 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Analysis of the Strengths and Weaknesses of PEFT Techniques for LLMs
Apr 28, 2023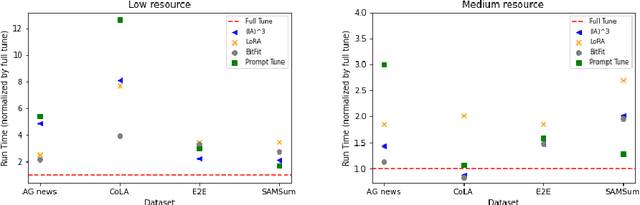
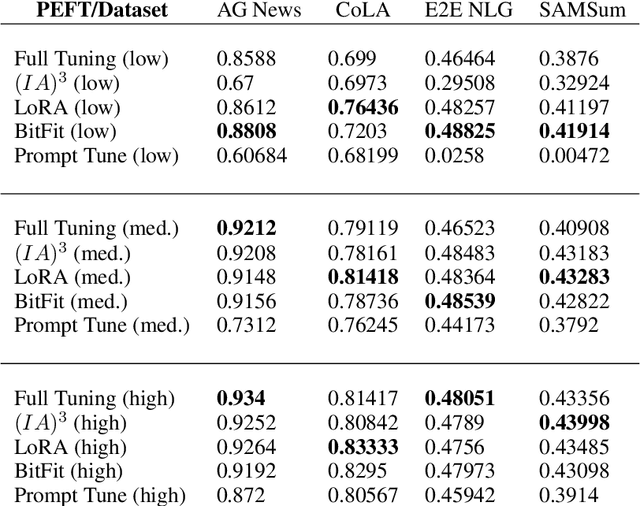
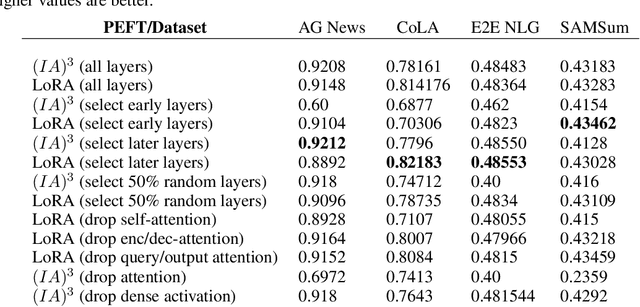
As foundation models continue to exponentially scale in size, efficient methods of adaptation become increasingly critical. Parameter-efficient fine-tuning (PEFT), a recent class of techniques that require only modifying a small percentage of the model parameters, is currently the most popular method for adapting large language models (LLMs). Several PEFT techniques have recently been proposed with varying tradeoffs. We provide a comprehensive and uniform benchmark of various PEFT techniques across a representative LLM, the FLAN-T5 model, and evaluate model performance across different data scales of classification and generation datasets. Based on this, we provide a framework for choosing the optimal fine-tuning techniques given the task type and data availability. Contrary to popular belief, we also empirically prove that PEFT techniques converge slower than full tuning in low data scenarios, and posit the amount of data required for PEFT methods to both perform well and converge efficiently. Lastly, we further optimize these PEFT techniques by selectively choosing which parts of the model to train, and find that these techniques can be applied with significantly fewer parameters while maintaining and even improving performance.
Confounding Tradeoffs for Neural Network Quantization
Feb 12, 2021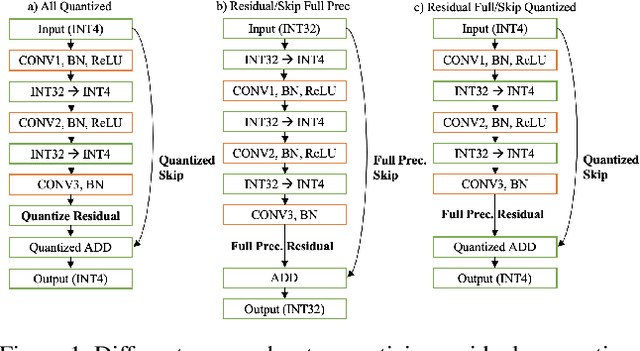

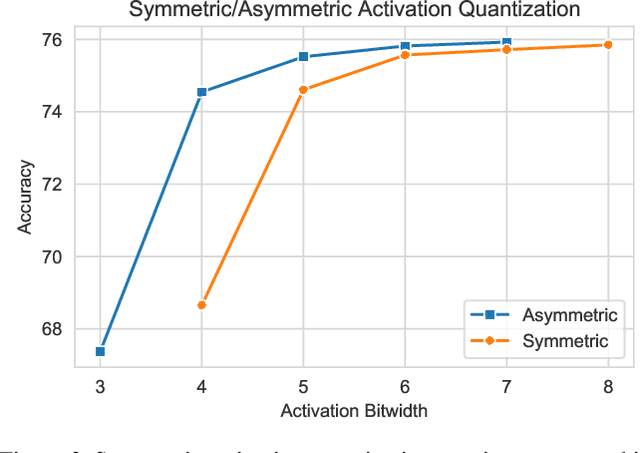
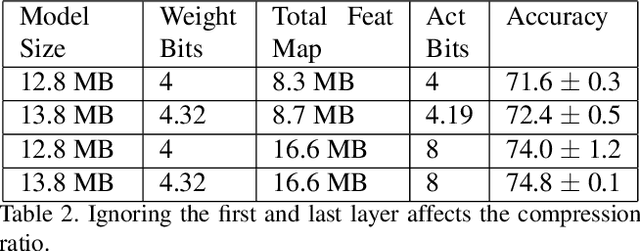
Many neural network quantization techniques have been developed to decrease the computational and memory footprint of deep learning. However, these methods are evaluated subject to confounding tradeoffs that may affect inference acceleration or resource complexity in exchange for higher accuracy. In this work, we articulate a variety of tradeoffs whose impact is often overlooked and empirically analyze their impact on uniform and mixed-precision post-training quantization, finding that these confounding tradeoffs may have a larger impact on quantized network accuracy than the actual quantization methods themselves. Because these tradeoffs constrain the attainable hardware acceleration for different use-cases, we encourage researchers to explicitly report these design choices through the structure of "quantization cards." We expect quantization cards to help researchers compare methods more effectively and engineers determine the applicability of quantization techniques for their hardware.
Dynamic Precision Analog Computing for Neural Networks
Feb 12, 2021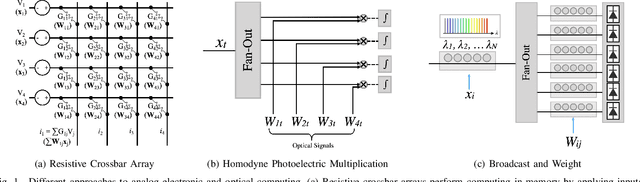

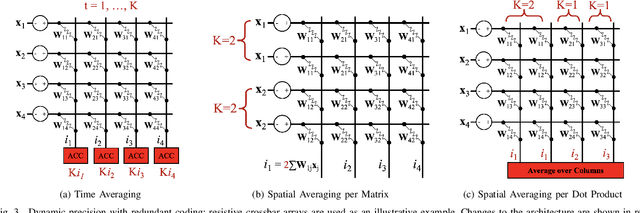
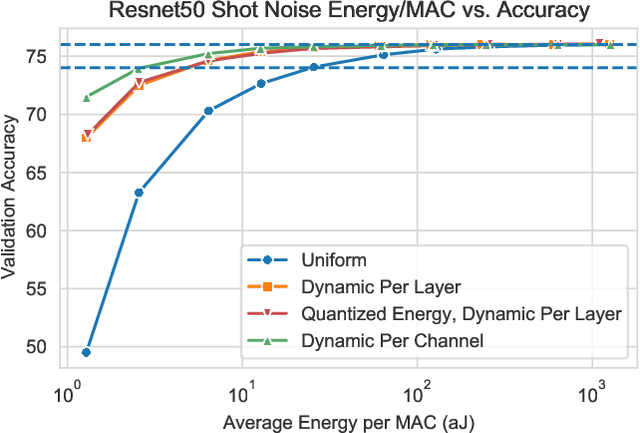
Analog electronic and optical computing exhibit tremendous advantages over digital computing for accelerating deep learning when operations are executed at low precision. In this work, we derive a relationship between analog precision, which is limited by noise, and digital bit precision. We propose extending analog computing architectures to support varying levels of precision by repeating operations and averaging the result, decreasing the impact of noise. Such architectures enable programmable tradeoffs between precision and other desirable performance metrics such as energy efficiency or throughput. To utilize dynamic precision, we propose a method for learning the precision of each layer of a pre-trained model without retraining network weights. We evaluate this method on analog architectures subject to a variety of noise sources such as shot noise, thermal noise, and weight noise and find that employing dynamic precision reduces energy consumption by up to 89% for computer vision models such as Resnet50 and by 24% for natural language processing models such as BERT. In one example, we apply dynamic precision to a shot-noise limited homodyne optical neural network and simulate inference at an optical energy consumption of 2.7 aJ/MAC for Resnet50 and 1.6 aJ/MAC for BERT with <2% accuracy degradation.
Cloud Removal in Satellite Images Using Spatiotemporal Generative Networks
Dec 14, 2019
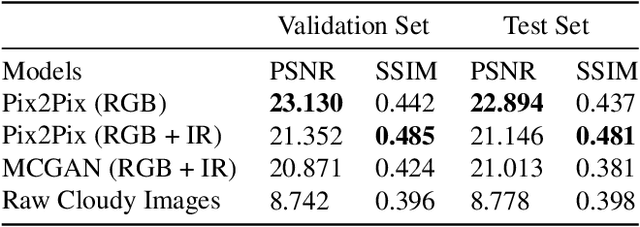
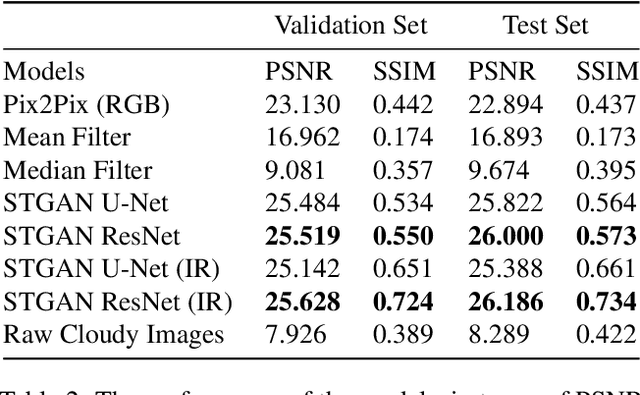
Satellite images hold great promise for continuous environmental monitoring and earth observation. Occlusions cast by clouds, however, can severely limit coverage, making ground information extraction more difficult. Existing pipelines typically perform cloud removal with simple temporal composites and hand-crafted filters. In contrast, we cast the problem of cloud removal as a conditional image synthesis challenge, and we propose a trainable spatiotemporal generator network (STGAN) to remove clouds. We train our model on a new large-scale spatiotemporal dataset that we construct, containing 97640 image pairs covering all continents. We demonstrate experimentally that the proposed STGAN model outperforms standard models and can generate realistic cloud-free images with high PSNR and SSIM values across a variety of atmospheric conditions, leading to improved performance in downstream tasks such as land cover classification.
VizSeq: A Visual Analysis Toolkit for Text Generation Tasks
Sep 12, 2019

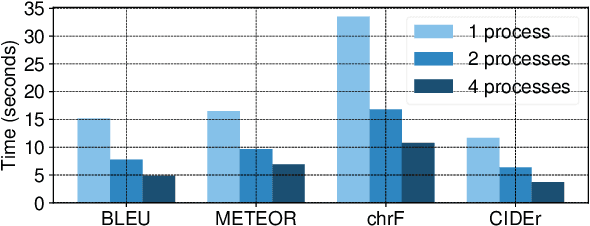

Automatic evaluation of text generation tasks (e.g. machine translation, text summarization, image captioning and video description) usually relies heavily on task-specific metrics, such as BLEU and ROUGE. They, however, are abstract numbers and are not perfectly aligned with human assessment. This suggests inspecting detailed examples as a complement to identify system error patterns. In this paper, we present VizSeq, a visual analysis toolkit for instance-level and corpus-level system evaluation on a wide variety of text generation tasks. It supports multimodal sources and multiple text references, providing visualization in Jupyter notebook or a web app interface. It can be used locally or deployed onto public servers for centralized data hosting and benchmarking. It covers most common n-gram based metrics accelerated with multiprocessing, and also provides latest embedding-based metrics such as BERTScore.
Practical Deep Learning with Bayesian Principles
Jun 06, 2019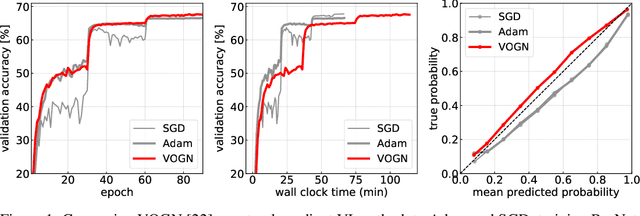


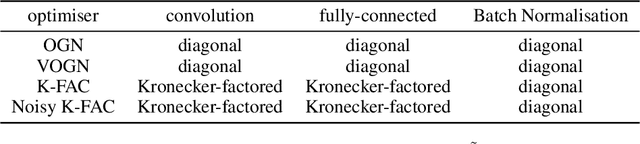
Bayesian methods promise to fix many shortcomings of deep learning, but they are impractical and rarely match the performance of standard methods, let alone improve them. In this paper, we demonstrate practical training of deep networks with natural-gradient variational inference. By applying techniques such as batch normalisation, data augmentation, and distributed training, we achieve similar performance in about the same number of epochs as the Adam optimiser, even on large datasets such as ImageNet. Importantly, the benefits of Bayesian principles are preserved: predictive probabilities are well-calibrated and uncertainties on out-of-distribution data are improved. This work enables practical deep learning while preserving benefits of Bayesian principles. A PyTorch implementation will be available as a plug-and-play optimiser.