 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFXMaster: Unlocking Dynamic Visual Effect Generation via In-Context Learning
Oct 29, 2025Visual effects (VFX) are crucial to the expressive power of digital media, yet their creation remains a major challenge for generative AI. Prevailing methods often rely on the one-LoRA-per-effect paradigm, which is resource-intensive and fundamentally incapable of generalizing to unseen effects, thus limiting scalability and creation. To address this challenge, we introduce VFXMaster, the first unified, reference-based framework for VFX video generation. It recasts effect generation as an in-context learning task, enabling it to reproduce diverse dynamic effects from a reference video onto target content. In addition, it demonstrates remarkable generalization to unseen effect categories. Specifically, we design an in-context conditioning strategy that prompts the model with a reference example. An in-context attention mask is designed to precisely decouple and inject the essential effect attributes, allowing a single unified model to master the effect imitation without information leakage. In addition, we propose an efficient one-shot effect adaptation mechanism to boost generalization capability on tough unseen effects from a single user-provided video rapidly. Extensive experiments demonstrate that our method effectively imitates various categories of effect information and exhibits outstanding generalization to out-of-domain effects. To foster future research, we will release our code, models, and a comprehensive dataset to the community.
RAP: Real-time Audio-driven Portrait Animation with Video Diffusion Transformer
Aug 07, 2025Audio-driven portrait animation aims to synthesize realistic and natural talking head videos from an input audio signal and a single reference image. While existing methods achieve high-quality results by leveraging high-dimensional intermediate representations and explicitly modeling motion dynamics, their computational complexity renders them unsuitable for real-time deployment. Real-time inference imposes stringent latency and memory constraints, often necessitating the use of highly compressed latent representations. However, operating in such compact spaces hinders the preservation of fine-grained spatiotemporal details, thereby complicating audio-visual synchronization RAP (Real-time Audio-driven Portrait animation), a unified framework for generating high-quality talking portraits under real-time constraints. Specifically, RAP introduces a hybrid attention mechanism for fine-grained audio control, and a static-dynamic training-inference paradigm that avoids explicit motion supervision. Through these techniques, RAP achieves precise audio-driven control, mitigates long-term temporal drift, and maintains high visual fidelity. Extensive experiments demonstrate that RAP achieves state-of-the-art performance while operating under real-time constraints.
Regularizing Subspace Redundancy of Low-Rank Adaptation
Jul 28, 2025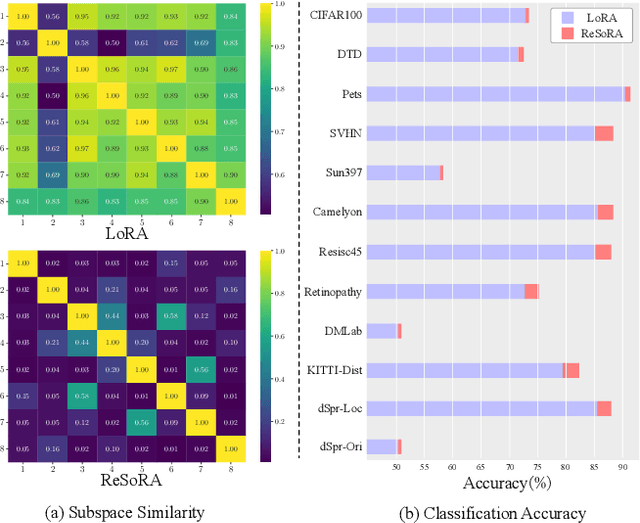
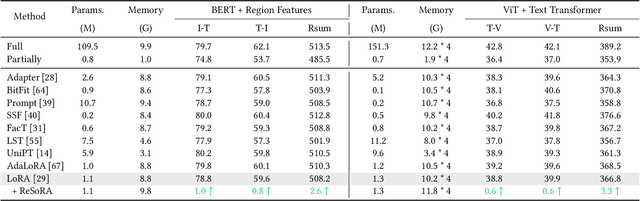
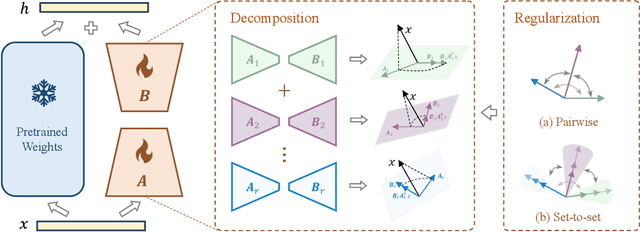
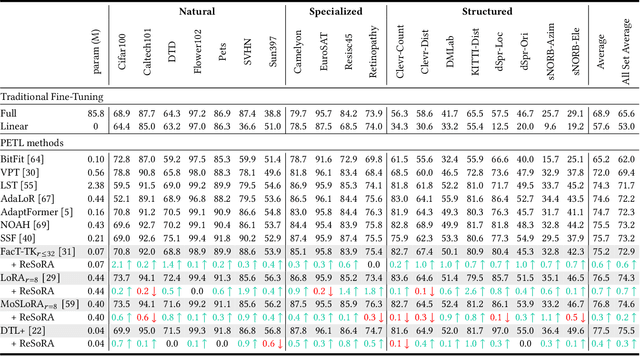
Low-Rank Adaptation (LoRA) and its variants have delivered strong capability in Parameter-Efficient Transfer Learning (PETL) by minimizing trainable parameters and benefiting from reparameterization. However, their projection matrices remain unrestricted during training, causing high representation redundancy and diminishing the effectiveness of feature adaptation in the resulting subspaces. While existing methods mitigate this by manually adjusting the rank or implicitly applying channel-wise masks, they lack flexibility and generalize poorly across various datasets and architectures. Hence, we propose ReSoRA, a method that explicitly models redundancy between mapping subspaces and adaptively Regularizes Subspace redundancy of Low-Rank Adaptation. Specifically, it theoretically decomposes the low-rank submatrices into multiple equivalent subspaces and systematically applies de-redundancy constraints to the feature distributions across different projections. Extensive experiments validate that our proposed method consistently facilitates existing state-of-the-art PETL methods across various backbones and datasets in vision-language retrieval and standard visual classification benchmarks. Besides, as a training supervision, ReSoRA can be seamlessly integrated into existing approaches in a plug-and-play manner, with no additional inference costs. Code is publicly available at: https://github.com/Lucenova/ReSoRA.
ECCV 2024 W-CODA: 1st Workshop on Multimodal Perception and Comprehension of Corner Cases in Autonomous Driving
Jul 02, 2025
In this paper, we present details of the 1st W-CODA workshop, held in conjunction with the ECCV 2024. W-CODA aims to explore next-generation solutions for autonomous driving corner cases, empowered by state-of-the-art multimodal perception and comprehension techniques. 5 Speakers from both academia and industry are invited to share their latest progress and opinions. We collect research papers and hold a dual-track challenge, including both corner case scene understanding and generation. As the pioneering effort, we will continuously bridge the gap between frontier autonomous driving techniques and fully intelligent, reliable self-driving agents robust towards corner cases.
CCL-LGS: Contrastive Codebook Learning for 3D Language Gaussian Splatting
May 26, 2025



Recent advances in 3D reconstruction techniques and vision-language models have fueled significant progress in 3D semantic understanding, a capability critical to robotics, autonomous driving, and virtual/augmented reality. However, methods that rely on 2D priors are prone to a critical challenge: cross-view semantic inconsistencies induced by occlusion, image blur, and view-dependent variations. These inconsistencies, when propagated via projection supervision, deteriorate the quality of 3D Gaussian semantic fields and introduce artifacts in the rendered outputs. To mitigate this limitation, we propose CCL-LGS, a novel framework that enforces view-consistent semantic supervision by integrating multi-view semantic cues. Specifically, our approach first employs a zero-shot tracker to align a set of SAM-generated 2D masks and reliably identify their corresponding categories. Next, we utilize CLIP to extract robust semantic encodings across views. Finally, our Contrastive Codebook Learning (CCL) module distills discriminative semantic features by enforcing intra-class compactness and inter-class distinctiveness. In contrast to previous methods that directly apply CLIP to imperfect masks, our framework explicitly resolves semantic conflicts while preserving category discriminability. Extensive experiments demonstrate that CCL-LGS outperforms previous state-of-the-art methods. Our project page is available at https://epsilontl.github.io/CCL-LGS/.
EvMic: Event-based Non-contact sound recovery from effective spatial-temporal modeling
Apr 03, 2025When sound waves hit an object, they induce vibrations that produce high-frequency and subtle visual changes, which can be used for recovering the sound. Early studies always encounter trade-offs related to sampling rate, bandwidth, field of view, and the simplicity of the optical path. Recent advances in event camera hardware show good potential for its application in visual sound recovery, because of its superior ability in capturing high-frequency signals. However, existing event-based vibration recovery methods are still sub-optimal for sound recovery. In this work, we propose a novel pipeline for non-contact sound recovery, fully utilizing spatial-temporal information from the event stream. We first generate a large training set using a novel simulation pipeline. Then we designed a network that leverages the sparsity of events to capture spatial information and uses Mamba to model long-term temporal information. Lastly, we train a spatial aggregation block to aggregate information from different locations to further improve signal quality. To capture event signals caused by sound waves, we also designed an imaging system using a laser matrix to enhance the gradient and collected multiple data sequences for testing. Experimental results on synthetic and real-world data demonstrate the effectiveness of our method.
Towards Physically Plausible Video Generation via VLM Planning
Mar 30, 2025Video diffusion models (VDMs) have advanced significantly in recent years, enabling the generation of highly realistic videos and drawing the attention of the community in their potential as world simulators. However, despite their capabilities, VDMs often fail to produce physically plausible videos due to an inherent lack of understanding of physics, resulting in incorrect dynamics and event sequences. To address this limitation, we propose a novel two-stage image-to-video generation framework that explicitly incorporates physics. In the first stage, we employ a Vision Language Model (VLM) as a coarse-grained motion planner, integrating chain-of-thought and physics-aware reasoning to predict a rough motion trajectories/changes that approximate real-world physical dynamics while ensuring the inter-frame consistency. In the second stage, we use the predicted motion trajectories/changes to guide the video generation of a VDM. As the predicted motion trajectories/changes are rough, noise is added during inference to provide freedom to the VDM in generating motion with more fine details. Extensive experimental results demonstrate that our framework can produce physically plausible motion, and comparative evaluations highlight the notable superiority of our approach over existing methods. More video results are available on our Project Page: https://madaoer.github.io/projects/physically_plausible_video_generation.
GeoRSMLLM: A Multimodal Large Language Model for Vision-Language Tasks in Geoscience and Remote Sensing
Mar 16, 2025The application of Vision-Language Models (VLMs) in remote sensing (RS) has demonstrated significant potential in traditional tasks such as scene classification, object detection, and image captioning. However, current models, which excel in Referring Expression Comprehension (REC), struggle with tasks involving complex instructions (e.g., exists multiple conditions) or pixel-level operations like segmentation and change detection. In this white paper, we provide a comprehensive hierarchical summary of vision-language tasks in RS, categorized by the varying levels of cognitive capability required. We introduce the Remote Sensing Vision-Language Task Set (RSVLTS), which includes Open-Vocabulary Tasks (OVT), Referring Expression Tasks (RET), and Described Object Tasks (DOT) with increased difficulty, and Visual Question Answering (VQA) aloneside. Moreover, we propose a novel unified data representation using a set-of-points approach for RSVLTS, along with a condition parser and a self-augmentation strategy based on cyclic referring. These features are integrated into the GeoRSMLLM model, and this enhanced model is designed to handle a broad range of tasks of RSVLTS, paving the way for a more generalized solution for vision-language tasks in geoscience and remote sensing.
One Size doesn't Fit All: A Personalized Conversational Tutoring Agent for Mathematics Instruction
Feb 19, 2025Large language models (LLMs) have been increasingly employed in various intelligent educational systems, simulating human tutors to facilitate effective human-machine interaction. However, previous studies often overlook the significance of recognizing and adapting to individual learner characteristics. Such adaptation is crucial for enhancing student engagement and learning efficiency, particularly in mathematics instruction, where diverse learning styles require personalized strategies to promote comprehension and enthusiasm. In this paper, we propose a \textbf{P}erson\textbf{A}lized \textbf{C}onversational tutoring ag\textbf{E}nt (PACE) for mathematics instruction. PACE simulates students' learning styles based on the Felder and Silverman learning style model, aligning with each student's persona. In this way, our PACE can effectively assess the personality of students, allowing to develop individualized teaching strategies that resonate with their unique learning styles. To further enhance students' comprehension, PACE employs the Socratic teaching method to provide instant feedback and encourage deep thinking. By constructing personalized teaching data and training models, PACE demonstrates the ability to identify and adapt to the unique needs of each student, significantly improving the overall learning experience and outcomes. Moreover, we establish multi-aspect evaluation criteria and conduct extensive analysis to assess the performance of personalized teaching. Experimental results demonstrate the superiority of our model in personalizing the educational experience and motivating students compared to existing methods.
CineMaster: A 3D-Aware and Controllable Framework for Cinematic Text-to-Video Generation
Feb 12, 2025In this work, we present CineMaster, a novel framework for 3D-aware and controllable text-to-video generation. Our goal is to empower users with comparable controllability as professional film directors: precise placement of objects within the scene, flexible manipulation of both objects and camera in 3D space, and intuitive layout control over the rendered frames. To achieve this, CineMaster operates in two stages. In the first stage, we design an interactive workflow that allows users to intuitively construct 3D-aware conditional signals by positioning object bounding boxes and defining camera movements within the 3D space. In the second stage, these control signals--comprising rendered depth maps, camera trajectories and object class labels--serve as the guidance for a text-to-video diffusion model, ensuring to generate the user-intended video content. Furthermore, to overcome the scarcity of in-the-wild datasets with 3D object motion and camera pose annotations, we carefully establish an automated data annotation pipeline that extracts 3D bounding boxes and camera trajectories from large-scale video data. Extensive qualitative and quantitative experiments demonstrate that CineMaster significantly outperforms existing methods and implements prominent 3D-aware text-to-video generation. Project page: https://cinemaster-dev.github.io/.