 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Model For All: Partial Diffusion for Unified Try-On and Try-Off in Any Pose
Aug 06, 2025Recent diffusion-based approaches have made significant advances in image-based virtual try-on, enabling more realistic and end-to-end garment synthesis. However, most existing methods remain constrained by their reliance on exhibition garments and segmentation masks, as well as their limited ability to handle flexible pose variations. These limitations reduce their practicality in real-world scenarios-for instance, users cannot easily transfer garments worn by one person onto another, and the generated try-on results are typically restricted to the same pose as the reference image. In this paper, we introduce \textbf{OMFA} (\emph{One Model For All}), a unified diffusion framework for both virtual try-on and try-off that operates without the need for exhibition garments and supports arbitrary poses. For example, OMFA enables removing garments from a source person (try-off) and transferring them onto a target person (try-on), while also allowing the generated target to appear in novel poses-even without access to multi-pose images of that person. OMFA is built upon a novel \emph{partial diffusion} strategy that selectively applies noise and denoising to individual components of the joint input-such as the garment, the person image, or the face-enabling dynamic subtask control and efficient bidirectional garment-person transformation. The framework is entirely mask-free and requires only a single portrait and a target pose as input, making it well-suited for real-world applications. Additionally, by leveraging SMPL-X-based pose conditioning, OMFA supports multi-view and arbitrary-pose try-on from just one image. Extensive experiments demonstrate that OMFA achieves state-of-the-art results on both try-on and try-off tasks, providing a practical and generalizable solution for virtual garment synthesis. The project page is here: https://onemodelforall.github.io/.
HMVLM: Multistage Reasoning-Enhanced Vision-Language Model for Long-Tailed Driving Scenarios
Jun 06, 2025We present HaoMo Vision-Language Model (HMVLM), an end-to-end driving framework that implements the slow branch of a cognitively inspired fast-slow architecture. A fast controller outputs low-level steering, throttle, and brake commands, while a slow planner-a large vision-language model-generates high-level intents such as "yield to pedestrian" or "merge after the truck" without compromising latency. HMVLM introduces three upgrades: (1) selective five-view prompting with an embedded 4s history of ego kinematics, (2) multi-stage chain-of-thought (CoT) prompting that enforces a Scene Understanding -> Driving Decision -> Trajectory Inference reasoning flow, and (3) spline-based trajectory post-processing that removes late-stage jitter and sharp turns. Trained on the Waymo Open Dataset, these upgrades enable HMVLM to achieve a Rater Feedback Score (RFS) of 7.7367, securing 2nd place in the 2025 Waymo Vision-based End-to-End (E2E) Driving Challenge and surpassing the public baseline by 2.77%.
Mod-Adapter: Tuning-Free and Versatile Multi-concept Personalization via Modulation Adapter
May 24, 2025Personalized text-to-image generation aims to synthesize images of user-provided concepts in diverse contexts. Despite recent progress in multi-concept personalization, most are limited to object concepts and struggle to customize abstract concepts (e.g., pose, lighting). Some methods have begun exploring multi-concept personalization supporting abstract concepts, but they require test-time fine-tuning for each new concept, which is time-consuming and prone to overfitting on limited training images. In this work, we propose a novel tuning-free method for multi-concept personalization that can effectively customize both object and abstract concepts without test-time fine-tuning. Our method builds upon the modulation mechanism in pretrained Diffusion Transformers (DiTs) model, leveraging the localized and semantically meaningful properties of the modulation space. Specifically, we propose a novel module, Mod-Adapter, to predict concept-specific modulation direction for the modulation process of concept-related text tokens. It incorporates vision-language cross-attention for extracting concept visual features, and Mixture-of-Experts (MoE) layers that adaptively map the concept features into the modulation space. Furthermore, to mitigate the training difficulty caused by the large gap between the concept image space and the modulation space, we introduce a VLM-guided pretraining strategy that leverages the strong image understanding capabilities of vision-language models to provide semantic supervision signals. For a comprehensive comparison, we extend a standard benchmark by incorporating abstract concepts. Our method achieves state-of-the-art performance in multi-concept personalization, supported by quantitative, qualitative, and human evaluations.
Token-Shuffle: Towards High-Resolution Image Generation with Autoregressive Models
Apr 24, 2025Autoregressive (AR) models, long dominant in language generation, are increasingly applied to image synthesis but are often considered less competitive than Diffusion-based models. A primary limitation is the substantial number of image tokens required for AR models, which constrains both training and inference efficiency, as well as image resolution. To address this, we present Token-Shuffle, a novel yet simple method that reduces the number of image tokens in Transformer. Our key insight is the dimensional redundancy of visual vocabularies in Multimodal Large Language Models (MLLMs), where low-dimensional visual codes from visual encoder are directly mapped to high-dimensional language vocabularies. Leveraging this, we consider two key operations: token-shuffle, which merges spatially local tokens along channel dimension to decrease the input token number, and token-unshuffle, which untangles the inferred tokens after Transformer blocks to restore the spatial arrangement for output. Jointly training with textual prompts, our strategy requires no additional pretrained text-encoder and enables MLLMs to support extremely high-resolution image synthesis in a unified next-token prediction way while maintaining efficient training and inference. For the first time, we push the boundary of AR text-to-image generation to a resolution of 2048x2048 with gratifying generation performance. In GenAI-benchmark, our 2.7B model achieves 0.77 overall score on hard prompts, outperforming AR models LlamaGen by 0.18 and diffusion models LDM by 0.15. Exhaustive large-scale human evaluations also demonstrate our prominent image generation ability in terms of text-alignment, visual flaw, and visual appearance. We hope that Token-Shuffle can serve as a foundational design for efficient high-resolution image generation within MLLMs.
VTON 360: High-Fidelity Virtual Try-On from Any Viewing Direction
Mar 15, 2025Virtual Try-On (VTON) is a transformative technology in e-commerce and fashion design, enabling realistic digital visualization of clothing on individuals. In this work, we propose VTON 360, a novel 3D VTON method that addresses the open challenge of achieving high-fidelity VTON that supports any-view rendering. Specifically, we leverage the equivalence between a 3D model and its rendered multi-view 2D images, and reformulate 3D VTON as an extension of 2D VTON that ensures 3D consistent results across multiple views. To achieve this, we extend 2D VTON models to include multi-view garments and clothing-agnostic human body images as input, and propose several novel techniques to enhance them, including: i) a pseudo-3D pose representation using normal maps derived from the SMPL-X 3D human model, ii) a multi-view spatial attention mechanism that models the correlations between features from different viewing angles, and iii) a multi-view CLIP embedding that enhances the garment CLIP features used in 2D VTON with camera information. Extensive experiments on large-scale real datasets and clothing images from e-commerce platforms demonstrate the effectiveness of our approach. Project page: https://scnuhealthy.github.io/VTON360.
Cognify: Supercharging Gen-AI Workflows With Hierarchical Autotuning
Feb 12, 2025



Today's gen-AI workflows that involve multiple ML model calls, tool/API calls, data retrieval, or generic code execution are often tuned manually in an ad-hoc way that is both time-consuming and error-prone. In this paper, we propose a systematic approach for automatically tuning gen-AI workflows. Our key insight is that gen-AI workflows can benefit from structure, operator, and prompt changes, but unique properties of gen-AI workflows require new optimization techniques. We propose AdaSeek, an adaptive hierarchical search algorithm for autotuning gen-AI workflows. AdaSeek organizes workflow tuning methods into different layers based on the user-specified total search budget and distributes the budget across different layers based on the complexity of each layer. During its hierarchical search, AdaSeek redistributes the search budget from less useful to more promising tuning configurations based on workflow-level evaluation results. We implement AdaSeek in a workflow autotuning framework called Cognify and evaluate Cognify using six types of workflows such as RAG-based QA and text-to-SQL transformation. Overall, Cognify improves these workflows' generation quality by up to 2.8x, reduces execution monetary cost by up to 10x, and reduces end-to-end latency by 2.7x.
Comprehensive Performance Evaluation of YOLOv11, YOLOv10, YOLOv9, YOLOv8 and YOLOv5 on Object Detection of Power Equipment
Nov 28, 2024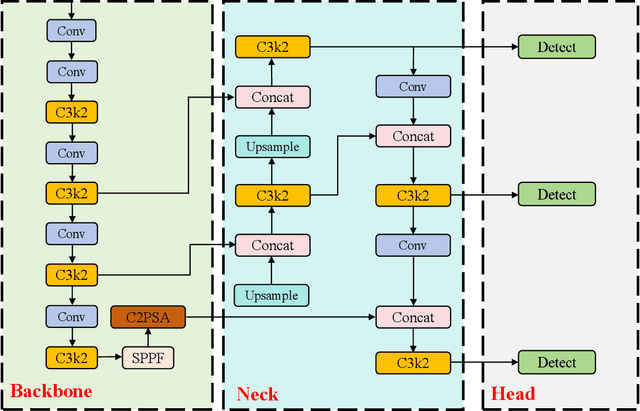


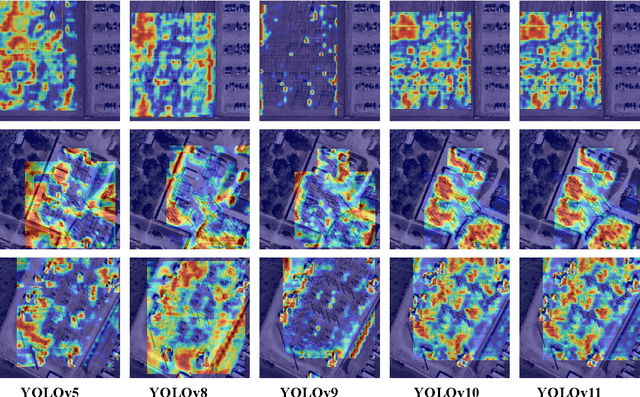
With the rapid development of global industrial production, the demand for reliability in power equipment has been continuously increasing. Ensuring the stability of power system operations requires accurate methods to detect potential faults in power equipment, thereby guaranteeing the normal supply of electrical energy. In this article, the performance of YOLOv5, YOLOv8, YOLOv9, YOLOv10, and the state-of-the-art YOLOv11 methods was comprehensively evaluated for power equipment object detection. Experimental results demonstrate that the mean average precision (mAP) on a public dataset for power equipment was 54.4%, 55.5%, 43.8%, 48.0%, and 57.2%, respectively, with the YOLOv11 achieving the highest detection performance. Moreover, the YOLOv11 outperformed other methods in terms of recall rate and exhibited superior performance in reducing false detections. In conclusion, the findings indicate that the YOLOv11 model provides a reliable and effective solution for power equipment object detection, representing a promising approach to enhancing the operational reliability of power systems.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Pixel-Space Post-Training of Latent Diffusion Models
Sep 26, 2024



Latent diffusion models (LDMs) have made significant advancements in the field of image generation in recent years. One major advantage of LDMs is their ability to operate in a compressed latent space, allowing for more efficient training and deployment. However, despite these advantages, challenges with LDMs still remain. For example, it has been observed that LDMs often generate high-frequency details and complex compositions imperfectly. We hypothesize that one reason for these flaws is due to the fact that all pre- and post-training of LDMs are done in latent space, which is typically $8 \times 8$ lower spatial-resolution than the output images. To address this issue, we propose adding pixel-space supervision in the post-training process to better preserve high-frequency details. Experimentally, we show that adding a pixel-space objective significantly improves both supervised quality fine-tuning and preference-based post-training by a large margin on a state-of-the-art DiT transformer and U-Net diffusion models in both visual quality and visual flaw metrics, while maintaining the same text alignment quality.
Time-Varying Foot-Placement Control for Underactuated Humanoid Walking on Swaying Rigid Surfaces
Sep 12, 2024Locomotion on dynamic rigid surface (i.e., rigid surface accelerating in an inertial frame) presents complex challenges for controller design, which are essential for deploying humanoid robots in dynamic real-world environments such as moving trains, ships, and airplanes. This paper introduces a real-time, provably stabilizing control approach for underactuated humanoid walking on periodically swaying rigid surface. The first key contribution is the analytical extension of the classical angular momentum-based linear inverted pendulum model from static to swaying grounds. This extension results in a time-varying, nonhomogeneous robot model, which is fundamentally different from the existing pendulum models. We synthesize a discrete footstep control law for the model and derive a new set of sufficient stability conditions that verify the controller's stabilizing effect. Another key contribution is the development of a hierarchical control framework that incorporates the proposed footstep control law as its higher-layer planner to ensure the stability of underactuated walking. The closed-loop stability of the complete hybrid, full-order robot dynamics under this control framework is provably analyzed based on nonlinear control theory. Finally, experiments conducted on a Digit humanoid robot, both in simulations and with hardware, demonstrate the framework's effectiveness in addressing underactuated bipedal locomotion on swaying ground, even in the presence of uncertain surface motions and unknown external pushes.