 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhence Is A Model Fair? Fixing Fairness Bugs via Propensity Score Matching
Apr 23, 2025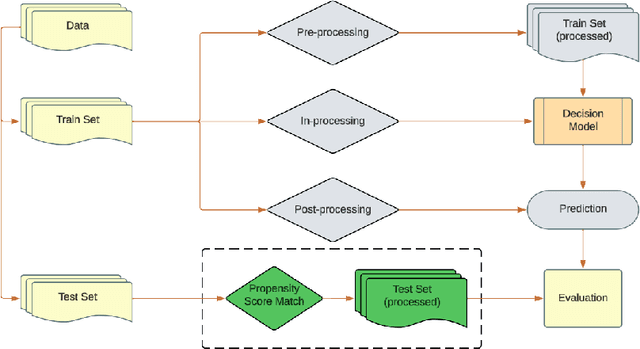


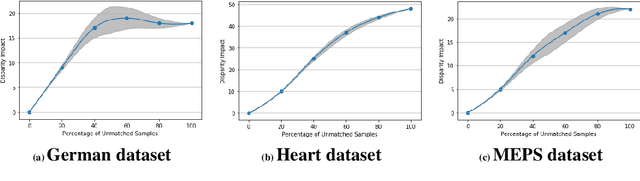
Fairness-aware learning aims to mitigate discrimination against specific protected social groups (e.g., those categorized by gender, ethnicity, age) while minimizing predictive performance loss. Despite efforts to improve fairness in machine learning, prior studies have shown that many models remain unfair when measured against various fairness metrics. In this paper, we examine whether the way training and testing data are sampled affects the reliability of reported fairness metrics. Since training and test sets are often randomly sampled from the same population, bias present in the training data may still exist in the test data, potentially skewing fairness assessments. To address this, we propose FairMatch, a post-processing method that applies propensity score matching to evaluate and mitigate bias. FairMatch identifies control and treatment pairs with similar propensity scores in the test set and adjusts decision thresholds for different subgroups accordingly. For samples that cannot be matched, we perform probabilistic calibration using fairness-aware loss functions. Experimental results demonstrate that our approach can (a) precisely locate subsets of the test data where the model is unbiased, and (b) significantly reduce bias on the remaining data. Overall, propensity score matching offers a principled way to improve both fairness evaluation and mitigation, without sacrificing predictive performance.
Combating Toxic Language: A Review of LLM-Based Strategies for Software Engineering
Apr 21, 2025

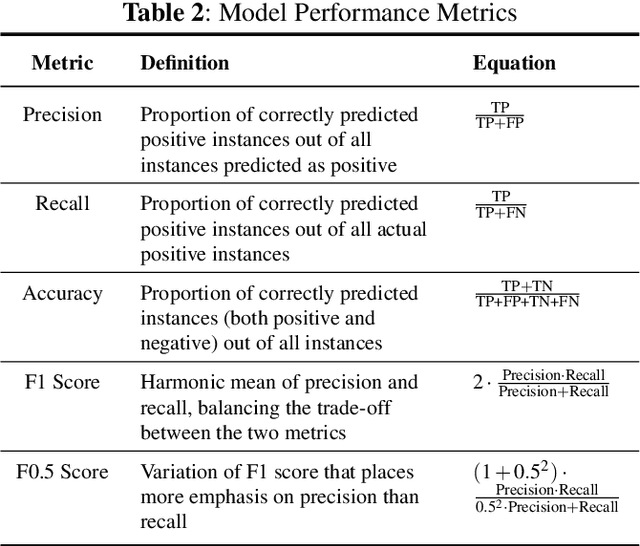

Large Language Models (LLMs) have become integral to software engineering (SE), where they are increasingly used in development workflows. However, their widespread use raises concerns about the presence and propagation of toxic language--harmful or offensive content that can foster exclusionary environments. This paper provides a comprehensive review of recent research on toxicity detection and mitigation, focusing on both SE-specific and general-purpose datasets. We examine annotation and preprocessing techniques, assess detection methodologies, and evaluate mitigation strategies, particularly those leveraging LLMs. Additionally, we conduct an ablation study demonstrating the effectiveness of LLM-based rewriting for reducing toxicity. By synthesizing existing work and identifying open challenges, this review highlights key areas for future research to ensure the responsible deployment of LLMs in SE and beyond.
Software Engineering Principles for Fairer Systems: Experiments with GroupCART
Apr 17, 2025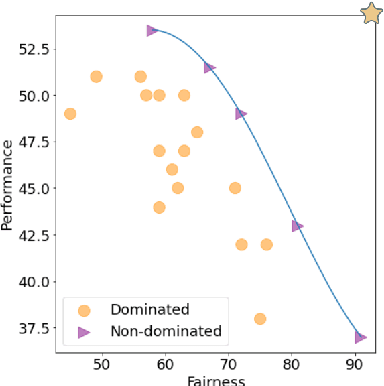

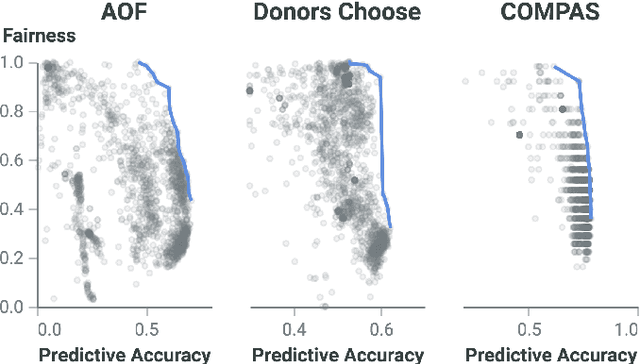

Discrimination-aware classification aims to make accurate predictions while satisfying fairness constraints. Traditional decision tree learners typically optimize for information gain in the target attribute alone, which can result in models that unfairly discriminate against protected social groups (e.g., gender, ethnicity). Motivated by these shortcomings, we propose GroupCART, a tree-based ensemble optimizer that avoids bias during model construction by optimizing not only for decreased entropy in the target attribute but also for increased entropy in protected attributes. Our experiments show that GroupCART achieves fairer models without data transformation and with minimal performance degradation. Furthermore, the method supports customizable weighting, offering a smooth and flexible trade-off between predictive performance and fairness based on user requirements. These results demonstrate that algorithmic bias in decision tree models can be mitigated through multi-task, fairness-aware learning. All code and datasets used in this study are available at: https://github.com/anonymous12138/groupCART.
DreamMix: Decoupling Object Attributes for Enhanced Editability in Customized Image Inpainting
Nov 26, 2024Subject-driven image inpainting has emerged as a popular task in image editing alongside recent advancements in diffusion models. Previous methods primarily focus on identity preservation but struggle to maintain the editability of inserted objects. In response, this paper introduces DreamMix, a diffusion-based generative model adept at inserting target objects into given scenes at user-specified locations while concurrently enabling arbitrary text-driven modifications to their attributes. In particular, we leverage advanced foundational inpainting models and introduce a disentangled local-global inpainting framework to balance precise local object insertion with effective global visual coherence. Additionally, we propose an Attribute Decoupling Mechanism (ADM) and a Textual Attribute Substitution (TAS) module to improve the diversity and discriminative capability of the text-based attribute guidance, respectively. Extensive experiments demonstrate that DreamMix effectively balances identity preservation and attribute editability across various application scenarios, including object insertion, attribute editing, and small object inpainting. Our code is publicly available at https://github.com/mycfhs/DreamMix.
Movie Recommendation with Poster Attention via Multi-modal Transformer Feature Fusion
Jul 12, 2024



Pre-trained models learn general representations from large datsets which can be fine-turned for specific tasks to significantly reduce training time. Pre-trained models like generative pretrained transformers (GPT), bidirectional encoder representations from transformers (BERT), vision transfomers (ViT) have become a cornerstone of current research in machine learning. This study proposes a multi-modal movie recommendation system by extract features of the well designed posters for each movie and the narrative text description of the movie. This system uses the BERT model to extract the information of text modality, the ViT model applied to extract the information of poster/image modality, and the Transformer architecture for feature fusion of all modalities to predict users' preference. The integration of pre-trained foundational models with some smaller data sets in downstream applications capture multi-modal content features in a more comprehensive manner, thereby providing more accurate recommendations. The efficiency of the proof-of-concept model is verified by the standard benchmark problem the MovieLens 100K and 1M datasets. The prediction accuracy of user ratings is enhanced in comparison to the baseline algorithm, thereby demonstrating the potential of this cross-modal algorithm to be applied for movie or video recommendation.
Automatic question generation for propositional logical equivalences
May 09, 2024


The increase in academic dishonesty cases among college students has raised concern, particularly due to the shift towards online learning caused by the pandemic. We aim to develop and implement a method capable of generating tailored questions for each student. The use of Automatic Question Generation (AQG) is a possible solution. Previous studies have investigated AQG frameworks in education, which include validity, user-defined difficulty, and personalized problem generation. Our new AQG approach produces logical equivalence problems for Discrete Mathematics, which is a core course for year-one computer science students. This approach utilizes a syntactic grammar and a semantic attribute system through top-down parsing and syntax tree transformations. Our experiments show that the difficulty level of questions generated by our AQG approach is similar to the questions presented to students in the textbook [1]. These results confirm the practicality of our AQG approach for automated question generation in education, with the potential to significantly enhance learning experiences.