 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Toxic Language: A Review of LLM-Based Strategies for Software Engineering
Paper and Code


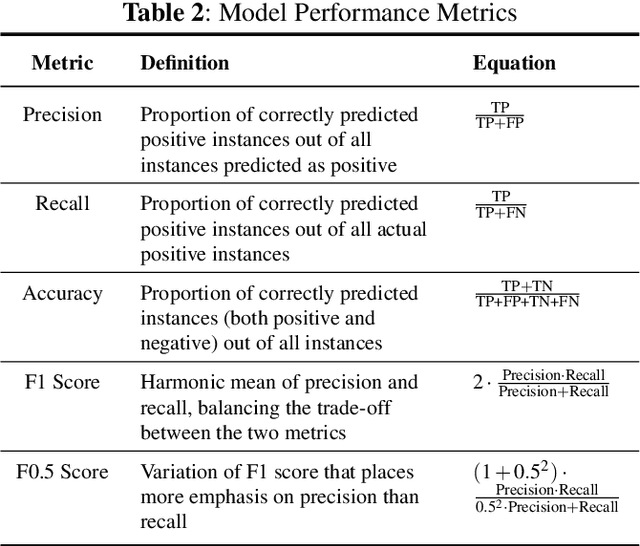

Large Language Models (LLMs) have become integral to software engineering (SE), where they are increasingly used in development workflows. However, their widespread use raises concerns about the presence and propagation of toxic language--harmful or offensive content that can foster exclusionary environments. This paper provides a comprehensive review of recent research on toxicity detection and mitigation, focusing on both SE-specific and general-purpose datasets. We examine annotation and preprocessing techniques, assess detection methodologies, and evaluate mitigation strategies, particularly those leveraging LLMs. Additionally, we conduct an ablation study demonstrating the effectiveness of LLM-based rewriting for reducing toxicity. By synthesizing existing work and identifying open challenges, this review highlights key areas for future research to ensure the responsible deployment of LLMs in SE and beyond.