 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfounding Tradeoffs for Neural Network Quantization
Paper and Code
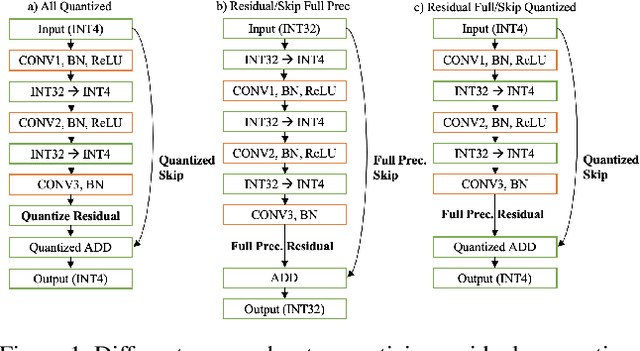

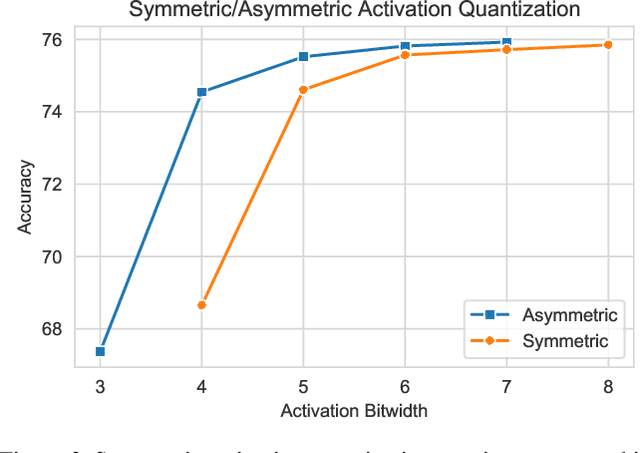
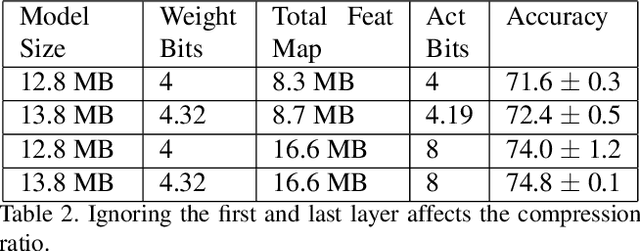
Many neural network quantization techniques have been developed to decrease the computational and memory footprint of deep learning. However, these methods are evaluated subject to confounding tradeoffs that may affect inference acceleration or resource complexity in exchange for higher accuracy. In this work, we articulate a variety of tradeoffs whose impact is often overlooked and empirically analyze their impact on uniform and mixed-precision post-training quantization, finding that these confounding tradeoffs may have a larger impact on quantized network accuracy than the actual quantization methods themselves. Because these tradeoffs constrain the attainable hardware acceleration for different use-cases, we encourage researchers to explicitly report these design choices through the structure of "quantization cards." We expect quantization cards to help researchers compare methods more effectively and engineers determine the applicability of quantization techniques for their hardware.