 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing Text-to-Image Diffusion Prior for Zero-Shot Image Captioning
Dec 31, 2024Recently, zero-shot image captioning has gained increasing attention, where only text data is available for training. The remarkable progress in text-to-image diffusion model presents the potential to resolve this task by employing synthetic image-caption pairs generated by this pre-trained prior. Nonetheless, the defective details in the salient regions of the synthetic images introduce semantic misalignment between the synthetic image and text, leading to compromised results. To address this challenge, we propose a novel Patch-wise Cross-modal feature Mix-up (PCM) mechanism to adaptively mitigate the unfaithful contents in a fine-grained manner during training, which can be integrated into most of encoder-decoder frameworks, introducing our PCM-Net. Specifically, for each input image, salient visual concepts in the image are first detected considering the image-text similarity in CLIP space. Next, the patch-wise visual features of the input image are selectively fused with the textual features of the salient visual concepts, leading to a mixed-up feature map with less defective content. Finally, a visual-semantic encoder is exploited to refine the derived feature map, which is further incorporated into the sentence decoder for caption generation. Additionally, to facilitate the model training with synthetic data, a novel CLIP-weighted cross-entropy loss is devised to prioritize the high-quality image-text pairs over the low-quality counterparts. Extensive experiments on MSCOCO and Flickr30k datasets demonstrate the superiority of our PCM-Net compared with state-of-the-art VLMs-based approaches. It is noteworthy that our PCM-Net ranks first in both in-domain and cross-domain zero-shot image captioning. The synthetic dataset SynthImgCap and code are available at https://jianjieluo.github.io/SynthImgCap.
Improving Multi-Subject Consistency in Open-Domain Image Generation with Isolation and Reposition Attention
Nov 28, 2024



Training-free diffusion models have achieved remarkable progress in generating multi-subject consistent images within open-domain scenarios. The key idea of these methods is to incorporate reference subject information within the attention layer. However, existing methods still obtain suboptimal performance when handling numerous subjects. This paper reveals the two primary issues contributing to this deficiency. Firstly, there is undesired interference among different subjects within the target image. Secondly, tokens tend to reference nearby tokens, which reduces the effectiveness of the attention mechanism when there is a significant positional difference between subjects in reference and target images. To address these challenges, we propose a training-free diffusion model with Isolation and Reposition Attention, named IR-Diffusion. Specifically, Isolation Attention ensures that multiple subjects in the target image do not reference each other, effectively eliminating the subject fusion. On the other hand, Reposition Attention involves scaling and repositioning subjects in both reference and target images to the same position within the images. This ensures that subjects in the target image can better reference those in the reference image, thereby maintaining better consistency. Extensive experiments demonstrate that the proposed methods significantly enhance multi-subject consistency, outperforming all existing methods in open-domain scenarios.
DreamStory: Open-Domain Story Visualization by LLM-Guided Multi-Subject Consistent Diffusion
Jul 17, 2024
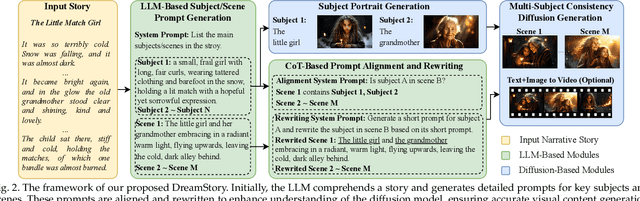
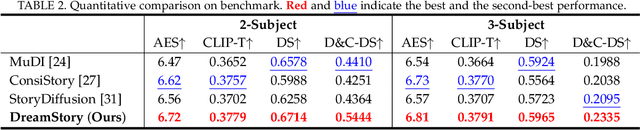
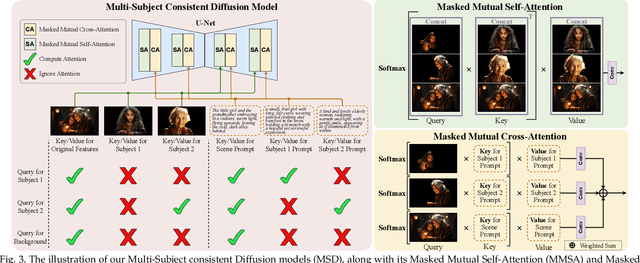
Story visualization aims to create visually compelling images or videos corresponding to textual narratives. Despite recent advances in diffusion models yielding promising results, existing methods still struggle to create a coherent sequence of subject-consistent frames based solely on a story. To this end, we propose DreamStory, an automatic open-domain story visualization framework by leveraging the LLMs and a novel multi-subject consistent diffusion model. DreamStory consists of (1) an LLM acting as a story director and (2) an innovative Multi-Subject consistent Diffusion model (MSD) for generating consistent multi-subject across the images. First, DreamStory employs the LLM to generate descriptive prompts for subjects and scenes aligned with the story, annotating each scene's subjects for subsequent subject-consistent generation. Second, DreamStory utilizes these detailed subject descriptions to create portraits of the subjects, with these portraits and their corresponding textual information serving as multimodal anchors (guidance). Finally, the MSD uses these multimodal anchors to generate story scenes with consistent multi-subject. Specifically, the MSD includes Masked Mutual Self-Attention (MMSA) and Masked Mutual Cross-Attention (MMCA) modules. MMSA and MMCA modules ensure appearance and semantic consistency with reference images and text, respectively. Both modules employ masking mechanisms to prevent subject blending. To validate our approach and promote progress in story visualization, we established a benchmark, DS-500, which can assess the overall performance of the story visualization framework, subject-identification accuracy, and the consistency of the generation model. Extensive experiments validate the effectiveness of DreamStory in both subjective and objective evaluations. Please visit our project homepage at https://dream-xyz.github.io/dreamstory.
TinyCLIP: CLIP Distillation via Affinity Mimicking and Weight Inheritance
Sep 21, 2023In this paper, we propose a novel cross-modal distillation method, called TinyCLIP, for large-scale language-image pre-trained models. The method introduces two core techniques: affinity mimicking and weight inheritance. Affinity mimicking explores the interaction between modalities during distillation, enabling student models to mimic teachers' behavior of learning cross-modal feature alignment in a visual-linguistic affinity space. Weight inheritance transmits the pre-trained weights from the teacher models to their student counterparts to improve distillation efficiency. Moreover, we extend the method into a multi-stage progressive distillation to mitigate the loss of informative weights during extreme compression. Comprehensive experiments demonstrate the efficacy of TinyCLIP, showing that it can reduce the size of the pre-trained CLIP ViT-B/32 by 50%, while maintaining comparable zero-shot performance. While aiming for comparable performance, distillation with weight inheritance can speed up the training by 1.4 - 7.8 $\times$ compared to training from scratch. Moreover, our TinyCLIP ViT-8M/16, trained on YFCC-15M, achieves an impressive zero-shot top-1 accuracy of 41.1% on ImageNet, surpassing the original CLIP ViT-B/16 by 3.5% while utilizing only 8.9% parameters. Finally, we demonstrate the good transferability of TinyCLIP in various downstream tasks. Code and models will be open-sourced at https://aka.ms/tinyclip.
Learning Profitable NFT Image Diffusions via Multiple Visual-Policy Guided Reinforcement Learning
Jun 20, 2023



We study the task of generating profitable Non-Fungible Token (NFT) images from user-input texts. Recent advances in diffusion models have shown great potential for image generation. However, existing works can fall short in generating visually-pleasing and highly-profitable NFT images, mainly due to the lack of 1) plentiful and fine-grained visual attribute prompts for an NFT image, and 2) effective optimization metrics for generating high-quality NFT images. To solve these challenges, we propose a Diffusion-based generation framework with Multiple Visual-Policies as rewards (i.e., Diffusion-MVP) for NFT images. The proposed framework consists of a large language model (LLM), a diffusion-based image generator, and a series of visual rewards by design. First, the LLM enhances a basic human input (such as "panda") by generating more comprehensive NFT-style prompts that include specific visual attributes, such as "panda with Ninja style and green background." Second, the diffusion-based image generator is fine-tuned using a large-scale NFT dataset to capture fine-grained image styles and accessory compositions of popular NFT elements. Third, we further propose to utilize multiple visual-policies as optimization goals, including visual rarity levels, visual aesthetic scores, and CLIP-based text-image relevances. This design ensures that our proposed Diffusion-MVP is capable of minting NFT images with high visual quality and market value. To facilitate this research, we have collected the largest publicly available NFT image dataset to date, consisting of 1.5 million high-quality images with corresponding texts and market values. Extensive experiments including objective evaluations and user studies demonstrate that our framework can generate NFT images showing more visually engaging elements and higher market value, compared with SOTA approaches.
Semantic-Conditional Diffusion Networks for Image Captioning
Dec 06, 2022Recent advances on text-to-image generation have witnessed the rise of diffusion models which act as powerful generative models. Nevertheless, it is not trivial to exploit such latent variable models to capture the dependency among discrete words and meanwhile pursue complex visual-language alignment in image captioning. In this paper, we break the deeply rooted conventions in learning Transformer-based encoder-decoder, and propose a new diffusion model based paradigm tailored for image captioning, namely Semantic-Conditional Diffusion Networks (SCD-Net). Technically, for each input image, we first search the semantically relevant sentences via cross-modal retrieval model to convey the comprehensive semantic information. The rich semantics are further regarded as semantic prior to trigger the learning of Diffusion Transformer, which produces the output sentence in a diffusion process. In SCD-Net, multiple Diffusion Transformer structures are stacked to progressively strengthen the output sentence with better visional-language alignment and linguistical coherence in a cascaded manner. Furthermore, to stabilize the diffusion process, a new self-critical sequence training strategy is designed to guide the learning of SCD-Net with the knowledge of a standard autoregressive Transformer model. Extensive experiments on COCO dataset demonstrate the promising potential of using diffusion models in the challenging image captioning task. Source code is available at \url{https://github.com/YehLi/xmodaler/tree/master/configs/image_caption/scdnet}.
Out-of-Distribution Detection with Hilbert-Schmidt Independence Optimization
Sep 26, 2022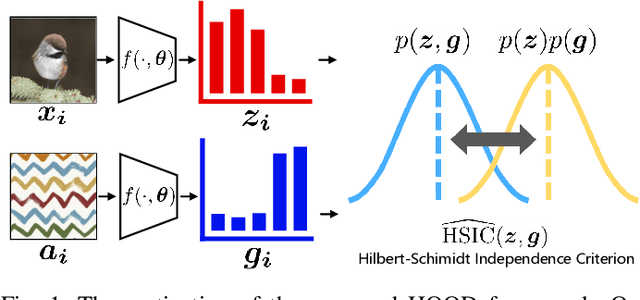
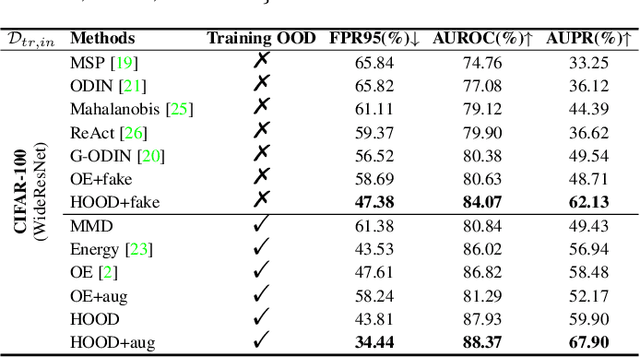
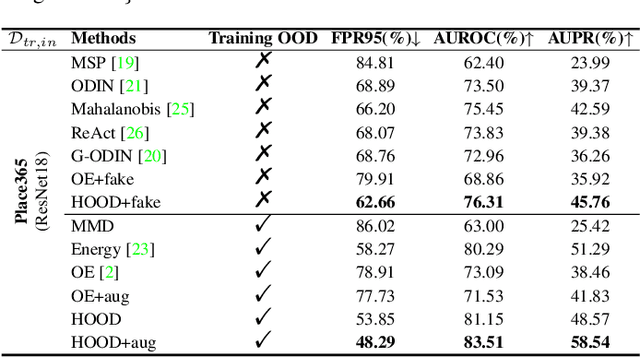
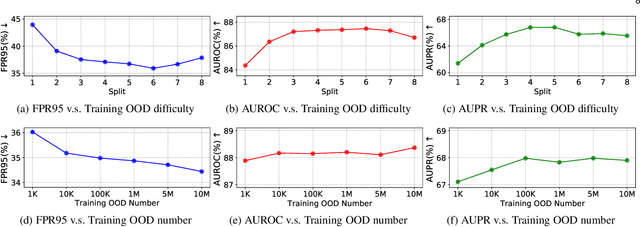
Outlier detection tasks have been playing a critical role in AI safety. There has been a great challenge to deal with this task. Observations show that deep neural network classifiers usually tend to incorrectly classify out-of-distribution (OOD) inputs into in-distribution classes with high confidence. Existing works attempt to solve the problem by explicitly imposing uncertainty on classifiers when OOD inputs are exposed to the classifier during training. In this paper, we propose an alternative probabilistic paradigm that is both practically useful and theoretically viable for the OOD detection tasks. Particularly, we impose statistical independence between inlier and outlier data during training, in order to ensure that inlier data reveals little information about OOD data to the deep estimator during training. Specifically, we estimate the statistical dependence between inlier and outlier data through the Hilbert-Schmidt Independence Criterion (HSIC), and we penalize such metric during training. We also associate our approach with a novel statistical test during the inference time coupled with our principled motivation. Empirical results show that our method is effective and robust for OOD detection on various benchmarks. In comparison to SOTA models, our approach achieves significant improvement regarding FPR95, AUROC, and AUPR metrics. Code is available: \url{https://github.com/jylins/hood}.
CoCo-BERT: Improving Video-Language Pre-training with Contrastive Cross-modal Matching and Denoising
Dec 14, 2021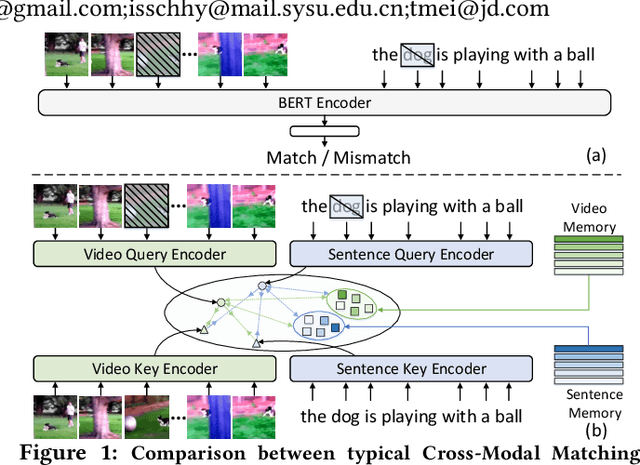
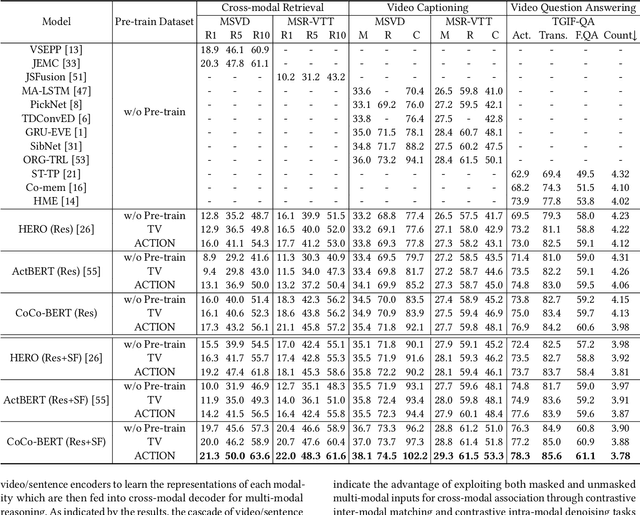
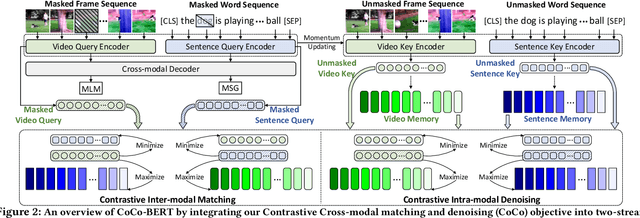
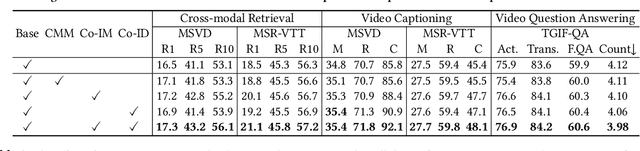
BERT-type structure has led to the revolution of vision-language pre-training and the achievement of state-of-the-art results on numerous vision-language downstream tasks. Existing solutions dominantly capitalize on the multi-modal inputs with mask tokens to trigger mask-based proxy pre-training tasks (e.g., masked language modeling and masked object/frame prediction). In this work, we argue that such masked inputs would inevitably introduce noise for cross-modal matching proxy task, and thus leave the inherent vision-language association under-explored. As an alternative, we derive a particular form of cross-modal proxy objective for video-language pre-training, i.e., Contrastive Cross-modal matching and denoising (CoCo). By viewing the masked frame/word sequences as the noisy augmentation of primary unmasked ones, CoCo strengthens video-language association by simultaneously pursuing inter-modal matching and intra-modal denoising between masked and unmasked inputs in a contrastive manner. Our CoCo proxy objective can be further integrated into any BERT-type encoder-decoder structure for video-language pre-training, named as Contrastive Cross-modal BERT (CoCo-BERT). We pre-train CoCo-BERT on TV dataset and a newly collected large-scale GIF video dataset (ACTION). Through extensive experiments over a wide range of downstream tasks (e.g., cross-modal retrieval, video question answering, and video captioning), we demonstrate the superiority of CoCo-BERT as a pre-trained structure.
CORE-Text: Improving Scene Text Detection with Contrastive Relational Reasoning
Dec 14, 2021
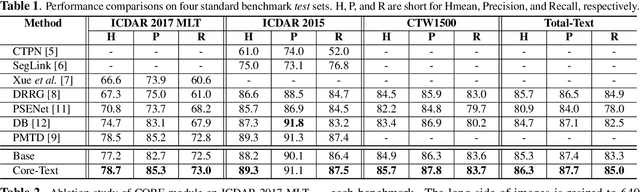
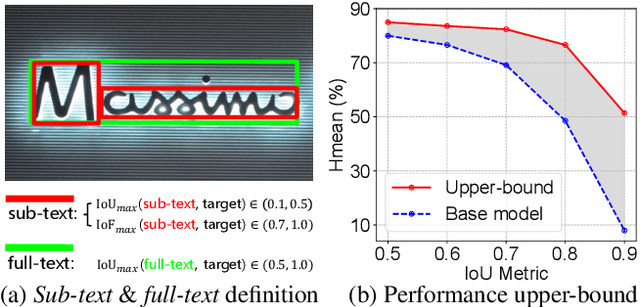
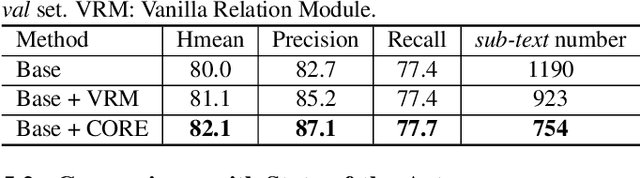
Localizing text instances in natural scenes is regarded as a fundamental challenge in computer vision. Nevertheless, owing to the extremely varied aspect ratios and scales of text instances in real scenes, most conventional text detectors suffer from the sub-text problem that only localizes the fragments of text instance (i.e., sub-texts). In this work, we quantitatively analyze the sub-text problem and present a simple yet effective design, COntrastive RElation (CORE) module, to mitigate that issue. CORE first leverages a vanilla relation block to model the relations among all text proposals (sub-texts of multiple text instances) and further enhances relational reasoning via instance-level sub-text discrimination in a contrastive manner. Such way naturally learns instance-aware representations of text proposals and thus facilitates scene text detection. We integrate the CORE module into a two-stage text detector of Mask R-CNN and devise our text detector CORE-Text. Extensive experiments on four benchmarks demonstrate the superiority of CORE-Text. Code is available: \url{https://github.com/jylins/CORE-Text}.
Searching the Search Space of Vision Transformer
Nov 29, 2021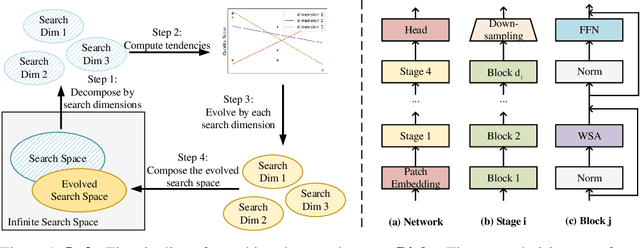
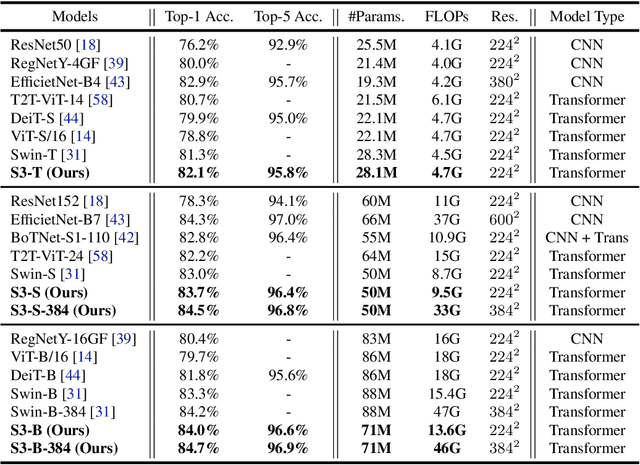
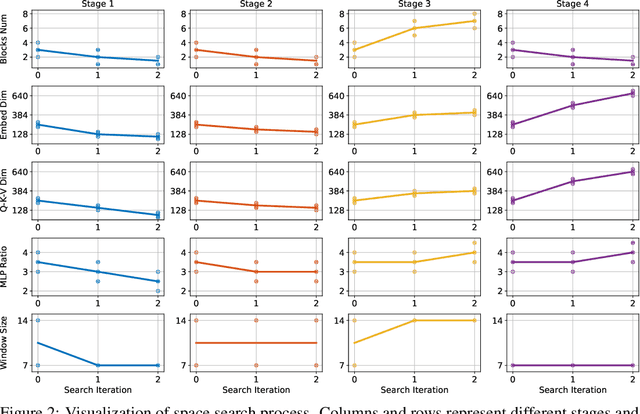
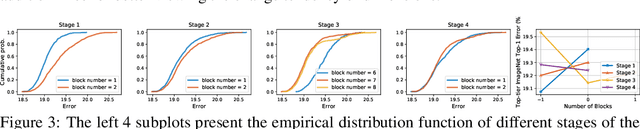
Vision Transformer has shown great visual representation power in substantial vision tasks such as recognition and detection, and thus been attracting fast-growing efforts on manually designing more effective architectures. In this paper, we propose to use neural architecture search to automate this process, by searching not only the architecture but also the search space. The central idea is to gradually evolve different search dimensions guided by their E-T Error computed using a weight-sharing supernet. Moreover, we provide design guidelines of general vision transformers with extensive analysis according to the space searching process, which could promote the understanding of vision transformer. Remarkably, the searched models, named S3 (short for Searching the Search Space), from the searched space achieve superior performance to recently proposed models, such as Swin, DeiT and ViT, when evaluated on ImageNet. The effectiveness of S3 is also illustrated on object detection, semantic segmentation and visual question answering, demonstrating its generality to downstream vision and vision-language tasks. Code and models will be available at https://github.com/microsoft/Cream.