 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Dazzle: Using Optimized Generative Adversarial Networks to Address Security Data Class Imbalance Issue
Mar 22, 2022

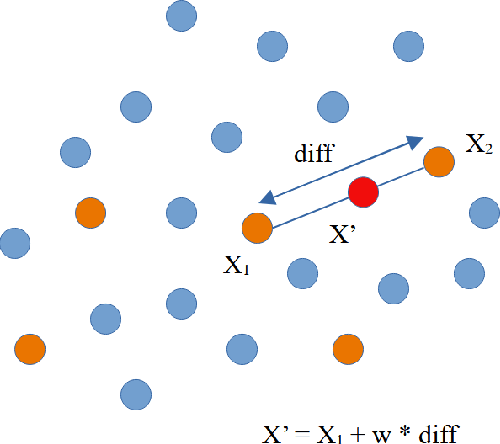
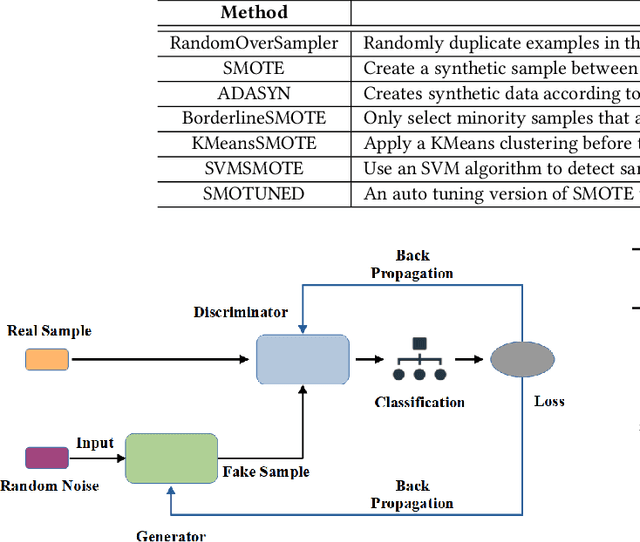
Background: Machine learning techniques have been widely used and demonstrate promising performance in many software security tasks such as software vulnerability prediction. However, the class ratio within software vulnerability datasets is often highly imbalanced (since the percentage of observed vulnerability is usually very low). Goal: To help security practitioners address software security data class imbalanced issues and further help build better prediction models with resampled datasets. Method: We introduce an approach called Dazzle which is an optimized version of conditional Wasserstein Generative Adversarial Networks with gradient penalty (cWGAN-GP). Dazzle explores the architecture hyperparameters of cWGAN-GP with a novel optimizer called Bayesian Optimization. We use Dazzle to generate minority class samples to resample the original imbalanced training dataset. Results: We evaluate Dazzle with three software security datasets, i.e., Moodle vulnerable files, Ambari bug reports, and JavaScript function code. We show that Dazzle is practical to use and demonstrates promising improvement over existing state-of-the-art oversampling techniques such as SMOTE (e.g., with an average of about 60% improvement rate over SMOTE in recall among all datasets). Conclusion: Based on this study, we would suggest the use of optimized GANs as an alternative method for security vulnerability data class imbalanced issues.
Temporal Predictive Coding For Model-Based Planning In Latent Space
Jun 14, 2021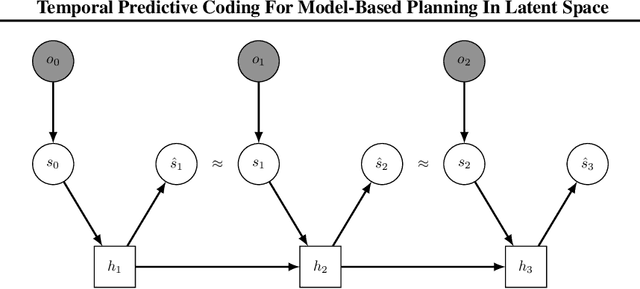
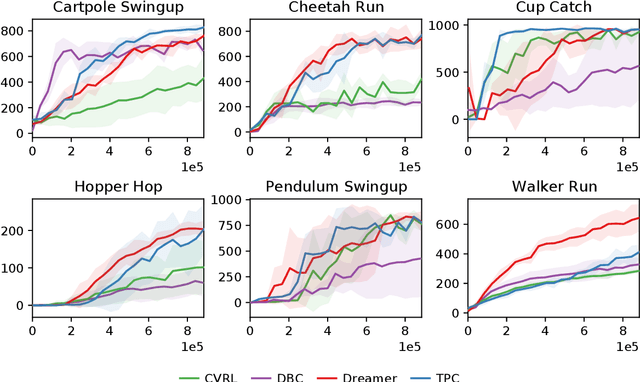
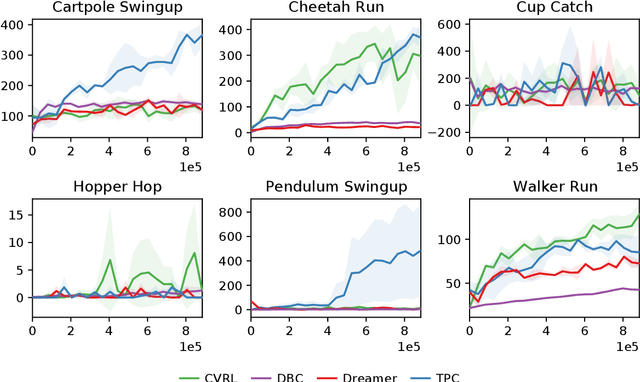
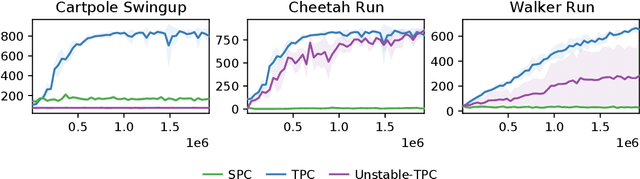
High-dimensional observations are a major challenge in the application of model-based reinforcement learning (MBRL) to real-world environments. To handle high-dimensional sensory inputs, existing approaches use representation learning to map high-dimensional observations into a lower-dimensional latent space that is more amenable to dynamics estimation and planning. In this work, we present an information-theoretic approach that employs temporal predictive coding to encode elements in the environment that can be predicted across time. Since this approach focuses on encoding temporally-predictable information, we implicitly prioritize the encoding of task-relevant components over nuisance information within the environment that are provably task-irrelevant. By learning this representation in conjunction with a recurrent state space model, we can then perform planning in latent space. We evaluate our model on a challenging modification of standard DMControl tasks where the background is replaced with natural videos that contain complex but irrelevant information to the planning task. Our experiments show that our model is superior to existing methods in the challenging complex-background setting while remaining competitive with current state-of-the-art models in the standard setting.
Anytime Sampling for Autoregressive Models via Ordered Autoencoding
Feb 23, 2021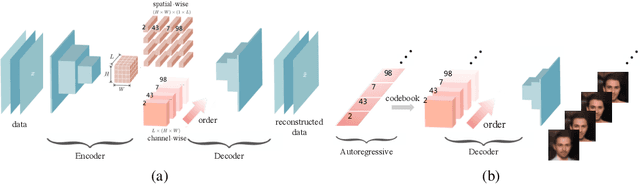

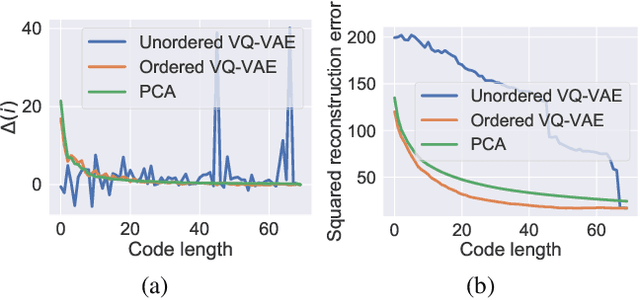
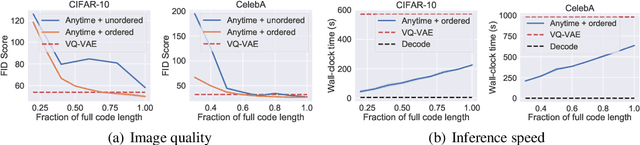
Autoregressive models are widely used for tasks such as image and audio generation. The sampling process of these models, however, does not allow interruptions and cannot adapt to real-time computational resources. This challenge impedes the deployment of powerful autoregressive models, which involve a slow sampling process that is sequential in nature and typically scales linearly with respect to the data dimension. To address this difficulty, we propose a new family of autoregressive models that enables anytime sampling. Inspired by Principal Component Analysis, we learn a structured representation space where dimensions are ordered based on their importance with respect to reconstruction. Using an autoregressive model in this latent space, we trade off sample quality for computational efficiency by truncating the generation process before decoding into the original data space. Experimentally, we demonstrate in several image and audio generation tasks that sample quality degrades gracefully as we reduce the computational budget for sampling. The approach suffers almost no loss in sample quality (measured by FID) using only 60\% to 80\% of all latent dimensions for image data. Code is available at https://github.com/Newbeeer/Anytime-Auto-Regressive-Model .
Omni: Automated Ensemble with Unexpected Models against Adversarial Evasion Attack
Nov 23, 2020

BACKGROUND: Machine learning-based security detection models have become prevalent in modern malware and intrusion detection systems. However, previous studies show that such models are susceptible to adversarial evasion attacks. In this type of attack, inputs (i.e., adversarial examples) are specially crafted by intelligent malicious adversaries, with the aim of being misclassified by existing state-of-the-art models (e.g., deep neural networks). Once the attackers can fool a classifier to think that a malicious input is actually benign, they can render a machine learning-based malware or intrusion detection system ineffective. GOAL: To help security practitioners and researchers build a more robust model against adversarial evasion attack through the use of ensemble learning. METHOD: We propose an approach called OMNI, the main idea of which is to explore methods that create an ensemble of "unexpected models"; i.e., models whose control hyperparameters have a large distance to the hyperparameters of an adversary's target model, with which we then make an optimized weighted ensemble prediction. RESULTS: In studies with five adversarial evasion attacks (FGSM, BIM, JSMA, DeepFool and Carlini-Wagner) on five security datasets (NSL-KDD, CIC-IDS-2017, CSE-CIC-IDS2018, CICAndMal2017 and the Contagio PDF dataset), we show that the improvement rate of OMNI's prediction accuracy over attack accuracy is about 53% (median value) across all datasets, with about 18% (median value) loss rate when comparing pre-attack accuracy and OMNI's prediction accuracy. CONCLUSIONWhen using ensemble learning as a defense method against adversarial evasion attacks, we suggest to create ensemble with unexpected models who are distant from the attacker's expected model (i.e., target model) through methods such as hyperparameter optimization.
Predictive Coding for Locally-Linear Control
Mar 02, 2020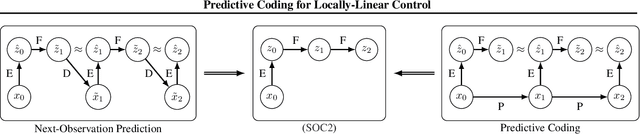


High-dimensional observations and unknown dynamics are major challenges when applying optimal control to many real-world decision making tasks. The Learning Controllable Embedding (LCE) framework addresses these challenges by embedding the observations into a lower dimensional latent space, estimating the latent dynamics, and then performing control directly in the latent space. To ensure the learned latent dynamics are predictive of next-observations, all existing LCE approaches decode back into the observation space and explicitly perform next-observation prediction---a challenging high-dimensional task that furthermore introduces a large number of nuisance parameters (i.e., the decoder) which are discarded during control. In this paper, we propose a novel information-theoretic LCE approach and show theoretically that explicit next-observation prediction can be replaced with predictive coding. We then use predictive coding to develop a decoder-free LCE model whose latent dynamics are amenable to locally-linear control. Extensive experiments on benchmark tasks show that our model reliably learns a controllable latent space that leads to superior performance when compared with state-of-the-art LCE baselines.
Fair Generative Modeling via Weak Supervision
Oct 26, 2019
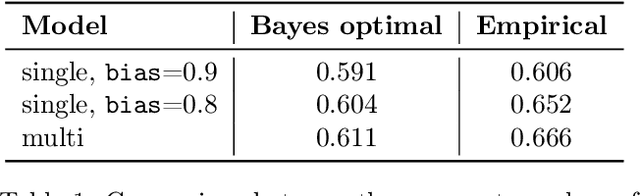

Real-world datasets are often biased with respect to key demographic factors such as race and gender. Due to the latent nature of the underlying factors, detecting and mitigating bias is especially challenging for unsupervised machine learning. We present a weakly supervised algorithm for overcoming dataset bias for deep generative models. Our approach requires access to an additional small, unlabeled but unbiased dataset as the supervision signal, thus sidestepping the need for explicit labels on the underlying bias factors. Using this supplementary dataset, we detect the bias in existing datasets via a density ratio technique and learn generative models which efficiently achieve the twin goals of: 1) data efficiency by using training examples from both biased and unbiased datasets for learning, 2) unbiased data generation at test time. Empirically, we demonstrate the efficacy of our approach which reduces bias w.r.t. latent factors by 57.1% on average over baselines for comparable image generation using generative adversarial networks.
Weakly Supervised Disentanglement with Guarantees
Oct 22, 2019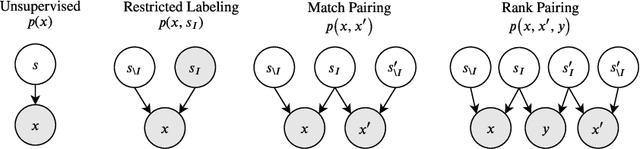

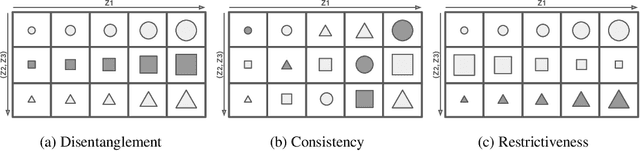

Learning disentangled representations that correspond to factors of variation in real-world data is critical to interpretable and human-controllable machine learning. Recently, concerns about the viability of learning disentangled representations in a purely unsupervised manner has spurred a shift toward the incorporation of weak supervision. However, there is currently no formalism that identifies when and how weak supervision will guarantee disentanglement. To address this issue, we provide a theoretical framework to assist in analyzing the disentanglement guarantees (or lack thereof) conferred by weak supervision when coupled with learning algorithms based on distribution matching. We empirically verify the guarantees and limitations of several weak supervision methods (restricted labeling, match-pairing, and rank-pairing), demonstrating the predictive power and usefulness of our theoretical framework.
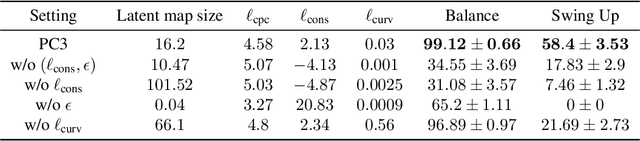
Prediction, Consistency, Curvature: Representation Learning for Locally-Linear Control
Sep 04, 2019


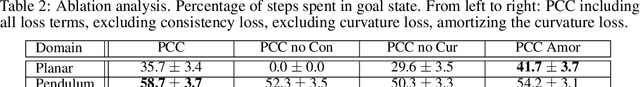
Many real-world sequential decision-making problems can be formulated as optimal control with high-dimensional observations and unknown dynamics. A promising approach is to embed the high-dimensional observations into a lower-dimensional latent representation space, estimate the latent dynamics model, then utilize this model for control in the latent space. An important open question is how to learn a representation that is amenable to existing control algorithms? In this paper, we focus on learning representations for locally-linear control algorithms, such as iterative LQR (iLQR). By formulating and analyzing the representation learning problem from an optimal control perspective, we establish three underlying principles that the learned representation should comprise: 1) accurate prediction in the observation space, 2) consistency between latent and observation space dynamics, and 3) low curvature in the latent space transitions. These principles naturally correspond to a loss function that consists of three terms: prediction, consistency, and curvature (PCC). Crucially, to make PCC tractable, we derive an amortized variational bound for the PCC loss function. Extensive experiments on benchmark domains demonstrate that the new variational-PCC learning algorithm benefits from significantly more stable and reproducible training, and leads to superior control performance. Further ablation studies give support to the importance of all three PCC components for learning a good latent space for control.