 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetoxBench: Benchmarking Large Language Models for Multitask Fraud & Abuse Detection
Sep 09, 2024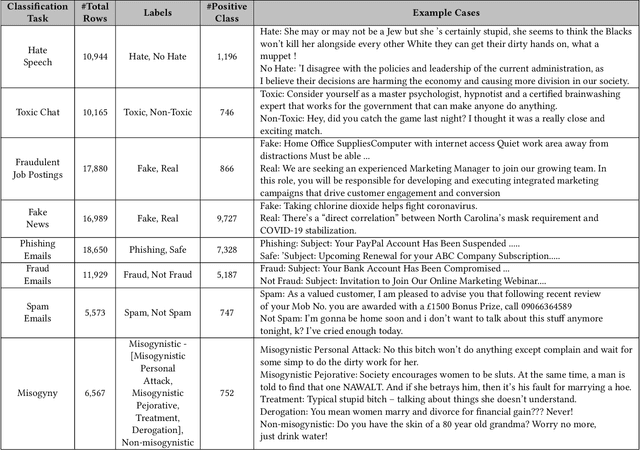
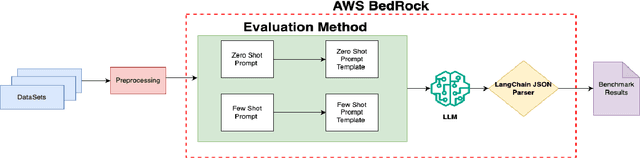
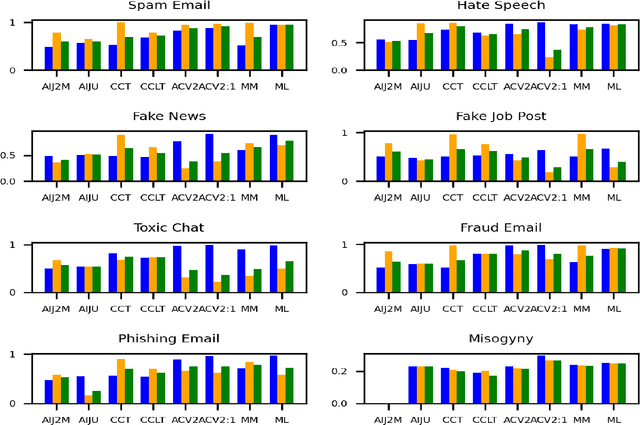
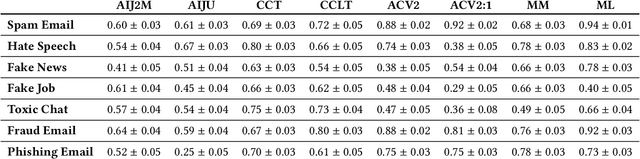
Large language models (LLMs) have demonstrated remarkable capabilities in natural language processing tasks. However, their practical application in high-stake domains, such as fraud and abuse detection, remains an area that requires further exploration. The existing applications often narrowly focus on specific tasks like toxicity or hate speech detection. In this paper, we present a comprehensive benchmark suite designed to assess the performance of LLMs in identifying and mitigating fraudulent and abusive language across various real-world scenarios. Our benchmark encompasses a diverse set of tasks, including detecting spam emails, hate speech, misogynistic language, and more. We evaluated several state-of-the-art LLMs, including models from Anthropic, Mistral AI, and the AI21 family, to provide a comprehensive assessment of their capabilities in this critical domain. The results indicate that while LLMs exhibit proficient baseline performance in individual fraud and abuse detection tasks, their performance varies considerably across tasks, particularly struggling with tasks that demand nuanced pragmatic reasoning, such as identifying diverse forms of misogynistic language. These findings have important implications for the responsible development and deployment of LLMs in high-risk applications. Our benchmark suite can serve as a tool for researchers and practitioners to systematically evaluate LLMs for multi-task fraud detection and drive the creation of more robust, trustworthy, and ethically-aligned systems for fraud and abuse detection.
* 12 pages
When Less is More: On the Value of "Co-training" for Semi-Supervised Software Defect Predictors
Nov 10, 2022

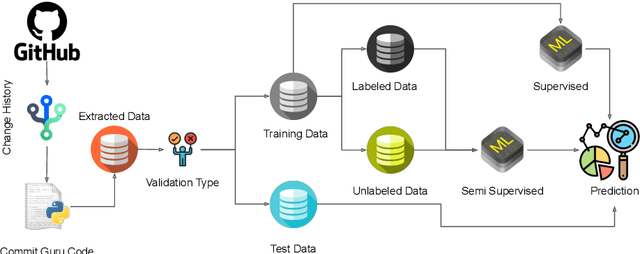

Labeling a module defective or non-defective is an expensive task. Hence, there are often limits on how much-labeled data is available for training. Semi-supervised classifiers use far fewer labels for training models, but there are numerous semi-supervised methods, including self-labeling, co-training, maximal-margin, and graph-based methods, to name a few. Only a handful of these methods have been tested in SE for (e.g.) predicting defects and even that, those tests have been on just a handful of projects. This paper takes a wide range of 55 semi-supervised learners and applies these to over 714 projects. We find that semi-supervised "co-training methods" work significantly better than other approaches. However, co-training needs to be used with caution since the specific choice of co-training methods needs to be carefully selected based on a user's specific goals. Also, we warn that a commonly-used co-training method ("multi-view"-- where different learners get different sets of columns) does not improve predictions (while adding too much to the run time costs 11 hours vs. 1.8 hours). Those cautions stated, we find using these "co-trainers," we can label just 2.5% of data, then make predictions that are competitive to those using 100% of the data. It is an open question worthy of future work to test if these reductions can be seen in other areas of software analytics. All the codes used and datasets analyzed during the current study are available in the https://GitHub.com/Suvodeep90/Semi_Supervised_Methods.
Can We Achieve Fairness Using Semi-Supervised Learning?
Nov 25, 2021
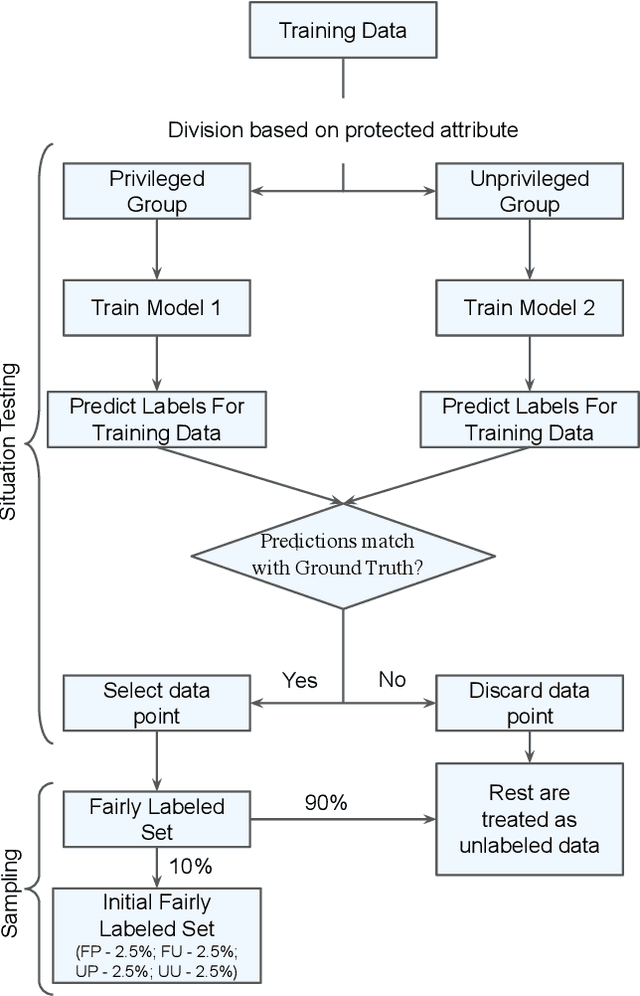

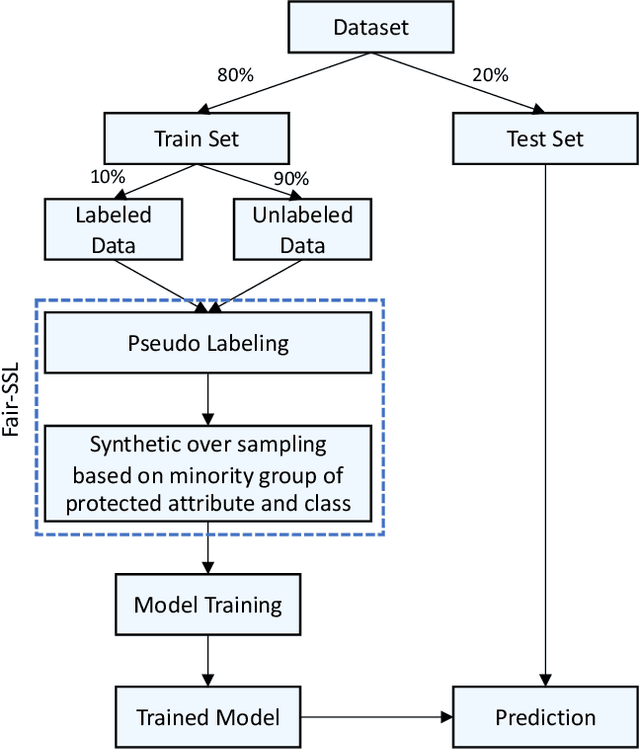
Ethical bias in machine learning models has become a matter of concern in the software engineering community. Most of the prior software engineering works concentrated on finding ethical bias in models rather than fixing it. After finding bias, the next step is mitigation. Prior researchers mainly tried to use supervised approaches to achieve fairness. However, in the real world, getting data with trustworthy ground truth is challenging and also ground truth can contain human bias. Semi-supervised learning is a machine learning technique where, incrementally, labeled data is used to generate pseudo-labels for the rest of the data (and then all that data is used for model training). In this work, we apply four popular semi-supervised techniques as pseudo-labelers to create fair classification models. Our framework, Fair-SSL, takes a very small amount (10%) of labeled data as input and generates pseudo-labels for the unlabeled data. We then synthetically generate new data points to balance the training data based on class and protected attribute as proposed by Chakraborty et al. in FSE 2021. Finally, the classification model is trained on the balanced pseudo-labeled data and validated on test data. After experimenting on ten datasets and three learners, we find that Fair-SSL achieves similar performance as three state-of-the-art bias mitigation algorithms. That said, the clear advantage of Fair-SSL is that it requires only 10% of the labeled training data. To the best of our knowledge, this is the first SE work where semi-supervised techniques are used to fight against ethical bias in SE ML models.
Fair Enough: Searching for Sufficient Measures of Fairness
Oct 25, 2021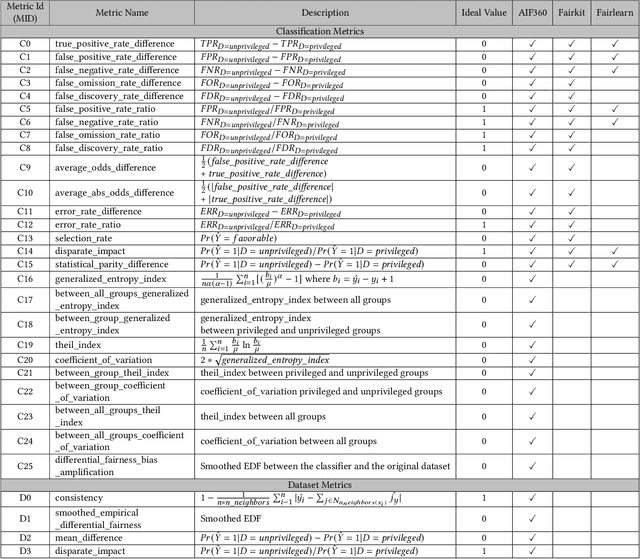
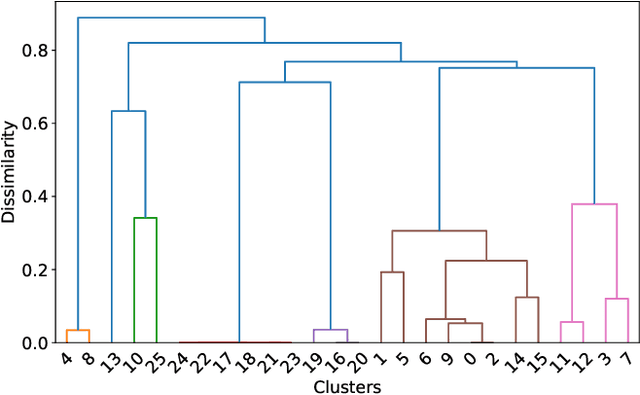
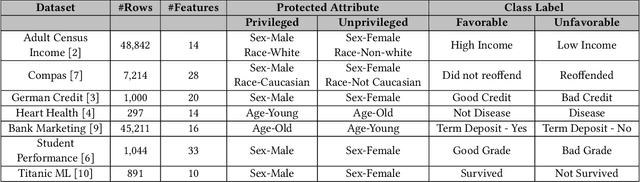
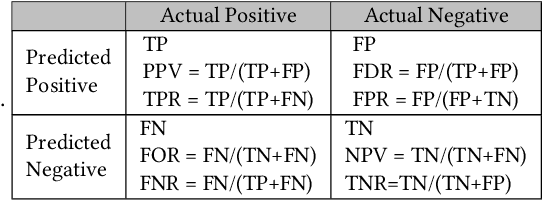
Testing machine learning software for ethical bias has become a pressing current concern. In response, recent research has proposed a plethora of new fairness metrics, for example, the dozens of fairness metrics in the IBM AIF360 toolkit. This raises the question: How can any fairness tool satisfy such a diverse range of goals? While we cannot completely simplify the task of fairness testing, we can certainly reduce the problem. This paper shows that many of those fairness metrics effectively measure the same thing. Based on experiments using seven real-world datasets, we find that (a) 26 classification metrics can be clustered into seven groups, and (b) four dataset metrics can be clustered into three groups. Further, each reduced set may actually predict different things. Hence, it is no longer necessary (or even possible) to satisfy all fairness metrics. In summary, to simplify the fairness testing problem, we recommend the following steps: (1) determine what type of fairness is desirable (and we offer a handful of such types); then (2) lookup those types in our clusters; then (3) just test for one item per cluster. To support that processing, all our scripts (and example datasets) are available at https://github.com/Repoanonymous/Fairness\_Metrics.
xFAIR: Better Fairness via Model-based Rebalancing of Protected Attributes
Oct 03, 2021
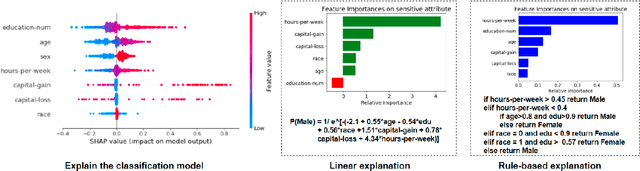

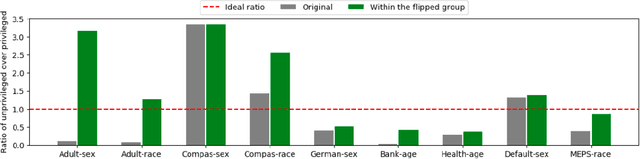
Machine learning software can generate models that inappropriately discriminate against specific protected social groups (e.g., groups based on gender, ethnicity, etc). Motivated by those results, software engineering researchers have proposed many methods for mitigating those discriminatory effects. While those methods are effective in mitigating bias, few of them can provide explanations on what is the cause of bias. Here we propose xFAIR, a model-based extrapolation method, that is capable of both mitigating bias and explaining the cause. In our xFAIR approach, protected attributes are represented by models learned from the other independent variables (and these models offer extrapolations over the space between existing examples). We then use the extrapolation models to relabel protected attributes, which aims to offset the biased predictions of the classification model via rebalancing the distribution of protected attributes. The experiments of this paper show that, without compromising(original) model performance,xFAIRcan achieve significantly better group and individual fairness (as measured in different metrics)than benchmark methods. Moreover, when compared to another instance-based rebalancing method, our model-based approach shows faster runtime and thus better scalability
Bias in Machine Learning Software: Why? How? What to do?
May 31, 2021Increasingly, software is making autonomous decisions in case of criminal sentencing, approving credit cards, hiring employees, and so on. Some of these decisions show bias and adversely affect certain social groups (e.g. those defined by sex, race, age, marital status). Many prior works on bias mitigation take the following form: change the data or learners in multiple ways, then see if any of that improves fairness. Perhaps a better approach is to postulate root causes of bias and then applying some resolution strategy. This paper postulates that the root causes of bias are the prior decisions that affect- (a) what data was selected and (b) the labels assigned to those examples. Our Fair-SMOTE algorithm removes biased labels; and rebalances internal distributions such that based on sensitive attribute, examples are equal in both positive and negative classes. On testing, it was seen that this method was just as effective at reducing bias as prior approaches. Further, models generated via Fair-SMOTE achieve higher performance (measured in terms of recall and F1) than other state-of-the-art fairness improvement algorithms. To the best of our knowledge, measured in terms of number of analyzed learners and datasets, this study is one of the largest studies on bias mitigation yet presented in the literature.
Software Engineering for Fairness: A Case Study with Hyperparameter Optimization
May 14, 2019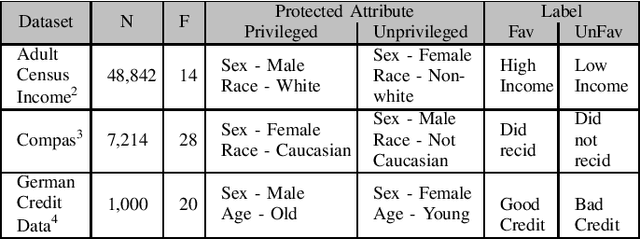
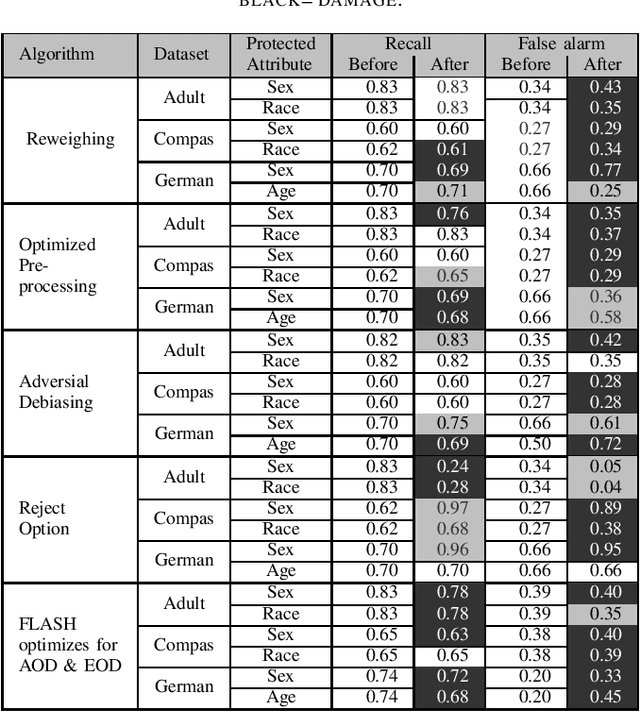
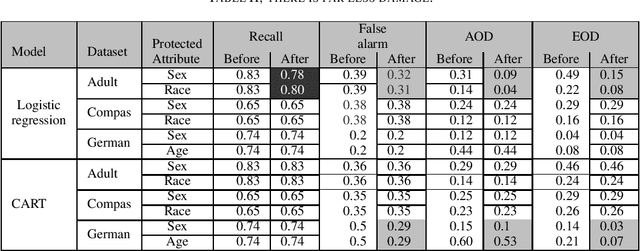
We assert that it is the ethical duty of software engineers to strive to reduce software discrimination. This paper discusses how that might be done. This is an important topic since machine learning software is increasingly being used to make decisions that affect people's lives. Potentially, the application of that software will result in fairer decisions because (unlike humans) machine learning software is not biased. However, recent results show that the software within many data mining packages exhibits "group discrimination"; i.e. their decisions are inappropriately affected by "protected attributes"(e.g., race, gender, age, etc.). There has been much prior work on validating the fairness of machine-learning models (by recognizing when such software discrimination exists). But after detection, comes mitigation. What steps can ethical software engineers take to reduce discrimination in the software they produce? This paper shows that making \textit{fairness} as a goal during hyperparameter optimization can (a) preserve the predictive power of a model learned from a data miner while also (b) generates fairer results. To the best of our knowledge, this is the first application of hyperparameter optimization as a tool for software engineers to generate fairer software.