 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Bias: Data Poisoning Attacks on Fairness
Nov 11, 2025With the growing adoption of AI and machine learning systems in real-world applications, ensuring their fairness has become increasingly critical. The majority of the work in algorithmic fairness focus on assessing and improving the fairness of machine learning systems. There is relatively little research on fairness vulnerability, i.e., how an AI system's fairness can be intentionally compromised. In this work, we first provide a theoretical analysis demonstrating that a simple adversarial poisoning strategy is sufficient to induce maximally unfair behavior in naive Bayes classifiers. Our key idea is to strategically inject a small fraction of carefully crafted adversarial data points into the training set, biasing the model's decision boundary to disproportionately affect a protected group while preserving generalizable performance. To illustrate the practical effectiveness of our method, we conduct experiments across several benchmark datasets and models. We find that our attack significantly outperforms existing methods in degrading fairness metrics across multiple models and datasets, often achieving substantially higher levels of unfairness with a comparable or only slightly worse impact on accuracy. Notably, our method proves effective on a wide range of models, in contrast to prior work, demonstrating a robust and potent approach to compromising the fairness of machine learning systems.
Ensuring User-side Fairness in Dynamic Recommender Systems
Aug 29, 2023User-side group fairness is crucial for modern recommender systems, as it aims to alleviate performance disparity between groups of users defined by sensitive attributes such as gender, race, or age. We find that the disparity tends to persist or even increase over time. This calls for effective ways to address user-side fairness in a dynamic environment, which has been infrequently explored in the literature. However, fairness-constrained re-ranking, a typical method to ensure user-side fairness (i.e., reducing performance disparity), faces two fundamental challenges in the dynamic setting: (1) non-differentiability of the ranking-based fairness constraint, which hinders the end-to-end training paradigm, and (2) time-inefficiency, which impedes quick adaptation to changes in user preferences. In this paper, we propose FAir Dynamic rEcommender (FADE), an end-to-end framework with fine-tuning strategy to dynamically alleviate performance disparity. To tackle the above challenges, FADE uses a novel fairness loss designed to be differentiable and lightweight to fine-tune model parameters to ensure both user-side fairness and high-quality recommendations. Via extensive experiments on the real-world dataset, we empirically demonstrate that FADE effectively and efficiently reduces performance disparity, and furthermore, FADE improves overall recommendation quality over time compared to not using any new data.
The Effect of Model Size on Worst-Group Generalization
Dec 08, 2021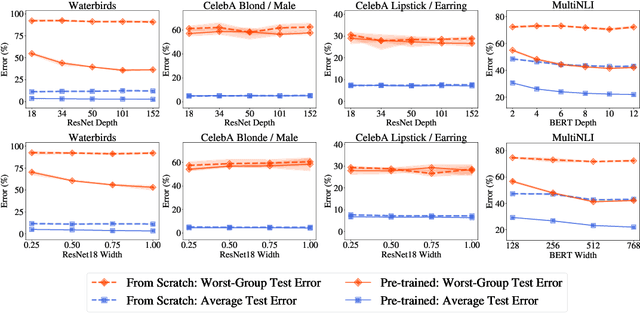
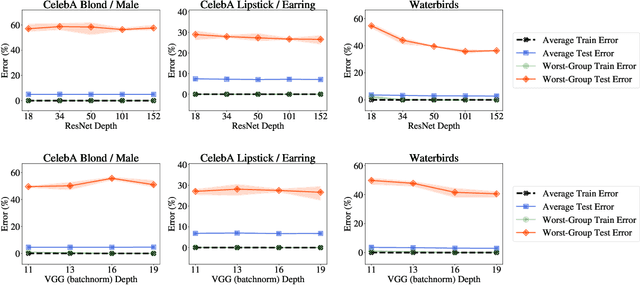

Overparameterization is shown to result in poor test accuracy on rare subgroups under a variety of settings where subgroup information is known. To gain a more complete picture, we consider the case where subgroup information is unknown. We investigate the effect of model size on worst-group generalization under empirical risk minimization (ERM) across a wide range of settings, varying: 1) architectures (ResNet, VGG, or BERT), 2) domains (vision or natural language processing), 3) model size (width or depth), and 4) initialization (with pre-trained or random weights). Our systematic evaluation reveals that increasing model size does not hurt, and may help, worst-group test performance under ERM across all setups. In particular, increasing pre-trained model size consistently improves performance on Waterbirds and MultiNLI. We advise practitioners to use larger pre-trained models when subgroup labels are unknown.