 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeat the long tail: Distribution-Aware Speculative Decoding for RL Training
Nov 17, 2025Reinforcement learning(RL) post-training has become essential for aligning large language models (LLMs), yet its efficiency is increasingly constrained by the rollout phase, where long trajectories are generated token by token. We identify a major bottleneck:the long-tail distribution of rollout lengths, where a small fraction of long generations dominates wall clock time and a complementary opportunity; the availability of historical rollouts that reveal stable prompt level patterns across training epochs. Motivated by these observations, we propose DAS, a Distribution Aware Speculative decoding framework that accelerates RL rollouts without altering model outputs. DAS integrates two key ideas: an adaptive, nonparametric drafter built from recent rollouts using an incrementally maintained suffix tree, and a length aware speculation policy that allocates more aggressive draft budgets to long trajectories that dominate makespan. This design exploits rollout history to sustain acceptance while balancing base and token level costs during decoding. Experiments on math and code reasoning tasks show that DAS reduces rollout time up to 50% while preserving identical training curves, demonstrating that distribution-aware speculative decoding can significantly accelerate RL post training without compromising learning quality.
Cognify: Supercharging Gen-AI Workflows With Hierarchical Autotuning
Feb 12, 2025



Today's gen-AI workflows that involve multiple ML model calls, tool/API calls, data retrieval, or generic code execution are often tuned manually in an ad-hoc way that is both time-consuming and error-prone. In this paper, we propose a systematic approach for automatically tuning gen-AI workflows. Our key insight is that gen-AI workflows can benefit from structure, operator, and prompt changes, but unique properties of gen-AI workflows require new optimization techniques. We propose AdaSeek, an adaptive hierarchical search algorithm for autotuning gen-AI workflows. AdaSeek organizes workflow tuning methods into different layers based on the user-specified total search budget and distributes the budget across different layers based on the complexity of each layer. During its hierarchical search, AdaSeek redistributes the search budget from less useful to more promising tuning configurations based on workflow-level evaluation results. We implement AdaSeek in a workflow autotuning framework called Cognify and evaluate Cognify using six types of workflows such as RAG-based QA and text-to-SQL transformation. Overall, Cognify improves these workflows' generation quality by up to 2.8x, reduces execution monetary cost by up to 10x, and reduces end-to-end latency by 2.7x.
APIServe: Efficient API Support for Large-Language Model Inferencing
Feb 02, 2024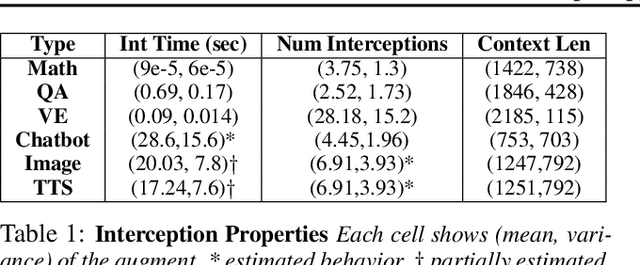
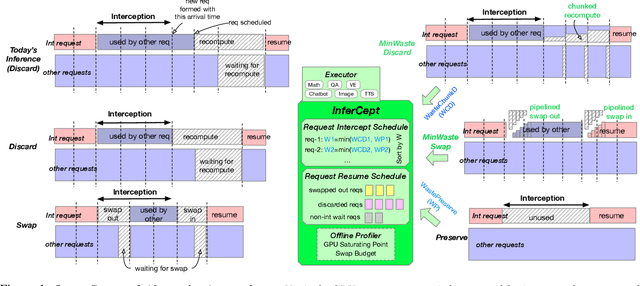
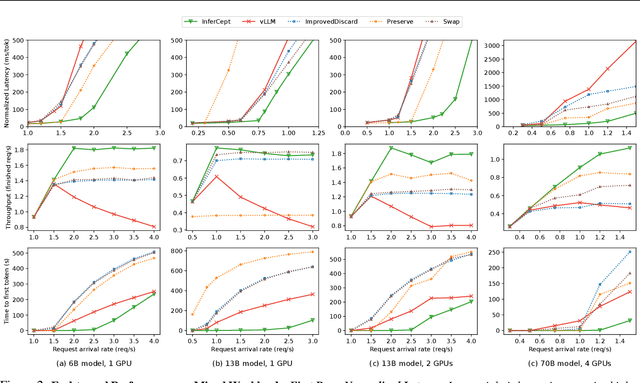
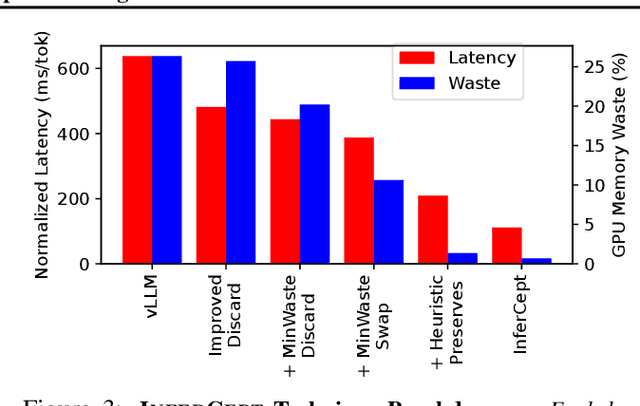
Large language models are increasingly integrated with external tools and APIs like ChatGPT plugins to extend their capability beyond language-centric tasks. However, today's LLM inference systems are designed for standalone LLMs. They treat API calls as new requests, causing unnecessary recomputation of already computed contexts, which accounts for 37-40% of total model forwarding time. This paper presents APIServe, the first LLM inference framework targeting API-augmented LLMs. APISERVE minimizes the GPU resource waste caused by API calls and dedicates saved memory for serving more requests. APISERVE improves the overall serving throughput by 1.6x and completes 2x more requests per second compared to the state-of-the-art LLM inference systems.
The Effect of Model Size on Worst-Group Generalization
Dec 08, 2021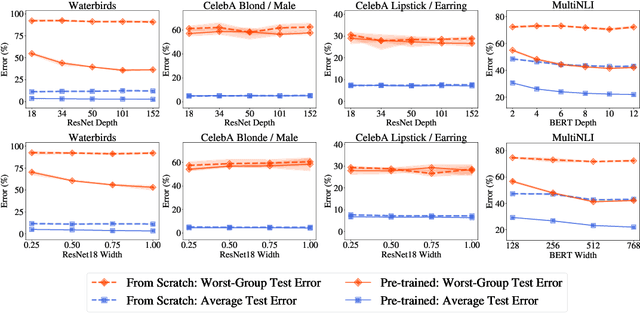
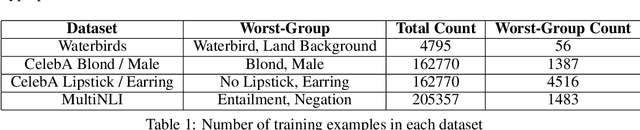
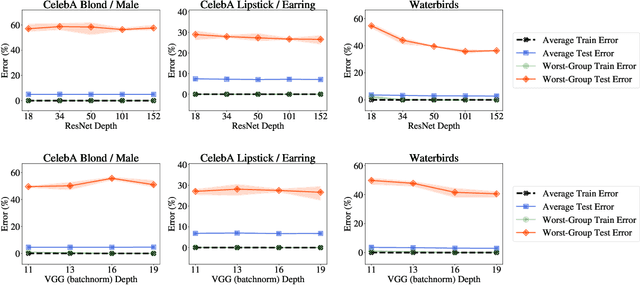

Overparameterization is shown to result in poor test accuracy on rare subgroups under a variety of settings where subgroup information is known. To gain a more complete picture, we consider the case where subgroup information is unknown. We investigate the effect of model size on worst-group generalization under empirical risk minimization (ERM) across a wide range of settings, varying: 1) architectures (ResNet, VGG, or BERT), 2) domains (vision or natural language processing), 3) model size (width or depth), and 4) initialization (with pre-trained or random weights). Our systematic evaluation reveals that increasing model size does not hurt, and may help, worst-group test performance under ERM across all setups. In particular, increasing pre-trained model size consistently improves performance on Waterbirds and MultiNLI. We advise practitioners to use larger pre-trained models when subgroup labels are unknown.