 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDazzle: Using Optimized Generative Adversarial Networks to Address Security Data Class Imbalance Issue
Mar 22, 2022

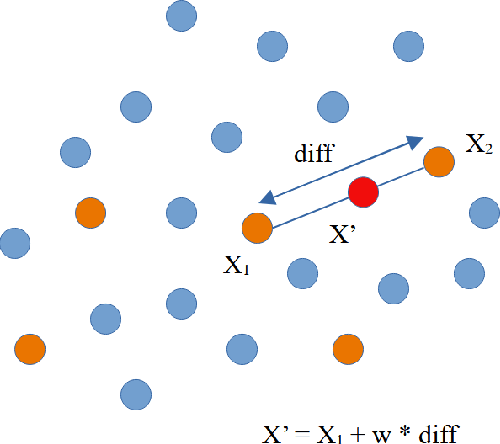
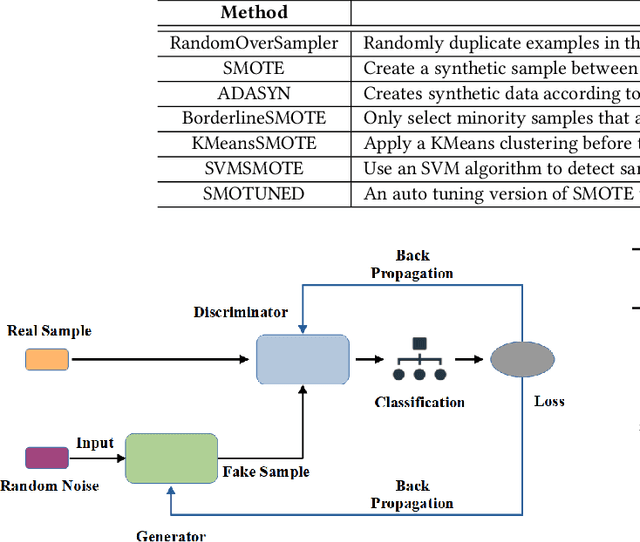
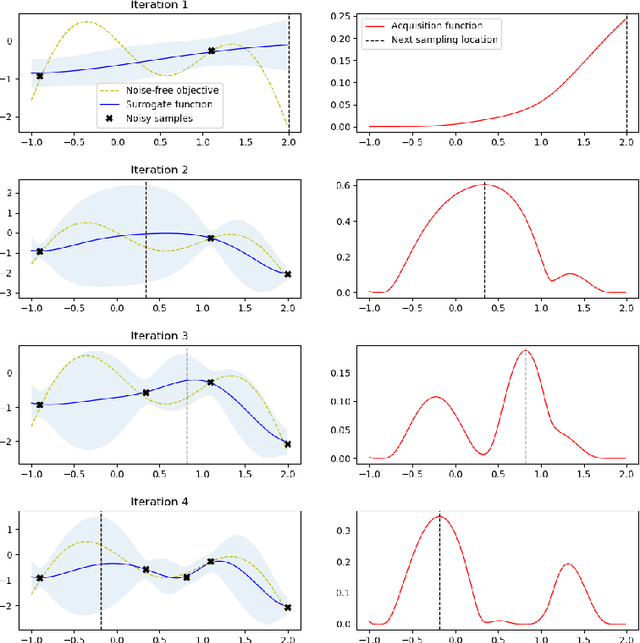
Background: Machine learning techniques have been widely used and demonstrate promising performance in many software security tasks such as software vulnerability prediction. However, the class ratio within software vulnerability datasets is often highly imbalanced (since the percentage of observed vulnerability is usually very low). Goal: To help security practitioners address software security data class imbalanced issues and further help build better prediction models with resampled datasets. Method: We introduce an approach called Dazzle which is an optimized version of conditional Wasserstein Generative Adversarial Networks with gradient penalty (cWGAN-GP). Dazzle explores the architecture hyperparameters of cWGAN-GP with a novel optimizer called Bayesian Optimization. We use Dazzle to generate minority class samples to resample the original imbalanced training dataset. Results: We evaluate Dazzle with three software security datasets, i.e., Moodle vulnerable files, Ambari bug reports, and JavaScript function code. We show that Dazzle is practical to use and demonstrates promising improvement over existing state-of-the-art oversampling techniques such as SMOTE (e.g., with an average of about 60% improvement rate over SMOTE in recall among all datasets). Conclusion: Based on this study, we would suggest the use of optimized GANs as an alternative method for security vulnerability data class imbalanced issues.
Omni: Automated Ensemble with Unexpected Models against Adversarial Evasion Attack
Nov 23, 2020
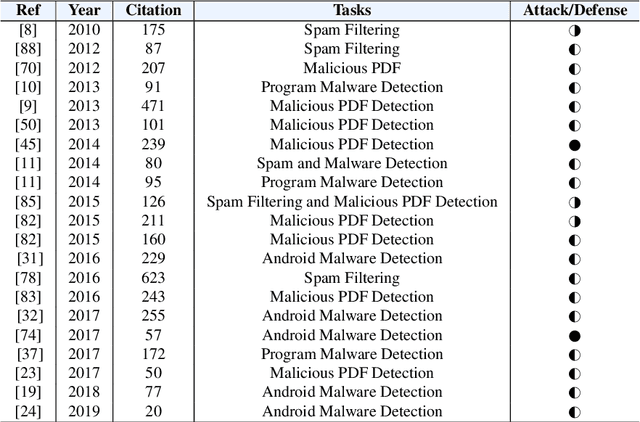

BACKGROUND: Machine learning-based security detection models have become prevalent in modern malware and intrusion detection systems. However, previous studies show that such models are susceptible to adversarial evasion attacks. In this type of attack, inputs (i.e., adversarial examples) are specially crafted by intelligent malicious adversaries, with the aim of being misclassified by existing state-of-the-art models (e.g., deep neural networks). Once the attackers can fool a classifier to think that a malicious input is actually benign, they can render a machine learning-based malware or intrusion detection system ineffective. GOAL: To help security practitioners and researchers build a more robust model against adversarial evasion attack through the use of ensemble learning. METHOD: We propose an approach called OMNI, the main idea of which is to explore methods that create an ensemble of "unexpected models"; i.e., models whose control hyperparameters have a large distance to the hyperparameters of an adversary's target model, with which we then make an optimized weighted ensemble prediction. RESULTS: In studies with five adversarial evasion attacks (FGSM, BIM, JSMA, DeepFool and Carlini-Wagner) on five security datasets (NSL-KDD, CIC-IDS-2017, CSE-CIC-IDS2018, CICAndMal2017 and the Contagio PDF dataset), we show that the improvement rate of OMNI's prediction accuracy over attack accuracy is about 53% (median value) across all datasets, with about 18% (median value) loss rate when comparing pre-attack accuracy and OMNI's prediction accuracy. CONCLUSIONWhen using ensemble learning as a defense method against adversarial evasion attacks, we suggest to create ensemble with unexpected models who are distant from the attacker's expected model (i.e., target model) through methods such as hyperparameter optimization.
Software Engineering for Fairness: A Case Study with Hyperparameter Optimization
May 14, 2019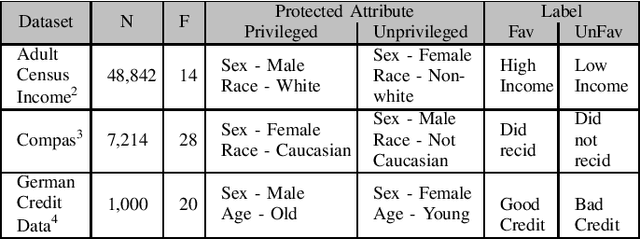
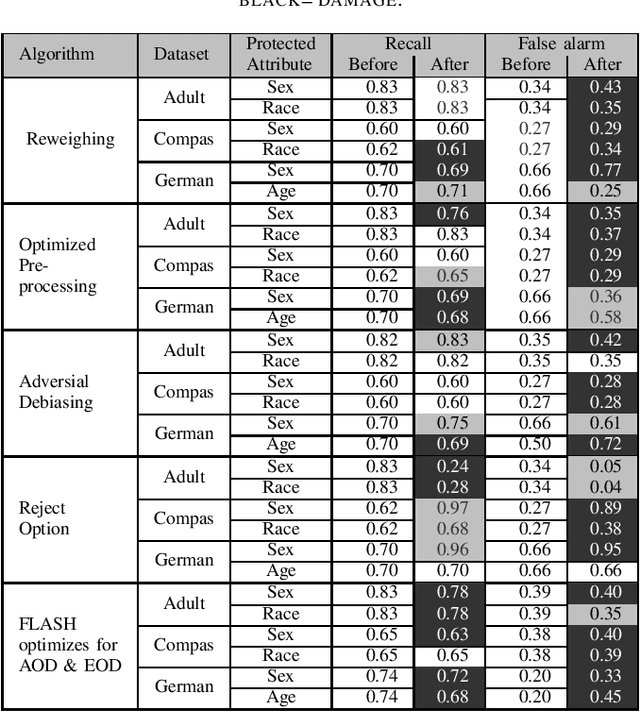
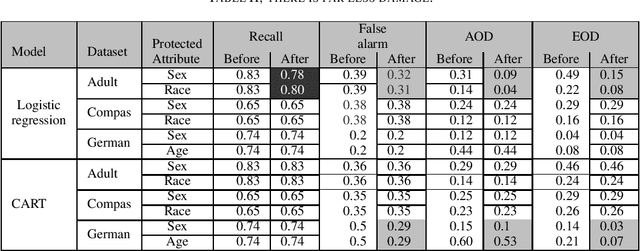
We assert that it is the ethical duty of software engineers to strive to reduce software discrimination. This paper discusses how that might be done. This is an important topic since machine learning software is increasingly being used to make decisions that affect people's lives. Potentially, the application of that software will result in fairer decisions because (unlike humans) machine learning software is not biased. However, recent results show that the software within many data mining packages exhibits "group discrimination"; i.e. their decisions are inappropriately affected by "protected attributes"(e.g., race, gender, age, etc.). There has been much prior work on validating the fairness of machine-learning models (by recognizing when such software discrimination exists). But after detection, comes mitigation. What steps can ethical software engineers take to reduce discrimination in the software they produce? This paper shows that making \textit{fairness} as a goal during hyperparameter optimization can (a) preserve the predictive power of a model learned from a data miner while also (b) generates fairer results. To the best of our knowledge, this is the first application of hyperparameter optimization as a tool for software engineers to generate fairer software.