 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextDrag: Precise Drag-Based Image Editing via Context-Preserving Token Injection and Position-Consistent Attention
Dec 09, 2025Drag-based image editing aims to modify visual content followed by user-specified drag operations. Despite existing methods having made notable progress, they still fail to fully exploit the contextual information in the reference image, including fine-grained texture details, leading to edits with limited coherence and fidelity. To address this challenge, we introduce ContextDrag, a new paradigm for drag-based editing that leverages the strong contextual modeling capability of editing models, such as FLUX-Kontext. By incorporating VAE-encoded features from the reference image, ContextDrag can leverage rich contextual cues and preserve fine-grained details, without the need for finetuning or inversion. Specifically, ContextDrag introduced a novel Context-preserving Token Injection (CTI) that injects noise-free reference features into their correct destination locations via a Latent-space Reverse Mapping (LRM) algorithm. This strategy enables precise drag control while preserving consistency in both semantics and texture details. Second, ContextDrag adopts a novel Position-Consistent Attention (PCA), which positional re-encodes the reference tokens and applies overlap-aware masking to eliminate interference from irrelevant reference features. Extensive experiments on DragBench-SR and DragBench-DR demonstrate that our approach surpasses all existing SOTA methods. Code will be publicly available.
Mod-Adapter: Tuning-Free and Versatile Multi-concept Personalization via Modulation Adapter
May 24, 2025Personalized text-to-image generation aims to synthesize images of user-provided concepts in diverse contexts. Despite recent progress in multi-concept personalization, most are limited to object concepts and struggle to customize abstract concepts (e.g., pose, lighting). Some methods have begun exploring multi-concept personalization supporting abstract concepts, but they require test-time fine-tuning for each new concept, which is time-consuming and prone to overfitting on limited training images. In this work, we propose a novel tuning-free method for multi-concept personalization that can effectively customize both object and abstract concepts without test-time fine-tuning. Our method builds upon the modulation mechanism in pretrained Diffusion Transformers (DiTs) model, leveraging the localized and semantically meaningful properties of the modulation space. Specifically, we propose a novel module, Mod-Adapter, to predict concept-specific modulation direction for the modulation process of concept-related text tokens. It incorporates vision-language cross-attention for extracting concept visual features, and Mixture-of-Experts (MoE) layers that adaptively map the concept features into the modulation space. Furthermore, to mitigate the training difficulty caused by the large gap between the concept image space and the modulation space, we introduce a VLM-guided pretraining strategy that leverages the strong image understanding capabilities of vision-language models to provide semantic supervision signals. For a comprehensive comparison, we extend a standard benchmark by incorporating abstract concepts. Our method achieves state-of-the-art performance in multi-concept personalization, supported by quantitative, qualitative, and human evaluations.
Improving Multi-Subject Consistency in Open-Domain Image Generation with Isolation and Reposition Attention
Nov 28, 2024



Training-free diffusion models have achieved remarkable progress in generating multi-subject consistent images within open-domain scenarios. The key idea of these methods is to incorporate reference subject information within the attention layer. However, existing methods still obtain suboptimal performance when handling numerous subjects. This paper reveals the two primary issues contributing to this deficiency. Firstly, there is undesired interference among different subjects within the target image. Secondly, tokens tend to reference nearby tokens, which reduces the effectiveness of the attention mechanism when there is a significant positional difference between subjects in reference and target images. To address these challenges, we propose a training-free diffusion model with Isolation and Reposition Attention, named IR-Diffusion. Specifically, Isolation Attention ensures that multiple subjects in the target image do not reference each other, effectively eliminating the subject fusion. On the other hand, Reposition Attention involves scaling and repositioning subjects in both reference and target images to the same position within the images. This ensures that subjects in the target image can better reference those in the reference image, thereby maintaining better consistency. Extensive experiments demonstrate that the proposed methods significantly enhance multi-subject consistency, outperforming all existing methods in open-domain scenarios.
DreamStory: Open-Domain Story Visualization by LLM-Guided Multi-Subject Consistent Diffusion
Jul 17, 2024
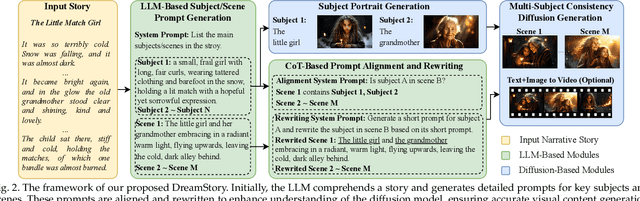
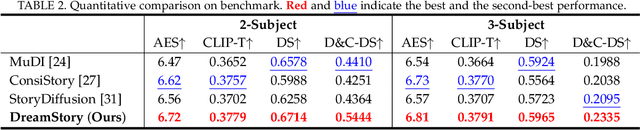
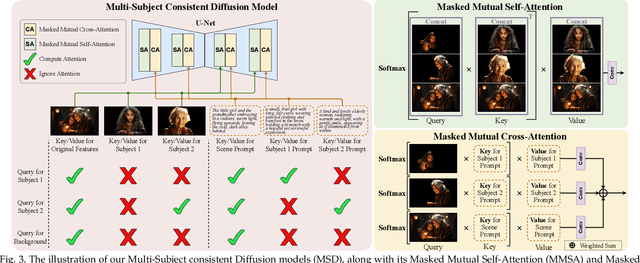
Story visualization aims to create visually compelling images or videos corresponding to textual narratives. Despite recent advances in diffusion models yielding promising results, existing methods still struggle to create a coherent sequence of subject-consistent frames based solely on a story. To this end, we propose DreamStory, an automatic open-domain story visualization framework by leveraging the LLMs and a novel multi-subject consistent diffusion model. DreamStory consists of (1) an LLM acting as a story director and (2) an innovative Multi-Subject consistent Diffusion model (MSD) for generating consistent multi-subject across the images. First, DreamStory employs the LLM to generate descriptive prompts for subjects and scenes aligned with the story, annotating each scene's subjects for subsequent subject-consistent generation. Second, DreamStory utilizes these detailed subject descriptions to create portraits of the subjects, with these portraits and their corresponding textual information serving as multimodal anchors (guidance). Finally, the MSD uses these multimodal anchors to generate story scenes with consistent multi-subject. Specifically, the MSD includes Masked Mutual Self-Attention (MMSA) and Masked Mutual Cross-Attention (MMCA) modules. MMSA and MMCA modules ensure appearance and semantic consistency with reference images and text, respectively. Both modules employ masking mechanisms to prevent subject blending. To validate our approach and promote progress in story visualization, we established a benchmark, DS-500, which can assess the overall performance of the story visualization framework, subject-identification accuracy, and the consistency of the generation model. Extensive experiments validate the effectiveness of DreamStory in both subjective and objective evaluations. Please visit our project homepage at https://dream-xyz.github.io/dreamstory.
MobileVidFactory: Automatic Diffusion-Based Social Media Video Generation for Mobile Devices from Text
Jul 31, 2023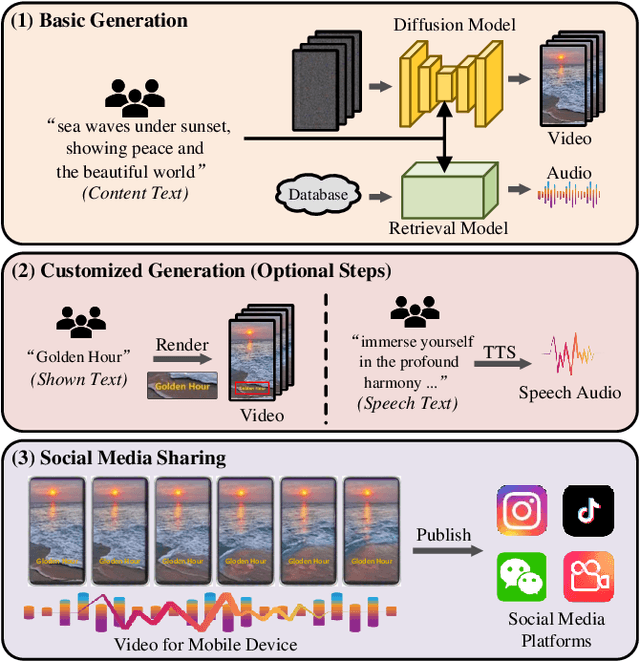

Videos for mobile devices become the most popular access to share and acquire information recently. For the convenience of users' creation, in this paper, we present a system, namely MobileVidFactory, to automatically generate vertical mobile videos where users only need to give simple texts mainly. Our system consists of two parts: basic and customized generation. In the basic generation, we take advantage of the pretrained image diffusion model, and adapt it to a high-quality open-domain vertical video generator for mobile devices. As for the audio, by retrieving from our big database, our system matches a suitable background sound for the video. Additionally to produce customized content, our system allows users to add specified screen texts to the video for enriching visual expression, and specify texts for automatic reading with optional voices as they like.
Learning Profitable NFT Image Diffusions via Multiple Visual-Policy Guided Reinforcement Learning
Jun 20, 2023



We study the task of generating profitable Non-Fungible Token (NFT) images from user-input texts. Recent advances in diffusion models have shown great potential for image generation. However, existing works can fall short in generating visually-pleasing and highly-profitable NFT images, mainly due to the lack of 1) plentiful and fine-grained visual attribute prompts for an NFT image, and 2) effective optimization metrics for generating high-quality NFT images. To solve these challenges, we propose a Diffusion-based generation framework with Multiple Visual-Policies as rewards (i.e., Diffusion-MVP) for NFT images. The proposed framework consists of a large language model (LLM), a diffusion-based image generator, and a series of visual rewards by design. First, the LLM enhances a basic human input (such as "panda") by generating more comprehensive NFT-style prompts that include specific visual attributes, such as "panda with Ninja style and green background." Second, the diffusion-based image generator is fine-tuned using a large-scale NFT dataset to capture fine-grained image styles and accessory compositions of popular NFT elements. Third, we further propose to utilize multiple visual-policies as optimization goals, including visual rarity levels, visual aesthetic scores, and CLIP-based text-image relevances. This design ensures that our proposed Diffusion-MVP is capable of minting NFT images with high visual quality and market value. To facilitate this research, we have collected the largest publicly available NFT image dataset to date, consisting of 1.5 million high-quality images with corresponding texts and market values. Extensive experiments including objective evaluations and user studies demonstrate that our framework can generate NFT images showing more visually engaging elements and higher market value, compared with SOTA approaches.
MovieFactory: Automatic Movie Creation from Text using Large Generative Models for Language and Images
Jun 12, 2023In this paper, we present MovieFactory, a powerful framework to generate cinematic-picture (3072$\times$1280), film-style (multi-scene), and multi-modality (sounding) movies on the demand of natural languages. As the first fully automated movie generation model to the best of our knowledge, our approach empowers users to create captivating movies with smooth transitions using simple text inputs, surpassing existing methods that produce soundless videos limited to a single scene of modest quality. To facilitate this distinctive functionality, we leverage ChatGPT to expand user-provided text into detailed sequential scripts for movie generation. Then we bring scripts to life visually and acoustically through vision generation and audio retrieval. To generate videos, we extend the capabilities of a pretrained text-to-image diffusion model through a two-stage process. Firstly, we employ spatial finetuning to bridge the gap between the pretrained image model and the new video dataset. Subsequently, we introduce temporal learning to capture object motion. In terms of audio, we leverage sophisticated retrieval models to select and align audio elements that correspond to the plot and visual content of the movie. Extensive experiments demonstrate that our MovieFactory produces movies with realistic visuals, diverse scenes, and seamlessly fitting audio, offering users a novel and immersive experience. Generated samples can be found in YouTube or Bilibili (1080P).
VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation
May 18, 2023



We present VideoFactory, an innovative framework for generating high-quality open-domain videos. VideoFactory excels in producing high-definition (1376x768), widescreen (16:9) videos without watermarks, creating an engaging user experience. Generating videos guided by text instructions poses significant challenges, such as modeling the complex relationship between space and time, and the lack of large-scale text-video paired data. Previous approaches extend pretrained text-to-image generation models by adding temporal 1D convolution/attention modules for video generation. However, these approaches overlook the importance of jointly modeling space and time, inevitably leading to temporal distortions and misalignment between texts and videos. In this paper, we propose a novel approach that strengthens the interaction between spatial and temporal perceptions. In particular, we utilize a swapped cross-attention mechanism in 3D windows that alternates the "query" role between spatial and temporal blocks, enabling mutual reinforcement for each other. To fully unlock model capabilities for high-quality video generation, we curate a large-scale video dataset called HD-VG-130M. This dataset comprises 130 million text-video pairs from the open-domain, ensuring high-definition, widescreen and watermark-free characters. Objective metrics and user studies demonstrate the superiority of our approach in terms of per-frame quality, temporal correlation, and text-video alignment, with clear margins.
MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
Dec 19, 2022We propose the first joint audio-video generation framework that brings engaging watching and listening experiences simultaneously, towards high-quality realistic videos. To generate joint audio-video pairs, we propose a novel Multi-Modal Diffusion model (i.e., MM-Diffusion), with two-coupled denoising autoencoders. In contrast to existing single-modal diffusion models, MM-Diffusion consists of a sequential multi-modal U-Net for a joint denoising process by design. Two subnets for audio and video learn to gradually generate aligned audio-video pairs from Gaussian noises. To ensure semantic consistency across modalities, we propose a novel random-shift based attention block bridging over the two subnets, which enables efficient cross-modal alignment, and thus reinforces the audio-video fidelity for each other. Extensive experiments show superior results in unconditional audio-video generation, and zero-shot conditional tasks (e.g., video-to-audio). In particular, we achieve the best FVD and FAD on Landscape and AIST++ dancing datasets. Turing tests of 10k votes further demonstrate dominant preferences for our model. The code and pre-trained models can be downloaded at https://github.com/researchmm/MM-Diffusion.