 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Brake? Ethical Emergency Braking with Deep Reinforcement Learning
Dec 11, 2025Connected and automated vehicles (CAVs) have the potential to enhance driving safety, for example by enabling safe vehicle following and more efficient traffic scheduling. For such future deployments, safety requirements should be addressed, where the primary such are avoidance of vehicle collisions and substantial mitigating of harm when collisions are unavoidable. However, conservative worst-case-based control strategies come at the price of reduced flexibility and may compromise overall performance. In light of this, we investigate how Deep Reinforcement Learning (DRL) can be leveraged to improve safety in multi-vehicle-following scenarios involving emergency braking. Specifically, we investigate how DRL with vehicle-to-vehicle communication can be used to ethically select an emergency breaking profile in scenarios where overall, or collective, three-vehicle harm reduction or collision avoidance shall be obtained instead of single-vehicle such. As an algorithm, we provide a hybrid approach that combines DRL with a previously published method based on analytical expressions for selecting optimal constant deceleration. By combining DRL with the previous method, the proposed hybrid approach increases the reliability compared to standalone DRL, while achieving superior performance in terms of overall harm reduction and collision avoidance.
ReCellTy: Domain-specific knowledge graph retrieval-augmented LLMs workflow for single-cell annotation
Apr 24, 2025To enable precise and fully automated cell type annotation with large language models (LLMs), we developed a graph structured feature marker database to retrieve entities linked to differential genes for cell reconstruction. We further designed a multi task workflow to optimize the annotation process. Compared to general purpose LLMs, our method improves human evaluation scores by up to 0.21 and semantic similarity by 6.1% across 11 tissue types, while more closely aligning with the cognitive logic of manual annotation.
Fine-Grained Image Style Transfer with Visual Transformers
Oct 11, 2022
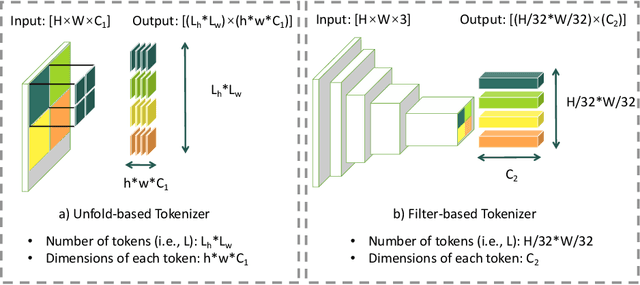

With the development of the convolutional neural network, image style transfer has drawn increasing attention. However, most existing approaches adopt a global feature transformation to transfer style patterns into content images (e.g., AdaIN and WCT). Such a design usually destroys the spatial information of the input images and fails to transfer fine-grained style patterns into style transfer results. To solve this problem, we propose a novel STyle TRansformer (STTR) network which breaks both content and style images into visual tokens to achieve a fine-grained style transformation. Specifically, two attention mechanisms are adopted in our STTR. We first propose to use self-attention to encode content and style tokens such that similar tokens can be grouped and learned together. We then adopt cross-attention between content and style tokens that encourages fine-grained style transformations. To compare STTR with existing approaches, we conduct user studies on Amazon Mechanical Turk (AMT), which are carried out with 50 human subjects with 1,000 votes in total. Extensive evaluations demonstrate the effectiveness and efficiency of the proposed STTR in generating visually pleasing style transfer results.
Improving Visual Quality of Image Synthesis by A Token-based Generator with Transformers
Nov 05, 2021
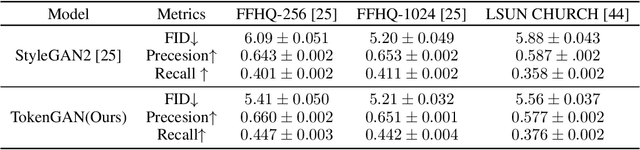


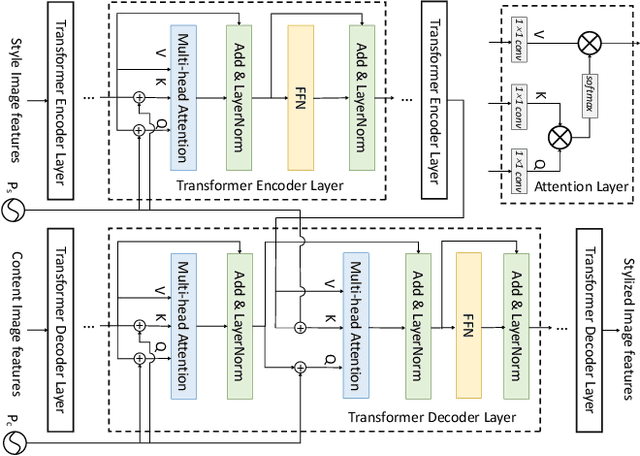
We present a new perspective of achieving image synthesis by viewing this task as a visual token generation problem. Different from existing paradigms that directly synthesize a full image from a single input (e.g., a latent code), the new formulation enables a flexible local manipulation for different image regions, which makes it possible to learn content-aware and fine-grained style control for image synthesis. Specifically, it takes as input a sequence of latent tokens to predict the visual tokens for synthesizing an image. Under this perspective, we propose a token-based generator (i.e.,TokenGAN). Particularly, the TokenGAN inputs two semantically different visual tokens, i.e., the learned constant content tokens and the style tokens from the latent space. Given a sequence of style tokens, the TokenGAN is able to control the image synthesis by assigning the styles to the content tokens by attention mechanism with a Transformer. We conduct extensive experiments and show that the proposed TokenGAN has achieved state-of-the-art results on several widely-used image synthesis benchmarks, including FFHQ and LSUN CHURCH with different resolutions. In particular, the generator is able to synthesize high-fidelity images with 1024x1024 size, dispensing with convolutions entirely.
Image Semantic Transformation: Faster, Lighter and Stronger
Mar 27, 2018


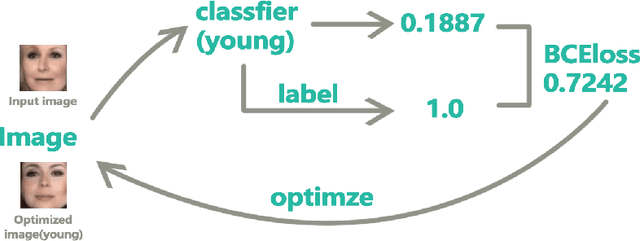
We propose Image-Semantic-Transformation-Reconstruction-Circle(ISTRC) model, a novel and powerful method using facenet's Euclidean latent space to understand the images. As the name suggests, ISTRC construct the circle, able to perfectly reconstruct images. One powerful Euclidean latent space embedded in ISTRC is FaceNet's last layer with the power of distinguishing and understanding images. Our model will reconstruct the images and manipulate Euclidean latent vectors to achieve semantic transformations and semantic images arthimetic calculations. In this paper, we show that ISTRC performs 10 high-level semantic transformations like "Male and female","add smile","open mouth", "deduct beard or add mustache", "bigger/smaller nose", "make older and younger", "bigger lips", "bigger eyes", "bigger/smaller mouths" and "more attractive". It just takes 3 hours(GTX 1080) to train the models of 10 semantic transformations.