 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeClaw: Spec-Driven Security Task Synthesis for Evaluating Autonomous Agents
Jun 01, 2026Autonomous LLM agents increasingly operate in stateful environments where they access tools, files, memory, and external services. While such capabilities enable complex real-world workflows, they also introduce security risks that are difficult to capture with existing evaluations. Current agent security benchmarks often rely on manually curated tasks, provide limited coverage of emerging threats, and focus primarily on final outcomes rather than the execution processes that lead to unsafe behavior. We introduce SeClaw, a framework that combines specification-driven security task synthesis with execution-based security evaluation for Autonomous agents. Spec-driven security task synthesis enables scalable and controllable construction of security tasks from structured risk specifications, while SeClaw docker provides a standardized testbed for evaluating agent behavior under diverse safety-risk scenarios. The benchmark covers risks arising from resources, user tasks, environments, and intrinsic agent behaviors, and supports trajectory-aware assessment of unsafe actions beyond final responses. By bridging systematic task synthesis and reproducible security evaluation, SeClaw provides a practical foundation for measuring, diagnosing, and comparing security failures in autonomous LLM agents. The code is available at https://github.com/seclaw-eval/seclaw-eval.
DecMem: Towards Minute-Long Consistent World Generation with Decoupled Memory
May 29, 2026Recent advances in video generative models have promoted rapid progress in controllable world models. However, maintaining fine-grained spatio-temporal consistency under long-horizon reasoning remains a key challenge. In this work, we move beyond explicit 3D memory and coarse frame-level implicit modeling, and propose a fine-grained, learnable, and scalable memory for consistent world generation. We first identify two fundamental limitations of naïve learnable memory architectures in long-horizon extrapolation, namely computational inefficiency and attention dispersion. Through a systematic analysis of attention dispersion, we propose DecMem, a decoupled memory architecture that employs Sparse Global Memory for efficient fine-grained access to global history and Anchored Local Memory for stable and high-quality extrapolation. Extensive experiments demonstrate that DecMem significantly outperforms current state-of-the-art methods. By ensuring precise and efficient long-term memory and achieving superior extrapolation capabilities, DecMem enables minute-level controllable long video generation with high fidelity and consistency.
ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling
Mar 26, 2026Multi-shot video generation is crucial for long narrative storytelling, yet current bidirectional architectures suffer from limited interactivity and high latency. We propose ShotStream, a novel causal multi-shot architecture that enables interactive storytelling and efficient on-the-fly frame generation. By reformulating the task as next-shot generation conditioned on historical context, ShotStream allows users to dynamically instruct ongoing narratives via streaming prompts. We achieve this by first fine-tuning a text-to-video model into a bidirectional next-shot generator, which is then distilled into a causal student via Distribution Matching Distillation. To overcome the challenges of inter-shot consistency and error accumulation inherent in autoregressive generation, we introduce two key innovations. First, a dual-cache memory mechanism preserves visual coherence: a global context cache retains conditional frames for inter-shot consistency, while a local context cache holds generated frames within the current shot for intra-shot consistency. And a RoPE discontinuity indicator is employed to explicitly distinguish the two caches to eliminate ambiguity. Second, to mitigate error accumulation, we propose a two-stage distillation strategy. This begins with intra-shot self-forcing conditioned on ground-truth historical shots and progressively extends to inter-shot self-forcing using self-generated histories, effectively bridging the train-test gap. Extensive experiments demonstrate that ShotStream generates coherent multi-shot videos with sub-second latency, achieving 16 FPS on a single GPU. It matches or exceeds the quality of slower bidirectional models, paving the way for real-time interactive storytelling. Training and inference code, as well as the models, are available on our
SmoothVLA: Aligning Vision-Language-Action Models with Physical Constraints via Intrinsic Smoothness Optimization
Mar 14, 2026Vision-Language-Action (VLA) models have emerged as a powerful paradigm for robotic manipulation. However, existing post-training methods face a dilemma between stability and exploration: Supervised Fine-Tuning (SFT) is constrained by demonstration quality and lacks generalization, whereas Reinforcement Learning (RL) improves exploration but often induces erratic, jittery trajectories that violate physical constraints. To bridge this gap, we propose SmoothVLA, a novel reinforcement learning fine-tuning framework that synergistically optimizes task performance and motion smoothness. The technical core is a physics-informed hybrid reward function that integrates binary sparse task rewards with a continuous dense term derived from trajectory jerk. Crucially, this reward is intrinsic, that computing directly from policy rollouts, without requiring extrinsic environment feedback or laborious reward engineering. Leveraging the Group Relative Policy Optimization (GRPO), SmoothVLA establishes trajectory smoothness as an explicit optimization prior, guiding the model toward physically feasible and stable control. Extensive experiments on the LIBERO benchmark demonstrate that SmoothVLA outperforms standard RL by 13.8\% in smoothness and significantly surpasses SFT in generalization across diverse tasks. Our work offers a scalable approach to aligning VLA models with physical-world constraints through intrinsic reward optimization.
Fairness Begins with State: Purifying Latent Preferences for Hierarchical Reinforcement Learning in Interactive Recommendation
Mar 04, 2026Interactive recommender systems (IRS) are increasingly optimized with Reinforcement Learning (RL) to capture the sequential nature of user-system dynamics. However, existing fairness-aware methods often suffer from a fundamental oversight: they assume the observed user state is a faithful representation of true preferences. In reality, implicit feedback is contaminated by popularity-driven noise and exposure bias, creating a distorted state that misleads the RL agent. We argue that the persistent conflict between accuracy and fairness is not merely a reward-shaping issue, but a state estimation failure. In this work, we propose \textbf{DSRM-HRL}, a framework that reformulates fairness-aware recommendation as a latent state purification problem followed by decoupled hierarchical decision-making. We introduce a Denoising State Representation Module (DSRM) based on diffusion models to recover the low-entropy latent preference manifold from high-entropy, noisy interaction histories. Built upon this purified state, a Hierarchical Reinforcement Learning (HRL) agent is employed to decouple conflicting objectives: a high-level policy regulates long-term fairness trajectories, while a low-level policy optimizes short-term engagement under these dynamic constraints. Extensive experiments on high-fidelity simulators (KuaiRec, KuaiRand) demonstrate that DSRM-HRL effectively breaks the "rich-get-richer" feedback loop, achieving a superior Pareto frontier between recommendation utility and exposure equity.
Proactive Guiding Strategy for Item-side Fairness in Interactive Recommendation
Mar 03, 2026Item-side fairness is crucial for ensuring the fair exposure of long-tail items in interactive recommender systems. Existing approaches promote the exposure of long-tail items by directly incorporating them into recommended results. This causes misalignment between user preferences and the recommended long-tail items, which hinders long-term user engagement and reduces the effectiveness of recommendations. We aim for a proactive fairness-guiding strategy, which actively guides user preferences toward long-tail items while preserving user satisfaction during the interactive recommendation process. To this end, we propose HRL4PFG, an interactive recommendation framework that leverages hierarchical reinforcement learning to guide user preferences toward long-tail items progressively. HRL4PFG operates through a macro-level process that generates fairness-guided targets based on multi-step feedback, and a micro-level process that fine-tunes recommendations in real time according to both these targets and evolving user preferences. Extensive experiments show that HRL4PFG improves cumulative interaction rewards and maximum user interaction length by a larger margin when compared with state-of-the-art methods in interactive recommendation environments.
Kling-MotionControl Technical Report
Mar 03, 2026Character animation aims to generate lifelike videos by transferring motion dynamics from a driving video to a reference image. Recent strides in generative models have paved the way for high-fidelity character animation. In this work, we present Kling-MotionControl, a unified DiT-based framework engineered specifically for robust, precise, and expressive holistic character animation. Leveraging a divide-and-conquer strategy within a cohesive system, the model orchestrates heterogeneous motion representations tailored to the distinct characteristics of body, face, and hands, effectively reconciling large-scale structural stability with fine-grained articulatory expressiveness. To ensure robust cross-identity generalization, we incorporate adaptive identity-agnostic learning, facilitating natural motion retargeting for diverse characters ranging from realistic humans to stylized cartoons. Simultaneously, we guarantee faithful appearance preservation through meticulous identity injection and fusion designs, further supported by a subject library mechanism that leverages comprehensive reference contexts. To ensure practical utility, we implement an advanced acceleration framework utilizing multi-stage distillation, boosting inference speed by over 10x. Kling-MotionControl distinguishes itself through intelligent semantic motion understanding and precise text responsiveness, allowing for flexible control beyond visual inputs. Human preference evaluations demonstrate that Kling-MotionControl delivers superior performance compared to leading commercial and open-source solutions, achieving exceptional fidelity in holistic motion control, open domain generalization, and visual quality and coherence. These results establish Kling-MotionControl as a robust solution for high-quality, controllable, and lifelike character animation.
SemanticGen: Video Generation in Semantic Space
Dec 24, 2025

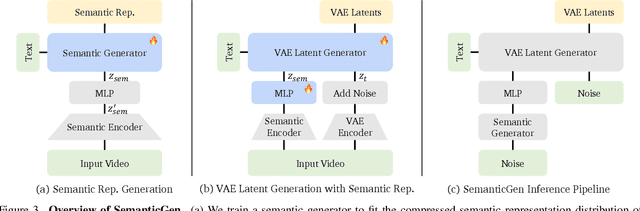

State-of-the-art video generative models typically learn the distribution of video latents in the VAE space and map them to pixels using a VAE decoder. While this approach can generate high-quality videos, it suffers from slow convergence and is computationally expensive when generating long videos. In this paper, we introduce SemanticGen, a novel solution to address these limitations by generating videos in the semantic space. Our main insight is that, due to the inherent redundancy in videos, the generation process should begin in a compact, high-level semantic space for global planning, followed by the addition of high-frequency details, rather than directly modeling a vast set of low-level video tokens using bi-directional attention. SemanticGen adopts a two-stage generation process. In the first stage, a diffusion model generates compact semantic video features, which define the global layout of the video. In the second stage, another diffusion model generates VAE latents conditioned on these semantic features to produce the final output. We observe that generation in the semantic space leads to faster convergence compared to the VAE latent space. Our method is also effective and computationally efficient when extended to long video generation. Extensive experiments demonstrate that SemanticGen produces high-quality videos and outperforms state-of-the-art approaches and strong baselines.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
KlingAvatar 2.0 Technical Report
Dec 15, 2025Avatar video generation models have achieved remarkable progress in recent years. However, prior work exhibits limited efficiency in generating long-duration high-resolution videos, suffering from temporal drifting, quality degradation, and weak prompt following as video length increases. To address these challenges, we propose KlingAvatar 2.0, a spatio-temporal cascade framework that performs upscaling in both spatial resolution and temporal dimension. The framework first generates low-resolution blueprint video keyframes that capture global semantics and motion, and then refines them into high-resolution, temporally coherent sub-clips using a first-last frame strategy, while retaining smooth temporal transitions in long-form videos. To enhance cross-modal instruction fusion and alignment in extended videos, we introduce a Co-Reasoning Director composed of three modality-specific large language model (LLM) experts. These experts reason about modality priorities and infer underlying user intent, converting inputs into detailed storylines through multi-turn dialogue. A Negative Director further refines negative prompts to improve instruction alignment. Building on these components, we extend the framework to support ID-specific multi-character control. Extensive experiments demonstrate that our model effectively addresses the challenges of efficient, multimodally aligned long-form high-resolution video generation, delivering enhanced visual clarity, realistic lip-teeth rendering with accurate lip synchronization, strong identity preservation, and coherent multimodal instruction following.