The Provisioner abstracts away the machine hardware and node pools across different cloud providers. The Orchestrator provides a unified interface for scheduling and deploying distributed algorithms by high-level description, which is capable of deploying to a wide range of hardware from a personal laptop to full-fledged cloud clusters. The Protocol provides network communication primitives optimized for RL. Finally, the SURREAL algorithms, such as Proximal Policy Optimization (PPO) and Evolution Strategies (ES), can easily scale to 1000s of CPU cores and 100s of GPUs. The learning performances of our distributed algorithms establish new state-of-the-art on OpenAI Gym and Robotics Suites tasks.
HiDDeN: Hiding Data With Deep Networks
Jul 26, 2018
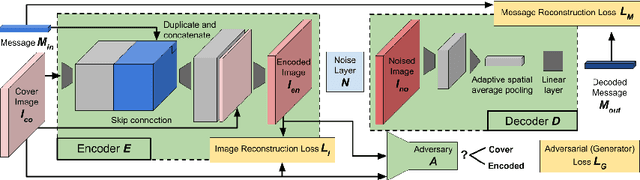

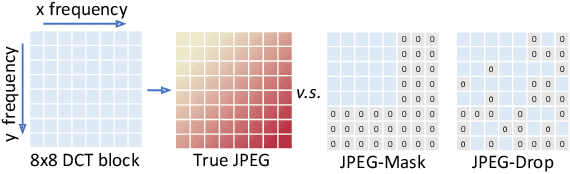
Recent work has shown that deep neural networks are highly sensitive to tiny perturbations of input images, giving rise to adversarial examples. Though this property is usually considered a weakness of learned models, we explore whether it can be beneficial. We find that neural networks can learn to use invisible perturbations to encode a rich amount of useful information. In fact, one can exploit this capability for the task of data hiding. We jointly train encoder and decoder networks, where given an input message and cover image, the encoder produces a visually indistinguishable encoded image, from which the decoder can recover the original message. We show that these encodings are competitive with existing data hiding algorithms, and further that they can be made robust to noise: our models learn to reconstruct hidden information in an encoded image despite the presence of Gaussian blurring, pixel-wise dropout, cropping, and JPEG compression. Even though JPEG is non-differentiable, we show that a robust model can be trained using differentiable approximations. Finally, we demonstrate that adversarial training improves the visual quality of encoded images.