 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhence Is A Model Fair? Fixing Fairness Bugs via Propensity Score Matching
Apr 23, 2025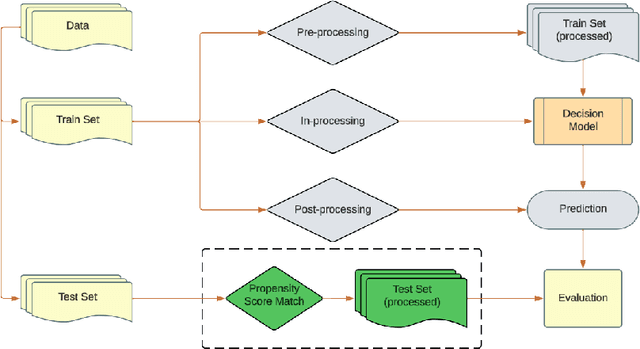


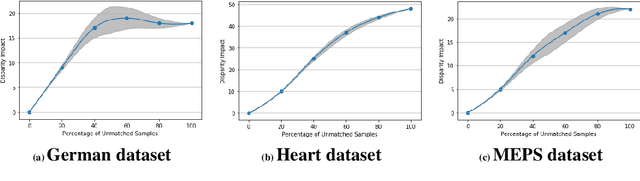
Fairness-aware learning aims to mitigate discrimination against specific protected social groups (e.g., those categorized by gender, ethnicity, age) while minimizing predictive performance loss. Despite efforts to improve fairness in machine learning, prior studies have shown that many models remain unfair when measured against various fairness metrics. In this paper, we examine whether the way training and testing data are sampled affects the reliability of reported fairness metrics. Since training and test sets are often randomly sampled from the same population, bias present in the training data may still exist in the test data, potentially skewing fairness assessments. To address this, we propose FairMatch, a post-processing method that applies propensity score matching to evaluate and mitigate bias. FairMatch identifies control and treatment pairs with similar propensity scores in the test set and adjusts decision thresholds for different subgroups accordingly. For samples that cannot be matched, we perform probabilistic calibration using fairness-aware loss functions. Experimental results demonstrate that our approach can (a) precisely locate subsets of the test data where the model is unbiased, and (b) significantly reduce bias on the remaining data. Overall, propensity score matching offers a principled way to improve both fairness evaluation and mitigation, without sacrificing predictive performance.
Combating Toxic Language: A Review of LLM-Based Strategies for Software Engineering
Apr 21, 2025


Large Language Models (LLMs) have become integral to software engineering (SE), where they are increasingly used in development workflows. However, their widespread use raises concerns about the presence and propagation of toxic language--harmful or offensive content that can foster exclusionary environments. This paper provides a comprehensive review of recent research on toxicity detection and mitigation, focusing on both SE-specific and general-purpose datasets. We examine annotation and preprocessing techniques, assess detection methodologies, and evaluate mitigation strategies, particularly those leveraging LLMs. Additionally, we conduct an ablation study demonstrating the effectiveness of LLM-based rewriting for reducing toxicity. By synthesizing existing work and identifying open challenges, this review highlights key areas for future research to ensure the responsible deployment of LLMs in SE and beyond.
Software Engineering Principles for Fairer Systems: Experiments with GroupCART
Apr 17, 2025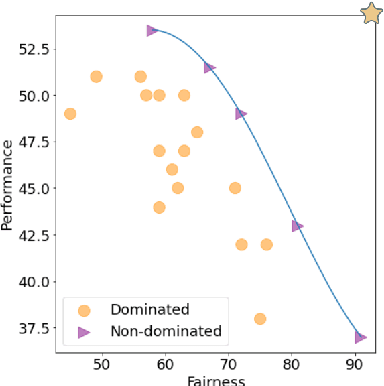

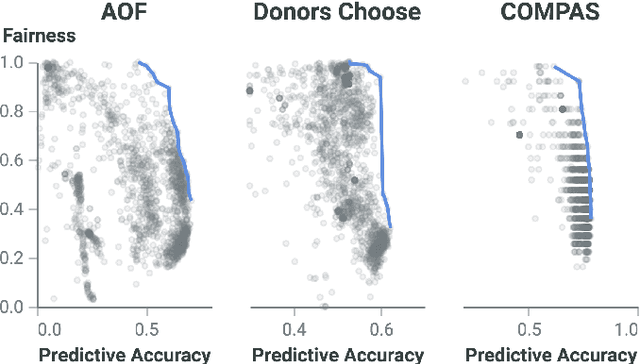

Discrimination-aware classification aims to make accurate predictions while satisfying fairness constraints. Traditional decision tree learners typically optimize for information gain in the target attribute alone, which can result in models that unfairly discriminate against protected social groups (e.g., gender, ethnicity). Motivated by these shortcomings, we propose GroupCART, a tree-based ensemble optimizer that avoids bias during model construction by optimizing not only for decreased entropy in the target attribute but also for increased entropy in protected attributes. Our experiments show that GroupCART achieves fairer models without data transformation and with minimal performance degradation. Furthermore, the method supports customizable weighting, offering a smooth and flexible trade-off between predictive performance and fairness based on user requirements. These results demonstrate that algorithmic bias in decision tree models can be mitigated through multi-task, fairness-aware learning. All code and datasets used in this study are available at: https://github.com/anonymous12138/groupCART.
Context Retrieval via Normalized Contextual Latent Interaction for Conversational Agent
Dec 01, 2023Conversational agents leveraging AI, particularly deep learning, are emerging in both academic research and real-world applications. However, these applications still face challenges, including disrespecting knowledge and facts, not personalizing to user preferences, and enormous demand for computational resources during training and inference. Recent research efforts have been focused on addressing these challenges from various aspects, including supplementing various types of auxiliary information to the conversational agents. However, existing methods are still not able to effectively and efficiently exploit relevant information from these auxiliary supplements to further unleash the power of the conversational agents and the language models they use. In this paper, we present a novel method, PK-NCLI, that is able to accurately and efficiently identify relevant auxiliary information to improve the quality of conversational responses by learning the relevance among persona, chat history, and knowledge background through low-level normalized contextual latent interaction. Our experimental results indicate that PK-NCLI outperforms the state-of-the-art method, PK-FoCus, by 47.80%/30.61%/24.14% in terms of perplexity, knowledge grounding, and training efficiency, respectively, and maintained the same level of persona grounding performance. We also provide a detailed analysis of how different factors, including language model choices and trade-offs on training weights, would affect the performance of PK-NCLI.
xFAIR: Better Fairness via Model-based Rebalancing of Protected Attributes
Oct 03, 2021
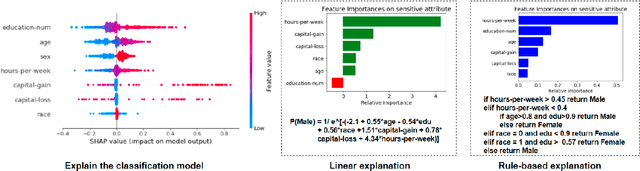

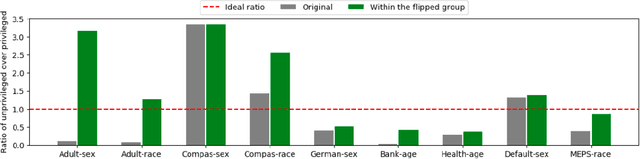
Machine learning software can generate models that inappropriately discriminate against specific protected social groups (e.g., groups based on gender, ethnicity, etc). Motivated by those results, software engineering researchers have proposed many methods for mitigating those discriminatory effects. While those methods are effective in mitigating bias, few of them can provide explanations on what is the cause of bias. Here we propose xFAIR, a model-based extrapolation method, that is capable of both mitigating bias and explaining the cause. In our xFAIR approach, protected attributes are represented by models learned from the other independent variables (and these models offer extrapolations over the space between existing examples). We then use the extrapolation models to relabel protected attributes, which aims to offset the biased predictions of the classification model via rebalancing the distribution of protected attributes. The experiments of this paper show that, without compromising(original) model performance,xFAIRcan achieve significantly better group and individual fairness (as measured in different metrics)than benchmark methods. Moreover, when compared to another instance-based rebalancing method, our model-based approach shows faster runtime and thus better scalability
Fairer Software Made Easier (using "Keys")
Jul 11, 2021
Can we simplify explanations for software analytics? Maybe. Recent results show that systems often exhibit a "keys effect"; i.e. a few key features control the rest. Just to say the obvious, for systems controlled by a few keys, explanation and control is just a matter of running a handful of "what-if" queries across the keys. By exploiting the keys effect, it should be possible to dramatically simplify even complex explanations, such as those required for ethical AI systems.