 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSzloca: towards a framework for full 3D tracking through a single camera in context of interactive arts
Jun 26, 2022
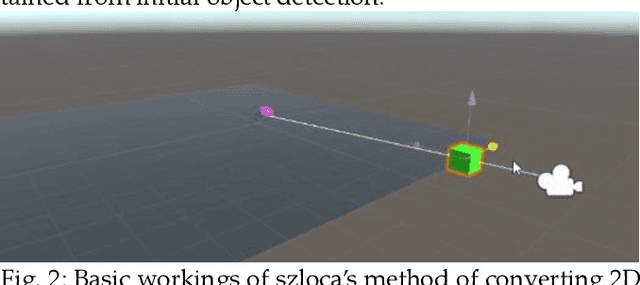

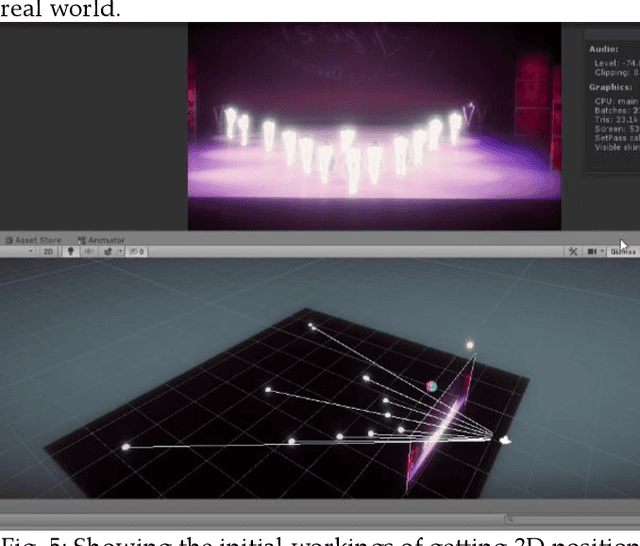
Realtime virtual data of objects and human presence in a large area holds a valuable key in enabling many experiences and applications in various industries and with exponential rise in the technological development of artificial intelligence, computer vision has expanded the possibilities of tracking and classifying things through just video inputs, which is also surpassing the limitations of most popular and common hardware setups known traditionally to detect human pose and position, such as low field of view and limited tracking capacity. The benefits of using computer vision in application development is large as it augments traditional input sources (like video streams) and can be integrated in many environments and platforms. In the context of new media interactive arts, based on physical movements and expanding over large areas or gallaries, this research presents a novel way and a framework towards obtaining data and virtual representation of objects/people - such as three-dimensional positions, skeltons/pose and masks from a single rgb camera. Looking at the state of art through some recent developments and building on prior research in the field of computer vision, the paper also proposes an original method to obtain three dimensional position data from monocular images, the model does not rely on complex training of computer vision systems but combines prior computer vision research and adds a capacity to represent z depth, ieto represent a world position in 3 axis from a 2d input source.
Anytime Sampling for Autoregressive Models via Ordered Autoencoding
Feb 23, 2021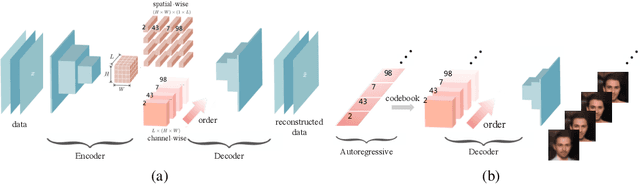

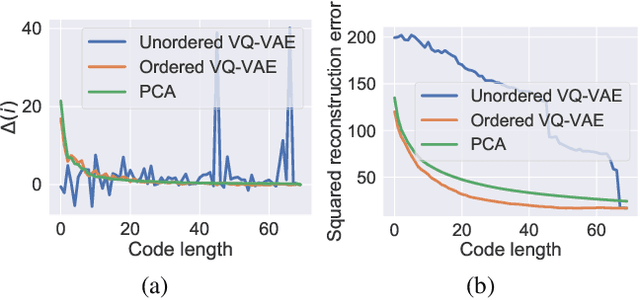
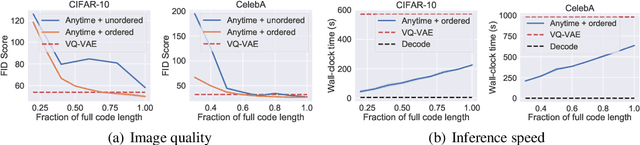
Autoregressive models are widely used for tasks such as image and audio generation. The sampling process of these models, however, does not allow interruptions and cannot adapt to real-time computational resources. This challenge impedes the deployment of powerful autoregressive models, which involve a slow sampling process that is sequential in nature and typically scales linearly with respect to the data dimension. To address this difficulty, we propose a new family of autoregressive models that enables anytime sampling. Inspired by Principal Component Analysis, we learn a structured representation space where dimensions are ordered based on their importance with respect to reconstruction. Using an autoregressive model in this latent space, we trade off sample quality for computational efficiency by truncating the generation process before decoding into the original data space. Experimentally, we demonstrate in several image and audio generation tasks that sample quality degrades gracefully as we reduce the computational budget for sampling. The approach suffers almost no loss in sample quality (measured by FID) using only 60\% to 80\% of all latent dimensions for image data. Code is available at https://github.com/Newbeeer/Anytime-Auto-Regressive-Model .
Confounding Tradeoffs for Neural Network Quantization
Feb 12, 2021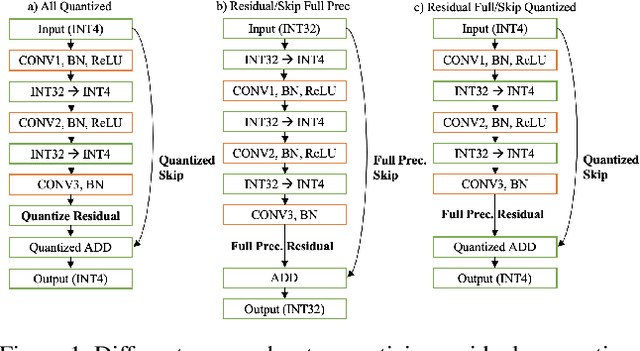

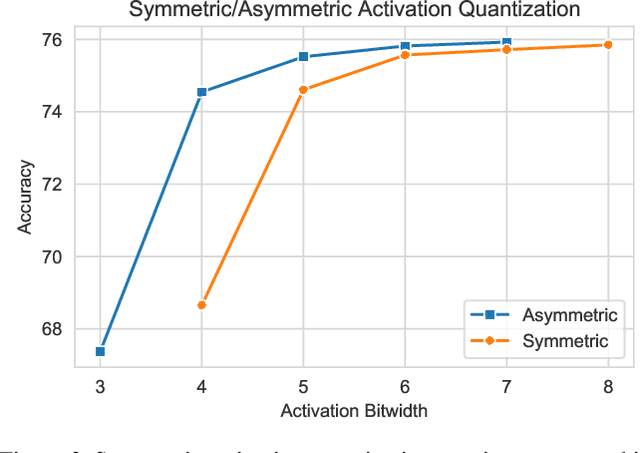
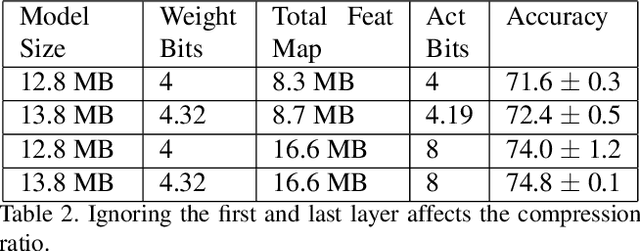
Many neural network quantization techniques have been developed to decrease the computational and memory footprint of deep learning. However, these methods are evaluated subject to confounding tradeoffs that may affect inference acceleration or resource complexity in exchange for higher accuracy. In this work, we articulate a variety of tradeoffs whose impact is often overlooked and empirically analyze their impact on uniform and mixed-precision post-training quantization, finding that these confounding tradeoffs may have a larger impact on quantized network accuracy than the actual quantization methods themselves. Because these tradeoffs constrain the attainable hardware acceleration for different use-cases, we encourage researchers to explicitly report these design choices through the structure of "quantization cards." We expect quantization cards to help researchers compare methods more effectively and engineers determine the applicability of quantization techniques for their hardware.
Dynamic Precision Analog Computing for Neural Networks
Feb 12, 2021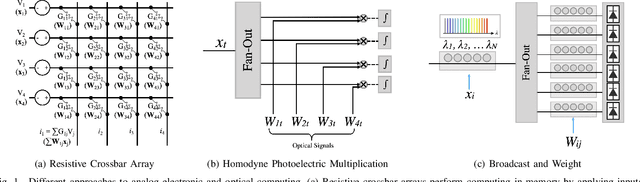

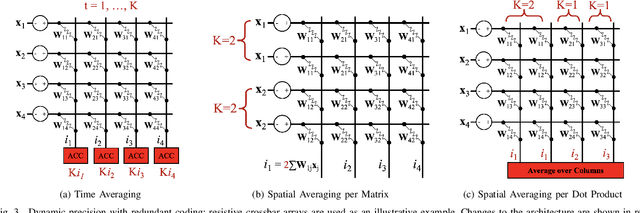
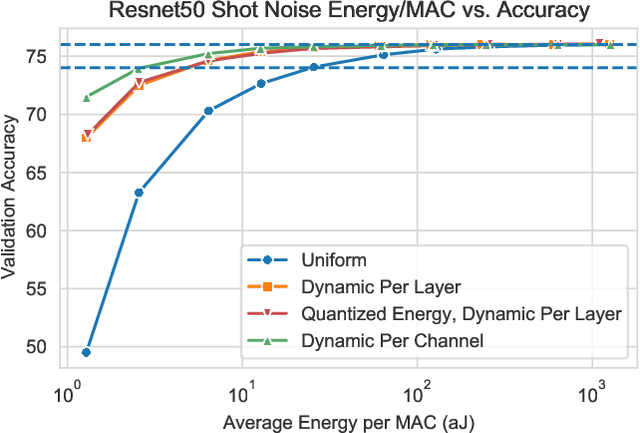
Analog electronic and optical computing exhibit tremendous advantages over digital computing for accelerating deep learning when operations are executed at low precision. In this work, we derive a relationship between analog precision, which is limited by noise, and digital bit precision. We propose extending analog computing architectures to support varying levels of precision by repeating operations and averaging the result, decreasing the impact of noise. Such architectures enable programmable tradeoffs between precision and other desirable performance metrics such as energy efficiency or throughput. To utilize dynamic precision, we propose a method for learning the precision of each layer of a pre-trained model without retraining network weights. We evaluate this method on analog architectures subject to a variety of noise sources such as shot noise, thermal noise, and weight noise and find that employing dynamic precision reduces energy consumption by up to 89% for computer vision models such as Resnet50 and by 24% for natural language processing models such as BERT. In one example, we apply dynamic precision to a shot-noise limited homodyne optical neural network and simulate inference at an optical energy consumption of 2.7 aJ/MAC for Resnet50 and 1.6 aJ/MAC for BERT with <2% accuracy degradation.
Sliced Score Matching: A Scalable Approach to Density and Score Estimation
May 17, 2019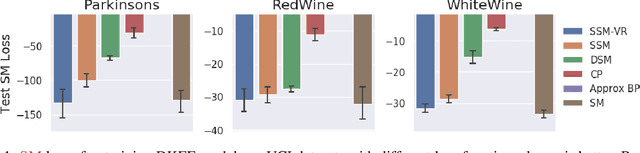


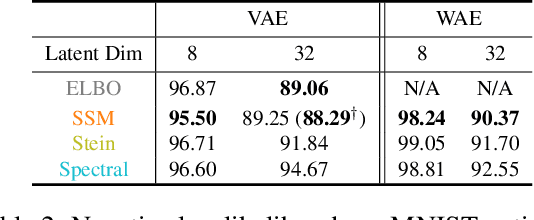
Score matching is a popular method for estimating unnormalized statistical models. However, it has been so far limited to simple models or low-dimensional data, due to the difficulty of computing the trace of Hessians for log-density functions. We show this difficulty can be mitigated by sliced score matching, a new objective that matches random projections of the original scores. Our objective only involves Hessian-vector products, which can be easily implemented using reverse-mode auto-differentiation. This enables scalable score matching for complex models and higher dimensional data. Theoretically, we prove the consistency and asymptotic normality of sliced score matching. Moreover, we demonstrate that sliced score matching can be used to learn deep score estimators for implicit distributions. In our experiments, we show that sliced score matching greatly outperforms competitors on learning deep energy-based models, and can produce accurate score estimates for applications such as variational inference with implicit distributions and training Wasserstein Auto-Encoders.
Counterfactual Fairness in Text Classification through Robustness
Sep 27, 2018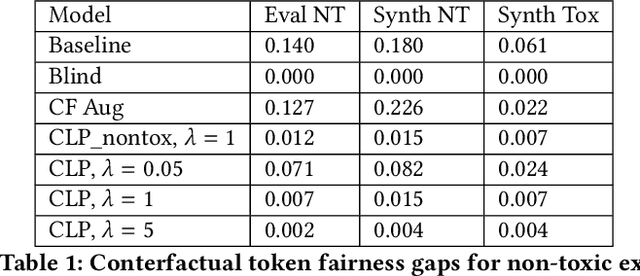
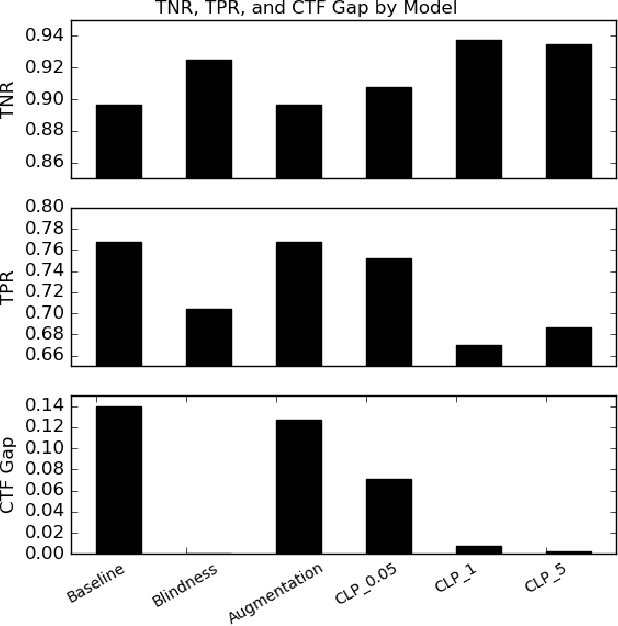
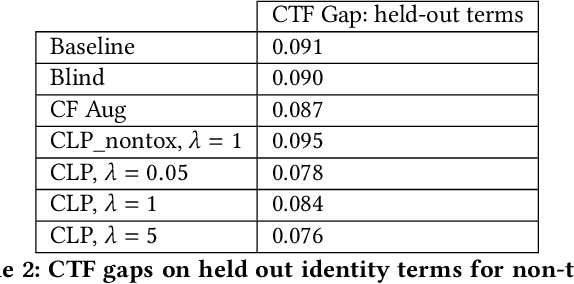
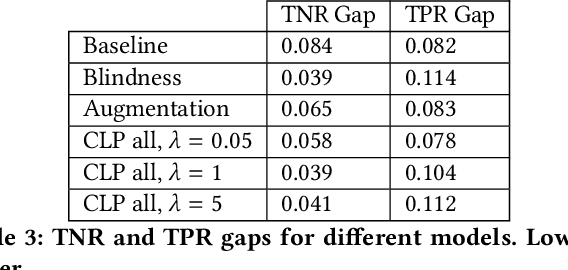
In this paper, we study counterfactual fairness in text classification, which asks the question: How would the prediction change if the sensitive attribute discussed in the example were something else? We offer a heuristic for measuring this particular form of fairness in text classifiers by substituting individual tokens pertaining to attributes (e.g. sexual orientation, race, and religion), and describe the relationship with other notions, including individual and group fairness. Further, we offer methods, including hard ablation, blindness, and counterfactual logit pairing, for optimizing this counterfactual fairness metric during model training, bridging the robustness literature and the fairness literature. Empirically, counterfactual logit pairing performs as well as hard ablation and blindness to sensitive tokens, but generalizes better to unseen tokens. Interestingly, we find that in practice, the methods do not significantly harm classifier performance, and have varying tradeoffs with group fairness. These approaches, both for measurement and optimization, provide a new path forward for addressing counterfactual fairness issues.