 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-I2V: Consistent and Controllable Image-to-Video Generation with Explicit Motion Modeling
Jan 31, 2024



We introduce Motion-I2V, a novel framework for consistent and controllable image-to-video generation (I2V). In contrast to previous methods that directly learn the complicated image-to-video mapping, Motion-I2V factorizes I2V into two stages with explicit motion modeling. For the first stage, we propose a diffusion-based motion field predictor, which focuses on deducing the trajectories of the reference image's pixels. For the second stage, we propose motion-augmented temporal attention to enhance the limited 1-D temporal attention in video latent diffusion models. This module can effectively propagate reference image's feature to synthesized frames with the guidance of predicted trajectories from the first stage. Compared with existing methods, Motion-I2V can generate more consistent videos even at the presence of large motion and viewpoint variation. By training a sparse trajectory ControlNet for the first stage, Motion-I2V can support users to precisely control motion trajectories and motion regions with sparse trajectory and region annotations. This offers more controllability of the I2V process than solely relying on textual instructions. Additionally, Motion-I2V's second stage naturally supports zero-shot video-to-video translation. Both qualitative and quantitative comparisons demonstrate the advantages of Motion-I2V over prior approaches in consistent and controllable image-to-video generation. Please see our project page at https://xiaoyushi97.github.io/Motion-I2V/.
A Unified Conditional Framework for Diffusion-based Image Restoration
May 31, 2023



Diffusion Probabilistic Models (DPMs) have recently shown remarkable performance in image generation tasks, which are capable of generating highly realistic images. When adopting DPMs for image restoration tasks, the crucial aspect lies in how to integrate the conditional information to guide the DPMs to generate accurate and natural output, which has been largely overlooked in existing works. In this paper, we present a unified conditional framework based on diffusion models for image restoration. We leverage a lightweight UNet to predict initial guidance and the diffusion model to learn the residual of the guidance. By carefully designing the basic module and integration module for the diffusion model block, we integrate the guidance and other auxiliary conditional information into every block of the diffusion model to achieve spatially-adaptive generation conditioning. To handle high-resolution images, we propose a simple yet effective inter-step patch-splitting strategy to produce arbitrary-resolution images without grid artifacts. We evaluate our conditional framework on three challenging tasks: extreme low-light denoising, deblurring, and JPEG restoration, demonstrating its significant improvements in perceptual quality and the generalization to restoration tasks.
VideoFlow: Exploiting Temporal Cues for Multi-frame Optical Flow Estimation
Mar 17, 2023



We introduce VideoFlow, a novel optical flow estimation framework for videos. In contrast to previous methods that learn to estimate optical flow from two frames, VideoFlow concurrently estimates bi-directional optical flows for multiple frames that are available in videos by sufficiently exploiting temporal cues. We first propose a TRi-frame Optical Flow (TROF) module that estimates bi-directional optical flows for the center frame in a three-frame manner. The information of the frame triplet is iteratively fused onto the center frame. To extend TROF for handling more frames, we further propose a MOtion Propagation (MOP) module that bridges multiple TROFs and propagates motion features between adjacent TROFs. With the iterative flow estimation refinement, the information fused in individual TROFs can be propagated into the whole sequence via MOP. By effectively exploiting video information, VideoFlow presents extraordinary performance, ranking 1st on all public benchmarks. On the Sintel benchmark, VideoFlow achieves 1.649 and 0.991 average end-point-error (AEPE) on the final and clean passes, a 15.1% and 7.6% error reduction from the best published results (1.943 and 1.073 from FlowFormer++). On the KITTI-2015 benchmark, VideoFlow achieves an F1-all error of 3.65%, a 19.2% error reduction from the best published result (4.52% from FlowFormer++).
KBNet: Kernel Basis Network for Image Restoration
Mar 06, 2023How to aggregate spatial information plays an essential role in learning-based image restoration. Most existing CNN-based networks adopt static convolutional kernels to encode spatial information, which cannot aggregate spatial information adaptively. Recent transformer-based architectures achieve adaptive spatial aggregation. But they lack desirable inductive biases of convolutions and require heavy computational costs. In this paper, we propose a kernel basis attention (KBA) module, which introduces learnable kernel bases to model representative image patterns for spatial information aggregation. Different kernel bases are trained to model different local structures. At each spatial location, they are linearly and adaptively fused by predicted pixel-wise coefficients to obtain aggregation weights. Based on the KBA module, we further design a multi-axis feature fusion (MFF) block to encode and fuse channel-wise, spatial-invariant, and pixel-adaptive features for image restoration. Our model, named kernel basis network (KBNet), achieves state-of-the-art performances on more than ten benchmarks over image denoising, deraining, and deblurring tasks while requiring less computational cost than previous SOTA methods.
FlowFormer++: Masked Cost Volume Autoencoding for Pretraining Optical Flow Estimation
Mar 02, 2023FlowFormer introduces a transformer architecture into optical flow estimation and achieves state-of-the-art performance. The core component of FlowFormer is the transformer-based cost-volume encoder. Inspired by the recent success of masked autoencoding (MAE) pretraining in unleashing transformers' capacity of encoding visual representation, we propose Masked Cost Volume Autoencoding (MCVA) to enhance FlowFormer by pretraining the cost-volume encoder with a novel MAE scheme. Firstly, we introduce a block-sharing masking strategy to prevent masked information leakage, as the cost maps of neighboring source pixels are highly correlated. Secondly, we propose a novel pre-text reconstruction task, which encourages the cost-volume encoder to aggregate long-range information and ensures pretraining-finetuning consistency. We also show how to modify the FlowFormer architecture to accommodate masks during pretraining. Pretrained with MCVA, FlowFormer++ ranks 1st among published methods on both Sintel and KITTI-2015 benchmarks. Specifically, FlowFormer++ achieves 1.07 and 1.94 average end-point error (AEPE) on the clean and final pass of Sintel benchmark, leading to 7.76\% and 7.18\% error reductions from FlowFormer. FlowFormer++ obtains 4.52 F1-all on the KITTI-2015 test set, improving FlowFormer by 0.16.
Learning Degradation Representations for Image Deblurring
Aug 10, 2022



In various learning-based image restoration tasks, such as image denoising and image super-resolution, the degradation representations were widely used to model the degradation process and handle complicated degradation patterns. However, they are less explored in learning-based image deblurring as blur kernel estimation cannot perform well in real-world challenging cases. We argue that it is particularly necessary for image deblurring to model degradation representations since blurry patterns typically show much larger variations than noisy patterns or high-frequency textures.In this paper, we propose a framework to learn spatially adaptive degradation representations of blurry images. A novel joint image reblurring and deblurring learning process is presented to improve the expressiveness of degradation representations. To make learned degradation representations effective in reblurring and deblurring, we propose a Multi-Scale Degradation Injection Network (MSDI-Net) to integrate them into the neural networks. With the integration, MSDI-Net can handle various and complicated blurry patterns adaptively. Experiments on the GoPro and RealBlur datasets demonstrate that our proposed deblurring framework with the learned degradation representations outperforms state-of-the-art methods with appealing improvements. The code is released at https://github.com/dasongli1/Learning_degradation.
* Accepted to ECCV 2022
No Attention is Needed: Grouped Spatial-temporal Shift for Simple and Efficient Video Restorers
Jun 22, 2022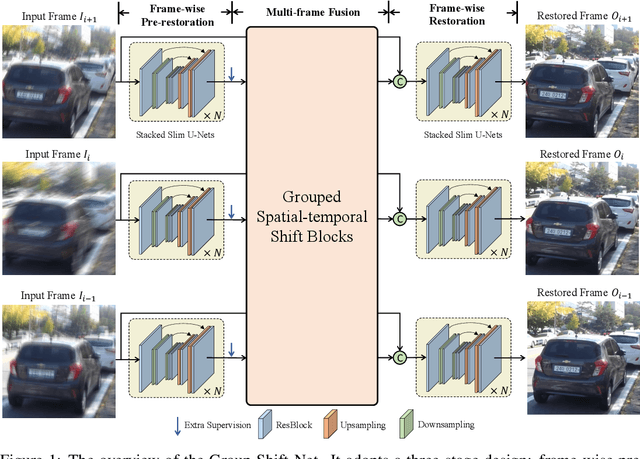

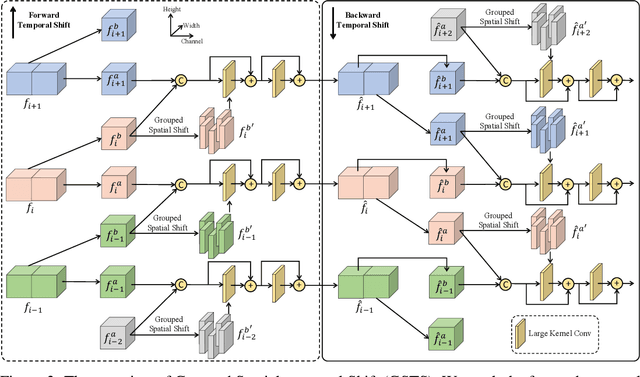
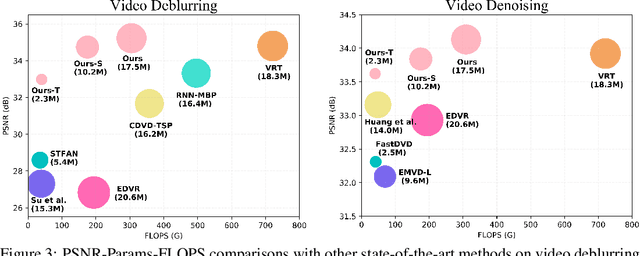
Video restoration, aiming at restoring clear frames from degraded videos, has been attracting increasing attention. Video restoration is required to establish the temporal correspondences from multiple misaligned frames. To achieve that end, existing deep methods generally adopt complicated network architectures, such as integrating optical flow, deformable convolution, cross-frame or cross-pixel self-attention layers, resulting in expensive computational cost. We argue that with proper design, temporal information utilization in video restoration can be much more efficient and effective. In this study, we propose a simple, fast yet effective framework for video restoration. The key of our framework is the grouped spatial-temporal shift, which is simple and lightweight, but can implicitly establish inter-frame correspondences and achieve multi-frame aggregation. Coupled with basic 2D U-Nets for frame-wise encoding and decoding, such an efficient spatial-temporal shift module can effectively tackle the challenges in video restoration. Extensive experiments show that our framework surpasses previous state-of-the-art method with 43% of its computational cost on both video deblurring and video denoising.
Efficient Burst Raw Denoising with Variance Stabilization and Multi-frequency Denoising Network
May 10, 2022
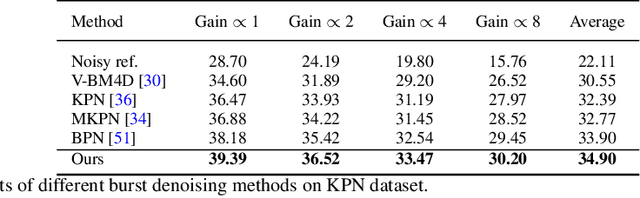
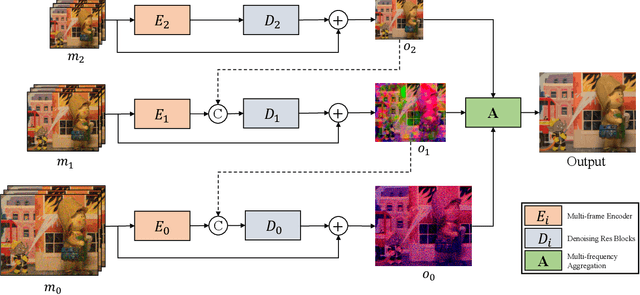

With the growing popularity of smartphones, capturing high-quality images is of vital importance to smartphones. The cameras of smartphones have small apertures and small sensor cells, which lead to the noisy images in low light environment. Denoising based on a burst of multiple frames generally outperforms single frame denoising but with the larger compututional cost. In this paper, we propose an efficient yet effective burst denoising system. We adopt a three-stage design: noise prior integration, multi-frame alignment and multi-frame denoising. First, we integrate noise prior by pre-processing raw signals into a variance-stabilization space, which allows using a small-scale network to achieve competitive performance. Second, we observe that it is essential to adopt an explicit alignment for burst denoising, but it is not necessary to integrate a learning-based method to perform multi-frame alignment. Instead, we resort to a conventional and efficient alignment method and combine it with our multi-frame denoising network. At last, we propose a denoising strategy that processes multiple frames sequentially. Sequential denoising avoids filtering a large number of frames by decomposing multiple frames denoising into several efficient sub-network denoising. As for each sub-network, we propose an efficient multi-frequency denoising network to remove noise of different frequencies. Our three-stage design is efficient and shows strong performance on burst denoising. Experiments on synthetic and real raw datasets demonstrate that our method outperforms state-of-the-art methods, with less computational cost. Furthermore, the low complexity and high-quality performance make deployment on smartphones possible.
IDR: Self-Supervised Image Denoising via Iterative Data Refinement
Nov 29, 2021

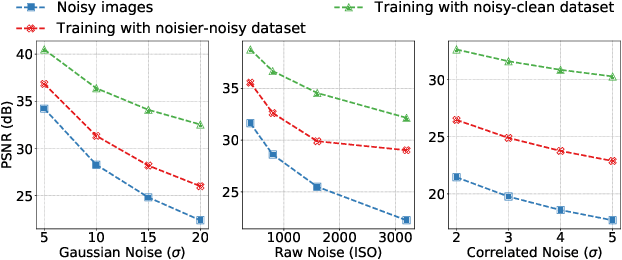
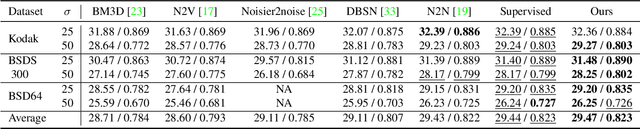
The lack of large-scale noisy-clean image pairs restricts supervised denoising methods' deployment in actual applications. While existing unsupervised methods are able to learn image denoising without ground-truth clean images, they either show poor performance or work under impractical settings (e.g., paired noisy images). In this paper, we present a practical unsupervised image denoising method to achieve state-of-the-art denoising performance. Our method only requires single noisy images and a noise model, which is easily accessible in practical raw image denoising. It performs two steps iteratively: (1) Constructing a noisier-noisy dataset with random noise from the noise model; (2) training a model on the noisier-noisy dataset and using the trained model to refine noisy images to obtain the targets used in the next round. We further approximate our full iterative method with a fast algorithm for more efficient training while keeping its original high performance. Experiments on real-world, synthetic, and correlated noise show that our proposed unsupervised denoising approach has superior performances over existing unsupervised methods and competitive performance with supervised methods. In addition, we argue that existing denoising datasets are of low quality and contain only a small number of scenes. To evaluate raw image denoising performance in real-world applications, we build a high-quality raw image dataset SenseNoise-500 that contains 500 real-life scenes. The dataset can serve as a strong benchmark for better evaluating raw image denoising. Code and dataset will be released at https://github.com/zhangyi-3/IDR
Image Semantic Transformation: Faster, Lighter and Stronger
Mar 27, 2018


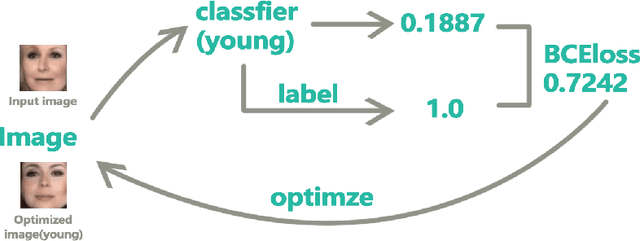
We propose Image-Semantic-Transformation-Reconstruction-Circle(ISTRC) model, a novel and powerful method using facenet's Euclidean latent space to understand the images. As the name suggests, ISTRC construct the circle, able to perfectly reconstruct images. One powerful Euclidean latent space embedded in ISTRC is FaceNet's last layer with the power of distinguishing and understanding images. Our model will reconstruct the images and manipulate Euclidean latent vectors to achieve semantic transformations and semantic images arthimetic calculations. In this paper, we show that ISTRC performs 10 high-level semantic transformations like "Male and female","add smile","open mouth", "deduct beard or add mustache", "bigger/smaller nose", "make older and younger", "bigger lips", "bigger eyes", "bigger/smaller mouths" and "more attractive". It just takes 3 hours(GTX 1080) to train the models of 10 semantic transformations.